3D 堆叠 CMOS 将摩尔定律推向新高度
本文编译自IEEE,作者为英特尔组件研究小组的研究员兼器件与集成副总裁Jack Kavalieros以及英特尔组件研究小组首席工程师Marko Radosavljevic
在本文中,英特尔详细介绍了其最新的RobbinFET技术,以及更多关于3D堆叠CMOS的技术前景,以下为文章详情。
在过去的 50 年中,影响最深远的技术成就或许就是芯片的进步,不断朝向更小的晶体管稳步迈进,它们更紧密的结合,并且以更低功耗运行。然而,自从 20 多年前我们两人在英特尔开始了我们的职业生涯以来,我们就一直在听到警报,即更小的缩微即将结束。然而,年复一年,出色的新创新继续推动半导体行业进一步发展。
在此过程中,我们的工程师不得不改变晶体管的架构,因为我们在提高性能的同时继续缩小面积和功耗。从 20 世纪下半叶一直到21世纪初,“平面”晶体管一直是市场的绝对主流,而在 2010 年代,开始让位于FinFET。现在,一种新的环栅结构 (GAA) 即将投入生产。但我们必须看得更远,因为即使是这种新的晶体管架构(我们称之为 RibbonFET),其缩小尺寸的能力也有局限性。
未来的扩展在哪儿?我们将继续关注第三维度空间。我们已经创建了相互堆叠的实验器件,逻辑缩小了 30% 到 50%。至关重要的是,顶部和底部器件是两种互补类型,NMOS 和 PMOS,它们是过去几十年所有逻辑电路的基础。我们相信这种 3D 堆叠互补金属氧化物半导体 (CMOS) 或 CFET(互补场效应晶体管)将是将摩尔定律延伸到下一个十年的关键。
晶体管的演变
持续创新是摩尔定律的重要基础,但每次改进都需要权衡取舍。要了解这些权衡以及它们如何不可避免地将我们引向 3D 堆叠 CMOS,您需要一些有关晶体管操作的背景知识。
每个MOSFET都具有相同的基本部件:栅极叠层、沟道区、源极和漏极。源极和漏极经过化学掺杂,使它们要么富含电子(n 型),要么富含空穴(p 型)。沟道区具有与源极和漏极相反的掺杂。
在 2011 年之前,用于先进微处理器的平面晶体管结构中,MOSFET 的栅极堆叠位于沟道区正上方,旨在将电场投射到沟道区。向栅极(相对于源极)施加足够大的电压会在沟道区域中形成一层移动电荷载流子,从而允许电流在源极和漏极之间流动。
当我们缩小平面晶体管时,器件物理学家称之为短沟道效应的麻烦成为了主要关注点。基本上,源极和漏极之间的距离变得非常之小,因为栅电极难以耗尽电荷载流子的沟道,以至于电流会在不应该的情况下通过沟道发生泄漏。为了解决这个问题,业界转向了一种完全不同的晶体管架构,称为 FinFET。它将栅极包裹在具有三个侧面的沟道周围,以提供更好的静电控制。
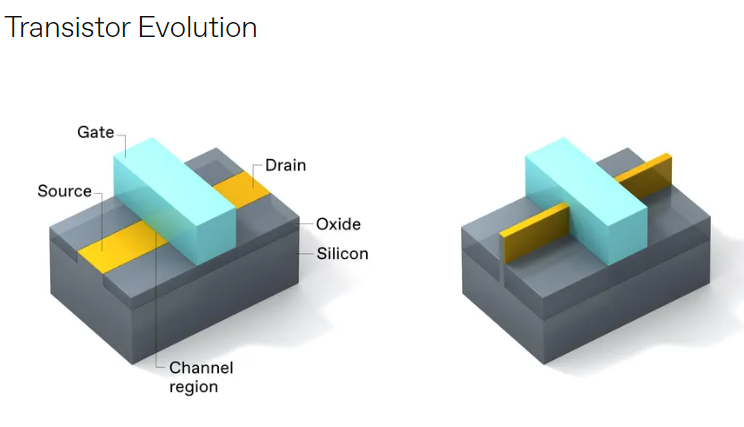
从平面晶体管架构 [左] 到 FinFET [右] 的转变提供了对沟道的更大利用 [由蓝色框覆盖],从而使功耗降低了 50%,性能提高了 37%。
英特尔于 2011 年推出其 FinFET,采用 22 纳米节点,应用于第三代酷睿处理器,从那时起,FinFET架构成为了摩尔定律延续的主力。使用 FinFET,晶体管就可以在更低的电压下运行并且具有更少的泄漏,在与上一代平面架构相同的性能水平下将功耗降低了约 50%。 FinFET 的切换速度也更快,从而性能提升了 37%。而且由于“鳍(Fin)”的两个垂直侧都发生了传导,因此该器件可以在给定的硅面积下,驱动更多的电流,而不是仅沿一个表面传导的平面器件。
然而,我们在转向 FinFET 时确实失去了一些东西。在平面器件中,晶体管的宽度由光刻定义,因此它是一个高度灵活的参数。但在 FinFET 中,晶体管宽度以离散增量(discrete increments)的形式出现——一次添加一个鳍——这一特性通常被称为鳍量化。尽管 FinFET 可能很灵活,但鳍量化仍然是一个重要的设计约束。围绕它的设计规则以及增加更多鳍片以提高性能的愿望将增加逻辑单元的总面积并使互连堆栈复杂化。此外,它还增加了晶体管的电容,从而降低了开关速度。因此,虽然 FinFET 作为行业主力为我们提供了更好的技术,但仍需要一种新的、更精细的方法,正是这种需求将我们引向了即将推出的 3D 晶体管。

在 RibbonFET 中,栅极环绕晶体管沟道区域,从而增强了对电荷载流子的控制。新结构还可以实现更好的性能和更精细的优化。
这一进步,就是RibbonFET,是自 FinFET 之后的第一个全新的晶体管架构。在其中,栅极完全围绕通道构建,可以更严格的控制沟道内的电荷载流子,这些沟道现在由纳米级硅带形成。使用这些纳米带(也称为纳米片),我们可以再次使用光刻技术根据需要改变晶体管的宽度。
去除量化约束后,我们可以为应用选择适当的沟道宽度。这让我们能够平衡功率、性能和成本。更重要的是,通过堆叠和并行操作的纳米带,该设备可以驱动更多电流,在不增加器件面积的情况下提高性能。
我们认为 RibbonFET 是在合理功率下实现更高性能的最佳选择,我们将在 2024 年推出它们以及其他创新,例如Intel 20A 制造工艺所提供的背面供电技术PowerVia。
堆叠式 CMOS
平面、FinFET 和 RibbonFET 晶体管的一个共同点是它们都使用 CMOS 技术,如上所述,该技术由 n 型 (NMOS) 和 p 型 (PMOS) 晶体管组成。 CMOS 逻辑在 1980 年代就成为主流,因为它消耗的电流明显少于替代技术,特别是单独的 NMOS 电路。更少的电流也意味着更高的工作频率和更高的晶体管密度。
迄今为止,所有 CMOS 技术都将标准 NMOS 和 PMOS 晶体管对并排放置。但在 2019 年 IEEE 国际电子器件会议 (IEDM) 的主题演讲中,我们介绍了将 NMOS 晶体管置于 PMOS 晶体管之上的 3D 堆叠晶体管的概念。次年,在 IEDM 2020 上,我们展示了第一个使用这种 3D 技术的反相器逻辑电路的设计。结合适当的互连,3D 堆叠 CMOS 方法有效地将反向器占位面积减半,使面积密度增加一倍,进一步突破摩尔定律的极限。
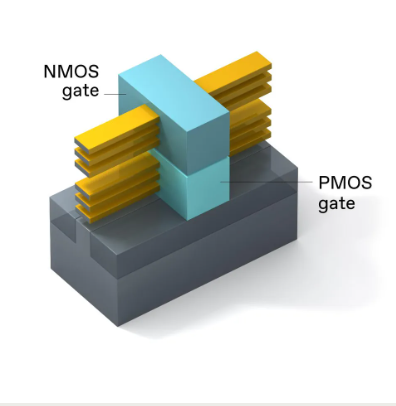
3D 堆叠 CMOS 将 PMOS 器件放置在 NMOS 器件的顶部,从而与单个 RibbonFET 占用的空间相同。 NMOS 和 PMOS 栅极使用不同的金属。
利用 3D 堆叠的潜在优势意味着解决许多工艺集成挑战,其中一些挑战将扩展 CMOS 制造的极限。
我们使用所谓的自对准工艺构建了 3D 堆叠 CMOS 反相器,其中两个晶体管都在同一个制造步骤中构建。这意味着通过外延(晶体沉积)构建 n 型和 p 型源极和漏极,并为两个晶体管添加不同的金属栅极。通过结合源漏和双金属栅工艺,我们能够创建不同导电类型的硅纳米带(p 型和 n 型)来构成堆叠的 CMOS 晶体管对。它还允许我们调整器件的阈值电压——晶体管开始开关的电压——分别针对顶部和底部纳米带。

在 CMOS 逻辑中,NMOS 和 PMOS 器件通常并排放置在芯片上。早期原型将 NMOS 器件堆叠在 PMOS 器件之上,从而压缩电路尺寸。
我们如何做到这一切?自对准 3D CMOS 制造始于硅晶片。在这个晶圆上,我们沉积了硅和硅锗的重复层,这种结构称为超晶格。然后,我们使用光刻图案切割部分超晶格并留下鳍状结构。超晶格晶体提供了强大的支撑结构。
接下来,我们将一块“虚拟”多晶硅沉积在超晶格部分的顶部的器件栅极上,以保护它们免受该过程的下一步的影响。该步骤称为垂直堆叠双源/漏极工艺,在顶部纳米带(未来的 NMOS 器件)的两端生长掺磷硅,同时在底部纳米带(未来的 PMOS 器件)上选择性地生长掺硼硅锗。在此之后,我们在源极和漏极周围沉积电介质,以将它们彼此电隔离,然后我们将晶圆抛光至完美平整度。
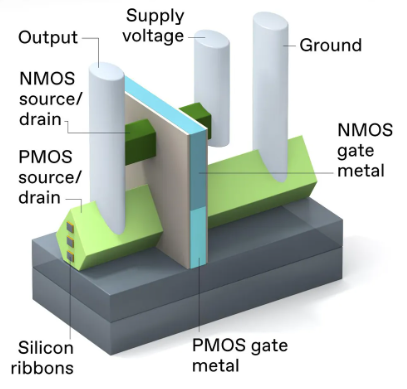
3D堆叠CMOS反相器的侧视图
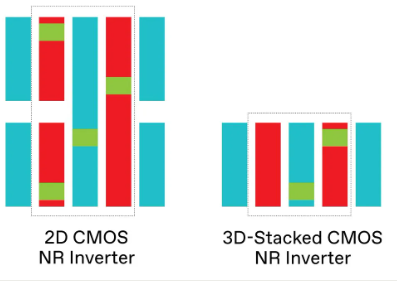
通过在 PMOS 晶体管顶部堆叠 NMOS,3D 堆叠有效地使每平方毫米的 CMOS 晶体管密度翻倍,尽管实际密度取决于所涉及的逻辑单元的复杂性。反相器单元从上方显示,指示源极和漏极互连 [红色]、栅极互连 [蓝色] 和垂直连接 [绿色]。
最后,我们构建门。首先,我们移除之前放置的虚拟门,露出硅纳米带。接下来我们只蚀刻掉硅锗,释放出一叠平行的硅纳米带,这将是晶体管的沟道区。然后,我们在纳米带的所有侧面涂上一层薄薄的绝缘体,该绝缘体具有高介电常数。纳米带通道是非常小,并且以这样一种复杂方式定位,以至于我们无法像使用平面晶体管那样有效地对它们进行化学掺杂。相反,我们使用称为功函数的金属门的特性来实现相同的效果。我们用一种金属围绕底部纳米带形成 p 型掺杂通道,用另一种金属围绕顶部纳米带形成 n 型掺杂通道。这样,栅叠层就完成了,两个晶体管也就完成了。
这个过程可能看起来很复杂,但它比替代技术更好——一种称为顺序 3D 堆叠 CMOS 的技术。采用这种方法,NMOS 器件和 PMOS 器件构建在不同的晶圆上,将两者粘合,然后将 PMOS 层转移到 NMOS 晶圆上。相比之下,自对准 3D 工艺需要更少的制造步骤并更严格地控制制造成本,这是我们在 2019 年 IEDM 上所报告的。
重要的是,自对准方法还避免了键合两个晶片时可能发生的未对准问题。尽管如此,顺序 3D 堆叠技术也在进行探索,以促进硅与非硅沟道材料(例如锗和 III-V 半导体材料)的集成。当我们希望将光电子和其他功能紧密集成在单个芯片上时,这些方法和材料可能会非常有意义。
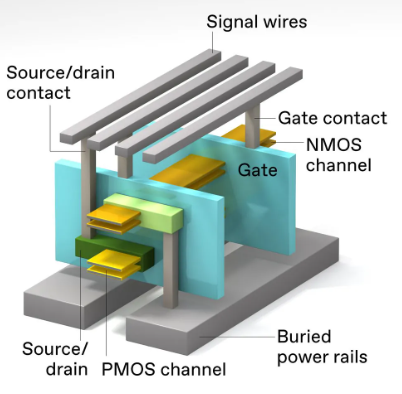
对 3D 堆叠 CMOS 进行所有需要的连接是一项挑战。需要从设备堆栈下方进行电源连接。在此设计中,NMOS 器件 [顶部] 和 PMOS 器件 [底部] 具有单独的源极/漏极触点,但两个器件都有一个共同的栅极。
新的自对准 CMOS 工艺及其创建的 3D 堆叠 CMOS 运行良好,似乎有很大的进一步小型化空间。在这个早期阶段,这是非常令人鼓舞的。栅极长度为 75 nm 的器件展示了低漏电流和出色的器件可扩展性和高导通电流。另一个有希望的迹象是:我们已经制造出两组堆叠器件,他们之间的最小距离仅为55 nm。虽然我们获得的器件性能结果本身并没有记录,但它们确实可以与构建在相同晶片上且具有相同处理的单个非堆叠控制器件相提并论。
在工艺集成和实验工作的同时,我们正在进行许多理论、模拟和设计研究,以期深入了解如何最好地使用 3D CMOS。我们发现了晶体管设计中的一些关键考虑因素。值得注意的是,我们现在知道我们需要优化 NMOS 和 PMOS 之间的垂直间距——如果太短会增加寄生电容,如果太长会增加两个器件之间互连的电阻。任何一种极端都会导致电路过慢,或者消耗更多功率。
此外,还有很多有趣的研究。例如东京电子(TEL)美国研究中心在 IEDM 2021 上提出的一项研究,专注于在 3D CMOS 的有限空间内提供所有必要的互连,并且不会显着增加逻辑单元的面积。TEL 研究表明,在寻找最佳互连选项方面存在许多创新机会。该研究还强调,3D 堆叠 CMOS 将需要在器件上方和下方都有互连。这种称为埋入式电源轨的方案采用为逻辑单元供电但不承载数据的互连,并将它们移至晶体管下方的硅片上。英特尔的 PowerVIA 技术正是这样做的,计划于 2024 年推出,也将在CMOS 3D 堆叠上发挥关键作用。
摩尔定律的未来
借助 RibbonFET 和 3D堆叠CMOS,我们将摩尔定律延伸到2024 年之后。在 2005 年戈登.摩尔先生接受的一次采访中,他表示“一路走来,我很多次都认为摩尔定律已经走到了尽头,但令我惊讶的是,我们颇具创意的工程师总能够一次次地把问题解决。”
随着向 FinFET 的转移、随之而来的优化,以及现在 RibbonFET 和最终 3D 堆叠 CMOS 的发展,以及围绕它们的无数封装技术改进的支持,我们认为摩尔先生会再次感到惊讶。
