基于人工智能技术快速构建三维模型 译文 精选
译者 |?朱先忠
审校 |?孙淑娟

图1:封面
生成三维模型可能很耗时,或者需要大量参考图像。解决这个问题的一种方法是借助神经辐射场(neural radiance field,简称“NeRF”),这是一种生成图像的人工智能方法。NERF的主要思想是:先获取一小组您拍摄的对象或场景的2D图像,然后使用这些2D图像来有效地构建3D表示。这是通过学习在已有图像之间的转换来实现的。现在,这种跳跃(也称作“插值”)技术能够帮助您创建物体新视角下的图像!
听起来不错,对吗?借助于一小组图像,你就可以制作一个3D模型!这比标准摄影测量效果要好,因为标准摄影测量需要一个巨大的图像库来生成一些图片(你需要每个角度的镜头)。然而,NVIDIA公司一开始确实承诺说NeRFs速度很快;但是,直到最近情况还不是这样。以前,NeRFs往往会花费很长时间来学习如何将一组图像集转换为3D模型。
但如今,情况不再如此。最近,NVIDIA公司开发出了一种即时NeRF软件,该软件能够利用GPU硬件运行必要的复杂计算。这种方法将创建模型所需的时间从几天减少到几秒钟!NVIDIA对instant-ngp软件的可用性和速度提出了许多令人兴奋的主张。而且,他们提供的结果和示例也给人留下深刻的印象:

图2:NeRF图像展示——NVIDIA拥有一个酷炫的机器人实验室
我觉得很难不被这个演示打动——它看起来太棒了!于是,我想看看把它转移到我自己的图像上并生成我自己的NeRF模型有多么容易。所以,我决定自己安装并使用一下这款软件。在本文中,我将介绍我的试验体验,并详细介绍我制作的模型!
主要任务划分
那我们该怎么办?大致阶段性任务划分如下:
- 首先,我们需要引用一些连续镜头。让我们去录制一些我们想要3D化的视频!
- 然后,我们开始场景拍摄,并将拍摄的视频转换成多幅静止图像。
- 我们将上面获取的连续图像数据传递到instant-ngp。然后,训练人工智能来理解我们生成的图像之间的空间。这实际上与制作三维模型相同。
- 最后,我们想创建一个展示我们的创作成果的视频!在NVIDIA开发的软件中,我们将绘制一条路径,让摄像机带我们参观我们制作的模型,然后渲染视频。
我不会深入讨论这一切是如何运作的,但我会提供我发现有用的很多资源的链接。所以,接下来,我将专注于我制作的视频,以及我在旅途中偶然发现的一些小知识。
开始我的试验
NVIDIA公司的即时NeRF软件并不容易安装。虽然软件的说明很清楚,但我觉得当涉及到个人需要的特定软件版本时,说明中要求的部分所提供的回旋余地并不大。对我来说,使用CUDA 11.7或VS2022似乎是不可能的,但我认为正是切换回CUDA 11.6版本和VS2019才最终促进了安装成功。其中,我遇到很多错误,比如“CUDA_ARCHITECTURES is empty for target”,等等。这是因为CUDA与Visual Studio配合并不友好所导致。因此,我真诚地推荐有兴趣的读者参考??视频???以及Github上的??仓库资源??,以便进一步帮助你顺利地做好一切设置工作!
除此之外,这一过程算是进展顺利。官方还提供了Python脚本,用于帮助指导将拍摄的视频转换为图像,以及随后将其转换为模型和视频的步骤。
试验1:乐高小汽车
起初,我试图在办公室里把一辆小乐高汽车NeRF化。我觉得我的摄影技巧远远不够,因为我根本无法创作出任何有意义的图像。只是一个奇怪的3D污点而已。算了,还是让我们看一看NVIDIA提供给我们的一个例子吧。请注意图中摄像机的位置:
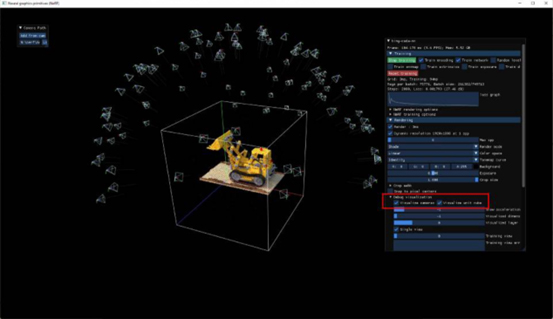
图3:NVIDIA提供的挖掘机默认NeRF模型的“摄像头”位置
一个能够很好地进行训练的准备设置之一就是在场景中放置如上图所述的“摄像机”。这些摄像机是软件认为你在拍摄视频时所面对的角度。它应该是一个漂亮的圆圈。当然,我的第一辆乐高车根本不是这个样子的,而是一个被压扁的半圆。
试验2:稍大点的乐高小汽车
为了从第一次试验中学习,我找到了一张可以完全走动的桌子,并找到了一辆更大的乐高车。我试着确保我抓拍的时间也比以前长。最后,我从各个角度拍摄了1分钟流畅的视频。我训练模型的时间总共不到30秒。在720p下渲染4小时后,下图是我制作的视频:

图4:我的第二个NeRF模型——一部乐高技术车!
试验3:植物
结果证明上面的试验2更好一些了,至少在技术上可行。然而,还是存在一团奇怪的雾,当然这还不算是超级麻烦。在我的下一次试验中,我也试着从更远的背面拍摄(我假设雾是由人工智能对那里的东西感到“困惑”引起的)。我试图更多地控制aabc_scale参数(该参数用于衡量场景有多大),然后对其进行几分钟的训练。渲染最后,得到如下所示的视频结果:

图5:我用客厅桌子上的一棵植物做成的一个NeRF模型
好多了!令人印象深刻的是,它是如何将钩针植物盆子、木头上的凹槽以及树叶的复杂性表现得如此精确的。看看摄像机在树叶上做的俯冲动作吧!
试验4:
现在,我们的试验效果越来越好了!然而,我想要一个室外的视频。我在公寓外拍摄了不到2分钟的视频,并开始处理。这对于渲染/训练来说尤其笨重。我在这里的猜测是,我的aabc_scale值相当高(8),因此渲染“光线”必须走得很远(即,我想要渲染的东西数量更多)。于是,我不得不切换到480p,并将渲染FPS从30降低到10。事实表明,设置参数的选择确实会影响渲染时间。经过8个小时的渲染,我完成了以下操作:

图6:一个我在公寓外面使用的NeRF模型
不过,我认为第三次试验仍然是我最喜欢的。我想我可以把第四次试验做得更好一点。但是,当渲染时间变得很长时,很难遍历各个版本并试验不同的渲染和训练设置。现在甚至设置渲染的摄像机角度都很困难了,这导致我的程序变得极其缓慢。
不过,这真正是一个相当惊人的输出,因为仅仅使用了一两分钟的视频数据。最后,我终于有了一个详细的逼真的三维模型!
利弊分析
我认为最令人印象深刻的是,在1-2分钟的拍摄时间内,完全没有受过摄影测量训练的人(我)可以创建一个可行的3D模型。该过程的确需要一些技术诀窍,但一旦你把所有设备都安装好了,也就很容易使用了。使用Python脚本将视频转换为图像效果很好。一旦这些都做了,输入到人工智能就会顺利进行。
然而,尽管很难因这一方面而指责英伟达,但我觉得我还是应该提出来:这件事需要一个相当强大的GPU。我的笔记本电脑里有一个T500,这项任务简直把它推到了绝对极限。训练时间确实比宣传的5秒钟时间长得多,尝试在1080p情况下渲染时会导致程序崩溃(我是选择在135*74指标左右动态渲染的)。现在,这仍然算是一个巨大的改进,因为以前的NeRF模型实验花费了好几天时间。
我不认为每个人都会有一个3090p设备用于这样的项目,所以值得简要说明一下。低性能配置的电脑使程序难以使用,尤其是当我试图让摄像机“飞起来”以便更有利于设置渲染视频时。尽管如此,这一过程的成果还是让人印象深刻。
还有,我面临的另一个问题是无法寻找渲染文件render.py(正如您可能猜测的那样,它对于渲染视频至关重要)。非常奇怪的是,它不在官方提供的开源代码仓库中,尽管在大多数广告文章和其他文件中都有大量提及。因此,我必须从链接处https://github.com/bycloudai/instant-ngp-Windows挖出这个宝贝。
最后,我也希望能够把上面的3D模型转换成.obj文件。也许现在,这已经成为可能的事了。
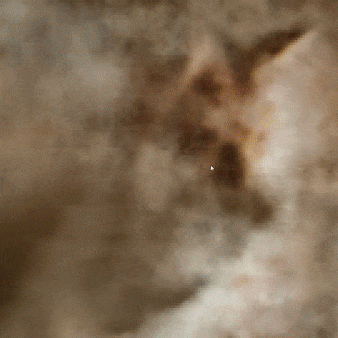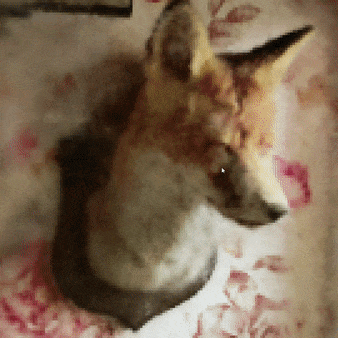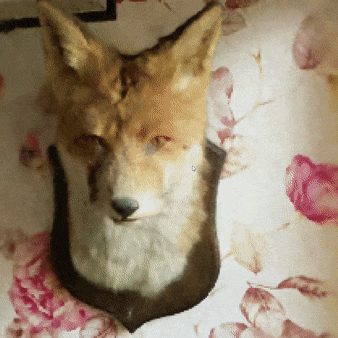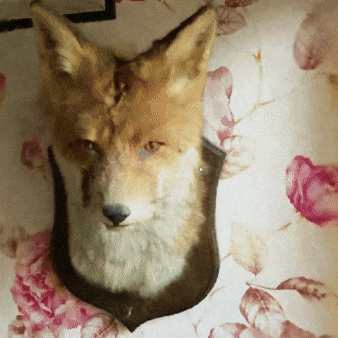
图7:一只狐狸的gif动画——这不是我做的,是英伟达做的。效果不错,对不?
总结和下一步的想法
上面的实验过程让我一下联想到OpenAI公司开发的??DALL-E??,这也是一种能够产生图像的人工智能技术。现在,这种技术已经变得非常流行,部分原因在于它非常容易访问。此外,DALL-E展示给人们一个非常酷的例子,说明人工智能模型可以做什么,以及它们的局限性。它如今甚至已经成为了一种流行的文化现象(或者至少在我的推特上就体现了很多特色内容)——人们制作自己各自奇怪的DALL-E图片并相互分享。我可以想象这种技术也会发生类似这样的事情:一个可以让任何人上传视频并创建一个可以与朋友分享的3D模型的网站,其病毒传播的潜力是巨大的。最终有人肯定会做到这一点!
就我个人而言,我期待着这方面更多的实验成果。我希望能够生成超逼真的模型,然后将它们转储到AR/VR中。基于这些技术,你甚至可以主持网络会议——那不是很有趣吗?因为你仅需要借助手机上的摄像头即可实现这一目标,而如今大部分用户手机中已经拥有了这种硬件配置。
总地来说,我印象深刻。能够在手机上录制1分钟的视频,并将其转换为一个你可以逐步通过的模型,这真是太棒了。虽然渲染需要一段时间,而且安装有点困难,但效果很好。经过几次试验,我已经得到了非常酷的输出!我期待着更多的实验!
参考资料
??NVIDIA Git??
??NVIDIA blog??
??Supplemental Git??
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
原文标题:??Using AI to Generate 3D Models, Fast!??,作者:Andrew Blance
