来源知乎:CPU的分支预测器是如何工作的?
在CPU中的分支预测器是具体在哪个位置?形态大概是怎样的?它是怎么起到作用的?如果预测失败它又是怎样绕过已经失败的预测从而增加重新预测的成功率的?小编综合收集的资料一一回答这些问题。
1.位置:
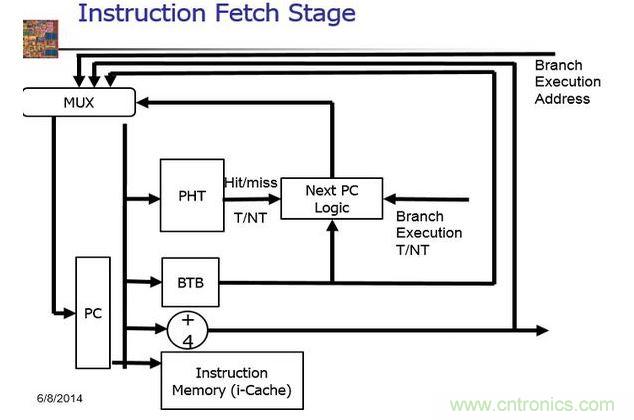
分支预测器位于整个CPU核心流水线的差不多最前端部分,也就是靠近一级指令缓存的位置。从指令缓存里面读取指令时,需要由分支预测器来判断从哪里读取。
2.形态:
分支预测器主要由两个大块组成(教科书上有可能不是这样分),其中一块是历史记录表,记录以往执行过的分支指令的偏向情况,帮助未来的预测,本质上也是一块高速缓存。另一块是预测器的逻辑部分,这一部分用来维护记录表,依据记录表里面的记录情况预测将来的分支走向。
3.预测方法举例。
比如说有一条分支指令,执行了十几次都是跳转,那么预测器就会判断,将来碰到这条指令时,它仍旧会跳转。当这条指令的预测结果连续两次出错的时候,预测器就会调整自己的预测结果,改为判断它不跳转。这一预测方法是现今仍在沿用的2-bit计数器阵列,源于前CDC公司的JamesSmith(现为WISC-Madison的荣誉教授)在上世纪80年代初左右的发明,实测结果表明它的预测准确率基本上能到80%甚至90%上下。
4.后记:
到了九十年代初期,这个圈子里一个叫做YalePatt的大牌教授引领了几乎十年的分支预测研究浪潮,他们做的预测器比JamesSmith的先进很多,被称为自适应预测,可以捕捉住更多的分支历史模式。(在Patt手下做预测的那个博士生Tse-YuYeh后来参加一个学术会议,Intel的人看到了他们做的东西,直接把人给挖走了,那个预测器用在了P6微结构里面,后来Tse-YuYeh离开Intel到了PASemi,现在好像是在Apple的CPU设计团队。)后来又有很多人加入进来做分支预测的研究,做出了关联性分支预测、返回栈预测等等非常棒的预测器,现在的分支预测器结构通常是竞标赛式的复合分支预测器,比如当关联性分支预测器的近期准确率比较高时,优先采用它,如果有其他预测器的近期准确率更高,就放弃它。后来的研究越来越精细,针对分支预测做了很多很多的调优,比如说如何在有限的空间里面尽可能减少大量分支指令对历史记录表的争抢、尝试对分支指令进行分类,每一类使用专门的预测器进行预测等等,现在的分支预测器非常强大,面对各种各样的程序,预测准确率都能非常坚挺地保持在95%以上。微结构上的推测执行技术有很多种,分支预测引领的控制流相关的推测执行可能是其中最成功的一种。
附:分支预测图解,从简单到最复杂的:
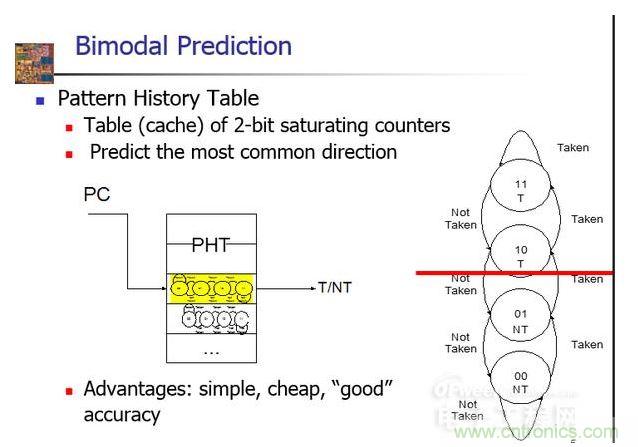
这个是最简单的分支预测,根据当前指令的地址,放进PHT中,根据右边的这张状态机,来确定是跳转还是不跳转。优势:简单,具有相当的准确性。
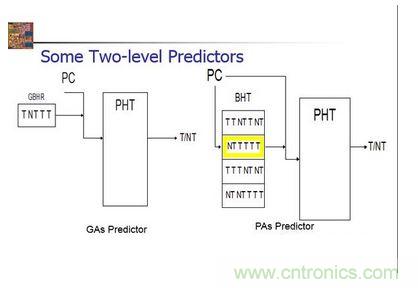
两级预测这个预测机构比较复杂,拥有两级分支,相比之前的方法,加入了BHT,可以根据指令地址,记录一部分历史记录,然后再放进PHT中,决定跳转还是不跳转。优点在于可以记录下某一些跳转的关系,加强联系。
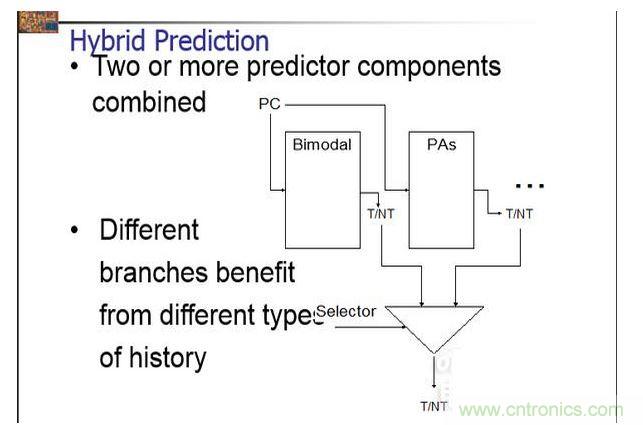
混合预测,集合了上面两个的优点,加上自己设定的选择器。可以方便的看到,基本上所有的预测机制都是通过以往的历史记录来加强或者削弱跳转关系。第一种方法很直接,用一个状态机来描述了整个机制。第二个方法甚至在第一个的基础上记录了N多个跳转的记录。判断出是否跳转之后,CPU需要知道跳转到哪里,因为不是每次跳转的位置都是一样的。所以在预测的基础上又加上了BTB整个东西,这个东西记录了之前跳转的地址,因此CPU可以不计算跳转的地址,直接预先load指令,如果出错的话,将会刷新BTB,并且flush所有指令,重新load。
BTB的结构如下:

BTB的工作方式如下:

那么如果将这些所有的东西结合到CPU的流水线上,将会变成如下的流程: