一文助你全面理解合成控制方法 译文 精选
译者 |?朱先忠
审校 |?孙淑娟
现在人们普遍认为,对其感兴趣的结果(疾病、公司收入、客户满意度等)计算处理(药物、广告、产品等)因果效应的金标准技术是AB测试,也称为随机实验。我们将一组受试者(患者、用户、客户等)随机分为实验组和对照组,并对实验组进行实验。这一程序确保了在事前两测试组之间的唯一预期差异是由实验本身引起的。

AB测试的关键假设之一是实验组和对照组之间没有污染。给实验组的一名患者用药不会影响对照组患者的健康。例如,如果我们试图治愈一种传染病,而这两个群体并不是孤立的,情况可能就不是这样。在行业中,经常违反污染假设的是网络效应(我使用社交网络工具的次数随着网络朋友的增加而增加)和一般均衡效应(如果我改进一种产品,可能会减少另一种类似产品的销售)。
由于这个原因,实验通常是在足够大的规模下进行的,这样就不会造成跨群体(例如城市、州甚至国家)的污染。然后,由于规模更大,出现了另一个问题:治疗变得更昂贵。在医院给50%的患者用药比给一个国家50%的城市用药便宜得多。因此,通常仅治疗少数患者群体,但通常治疗时间较长。
在这样的需求环境下,大约10年前就出现了一种非常强大的方法:合成控制。合成控制的思想是:利用数据的时间变化而不是横截面变化(跨时间而不是跨单位)。当前,这种方法在业界(例如在谷歌、优步、Facebook、微软和亚马逊等公司)已经非常流行,因为它易于理解,而且能够应对经常是大规模出现的需求环境。在这篇文章中,我们将通过一个例子来探索这项技术:我们将调查自动驾驶汽车在共享乘车平台上的有效性。
自动驾驶汽车案例
假设您是一个共享乘车平台,您想测试车队中自动驾驶汽车的效果。
可以想象,对于这种类型的功能运行AB测试存在很多限制。首先,将单个游乐设施随机化很复杂。其次,这是一项非常昂贵的干预措施。第三,也是统计上最重要的一点,你不能在乘坐水平上进行这种干预。问题在于,从实验单元到对照单元都存在溢出效应:如果自动驾驶汽车确实更高效,这意味着它们可以在相同的时间内为更多的客户提供服务,减少了普通司机(对照组)可获得的客户。这种溢出污染了实验,并阻止了对结果的因果解释。
出于所有这些原因,我们只选择了一个城市。而且,鉴于这篇文章的合成氛围,我们选择了美国佛罗里达州第二大城市迈阿密!

迈阿密天际线
在实验中,我生成了一个模拟数据集。我们将在其中观察一组美国城市随时间的变化。其中,收入数据是由数据组成的,而社会经济变量取自经合组织??2022大都市区数据库???。我从??文件src.dgp???中导入数据生成过程dgp_selfdriving。另外,还从??文件src.utils??中导入一些绘图函数和库。
from src.utils import *
from src.dgp import dgp_selfdriving
treatment_year = 2013
treated_city = 'Miami'
df = dgp_selfdriving().generate_data(year=treatment_year, city=treated_city)
df.head()
数据快照
到目前为止,我们已经拥有自2002年至2019年期间美国46个最大城市的信息。注意到,面板中的数据是平衡的。这意味着,我们能够在所有时间段观察所有城市。而另一方面,自驾汽车是从2013年开始推出。
作为实验单元的迈阿密是否与样本的其余实验单元具有可比性?让我们使用优步公司开发的??causalml软件包??中的create_table_one函数来生成一个协变量平衡表,其中包含实验组和对照组的可观察特征的平均值。顾名思义,这应该是您在因果推理分析中呈现的第一个表。
from causalml.match import create_table_one
create_table_one(df, 'treated', ['density', 'employment', 'gdp', 'population', 'revenue'])
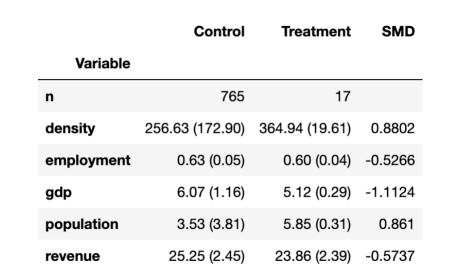
平衡表
正如预期的那样,这两个测试组并不平衡:迈阿密的人口密度更高、更穷、更大,就业率也低于我们样本中的美国其他城市。
我们有兴趣了解自动驾驶汽车的引入对收入的影响。
一个最初的想法是,像我们在AB测试中那样分析数据,比较对照组和实验组。在引入自动驾驶汽车后,我们可以通过实验组和对照组之间收入均值的差异来估计实验效果。
smf.ols('revenue ~ treated', data=df[df['post']==True]).fit().summary().tables[1]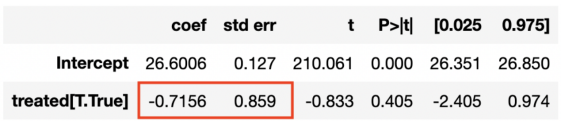
回归结果
自动驾驶汽车的影响似乎是负面的,但并不显著。
这里的主要问题是实验不是随机分配的。我们创建一个单独的实验单元,迈阿密,它很难与其他城市相比。
另一种方法是,比较迈阿密实验前后的收入。
smf.ols('revenue ~ post', data=df[df['city']==treated_city]).fit().summary().tables[1]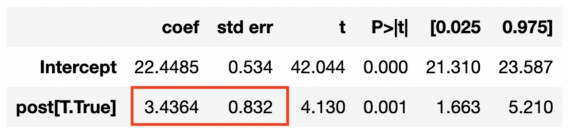
回归结果
自动驾驶汽车的影响似乎是正面的,在统计上也是显著的。
然而,这一程序的问题在于,2013年之后可能会发生许多其他事情。将所有差异归因于自动驾驶汽车是一个相当大的挑战。
如果我们绘制城市收入的时间趋势图,我们可以更好地理解这种担忧。首先,我们需要将数据重新格式化为宽格式,每个城市一列,每年一行。
df = df.pivot(index='year', columns='city', values='revenue').reset_index()
现在,让我们绘制迈阿密和其他城市的收入。
cities = [c for c in df.columns if c!='year']
df['Other Cities'] = df[[c for c in cities if c != treated_city]].mean(axis=1)
def plot_lines(df, line1, line2, year, hline=True):
sns.lineplot(x=df['year'], y=df[line1].values, label=line1)
sns.lineplot(x=df['year'], y=df[line2].values, label=line2)
plt.axvline(x=year, ls=":", color='C2', label='Self-Driving Cars', zorder=1)
plt.legend();
plt.title("Average revenue per day (in M$)");
既然我们在谈论迈阿密,让我们选择一个合适的调色板以便突出显示(粉紫色)。
sns.set_palette(sns.color_palette(['#f14db3', '#0dc3e2', '#443a84']))plot_lines(df, treated_city, 'Other Cities', treatment_year)
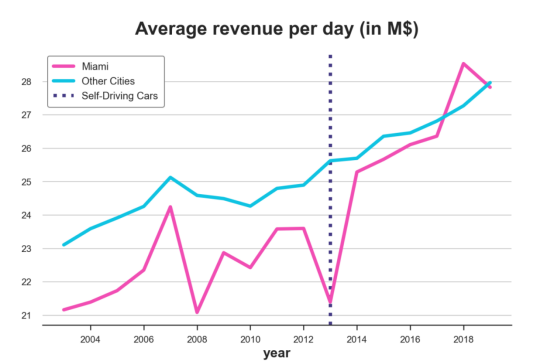
正如我们所见,在迈阿密进行实验后,收入似乎有所增加。但这是一个非常不稳定的时间序列。该国其他地区的收入也在增加。从这个图表展示的结果很难将这种变化主要归因于自动驾驶汽车。
我们能做得更好吗?
合成控制
答案是肯定的!当我们只有一个实验单元和多个对照单元,并且随着时间的推移来观察它们时,合成控制允许我们进行因果推断。这个想法很简单:将未处理的单元组合在一起,使它们尽可能接近实验单元的行为,而不进行处理。然后使用这种“合成单元”作为控制。该方法最早由Abadie、Diamond和Hainmueller(2010)提出,被称为“过去几年政策评估文献中最重要的创新”。此外,由于其简单性和可解释性,在行业中得到了广泛应用。
实验背景
我们假设,对于一组独立同分布受试者,随着时间t=1,…,T,我们将观察到一组变量(X?,D?,Y?),这包括:
- 实验任务D?∈{0,1}(已处理)
- 响应Y??∈R(收入)
- 特征向量X??∈R?(人口、密度、就业和GDP)
此外,在时间t*(在我们的案例中为2013年)处理一个单元(在我们的例子中为迈阿密)。我们区分实验前的时间段和实验后的时间段。
至关重要的是,实验D不是随机分配的。因此,实验单元和对照组之间的均值差异不是平均治疗效果的无偏估计值。
问题
问题在于,与往常一样,我们没有观察到实验单元的反事实结果,即,我们不知道如果他们没有接受实验,会发生什么。这被称为因果推理的基本问题。
最简单的方法就是比较实验前后的时间。这被称为事件研究方法。
然而,我们可以做得更好。事实上,即使实验不是随机分配的,我们仍然可以访问一些未接受实验的单元。
对于结果变量,我们观察到以下值:
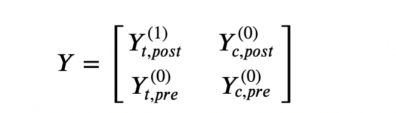
结果变量
在上述表达式中,Y????表示在给定实验任务a和实验状态d的时间t时刻的结果。我们基本上有一个数据缺失的问题,因为我们没有观察到Y????:如果不进行实验(d=0),那么实验单位(a=t)会发生什么情况。
解决方案
根据??Doudchenko和Inbens(2018)??的研究成果,我们可以将实验单元的反事实结果估计为对照单元观察结果的线性组合。

合成控制结果
上面公式中:
- 常数α允许两组之间的不同平均值
- 权重β?允许在控制单元i之间变化(否则,这将是差异中的差异)
我们应该如何选择使用哪些权重呢?我们希望我们的合成控制在实验前尽可能接近结果。第一种方法是将权重定义为:
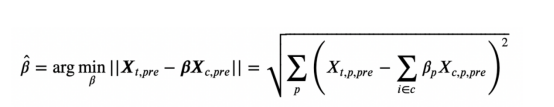
合成控制权重
也就是说,权重应使控制单元Xc的可观察特性与实验前的实验单元X之间的距离最小。
您可能会注意到,这与线性回归非常相似。事实上,我们正在做一些非常相似的事情。
在线性回归中,我们通常有许多单位(观测值),很少有外部特征和一个内生特征,我们试图将内生特征表示为每个单位内生特征的线性组合。
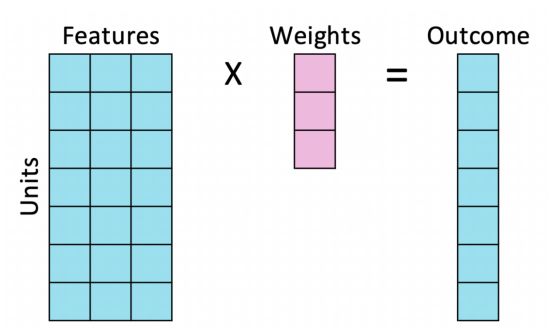
线性回归
对于合成控制,我们有许多时间段(特征),很少的控制单元和单个实验单元,我们尝试将实验单元表示为每个时间段控制单元的线性组合。
为了执行相同的操作,我们基本上都需要对数据进行转置。
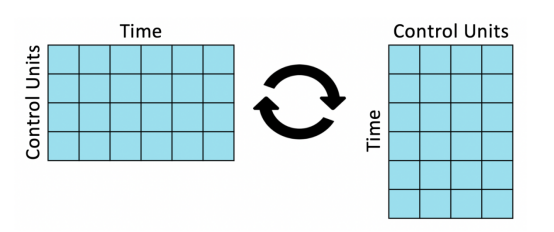
转置数据
转置之后,我们计算合成控制权重,就像计算回归系数一样。然而,现在一个观测值是一个时间段,一个特征对应一个单元。
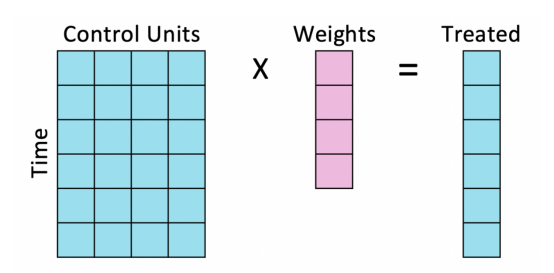
合成控制回归
请注意,此转换不是无辜的。在线性回归中,我们假设外部特征和内部特征之间的关系在各个单元之间是相同的,而在合成控制中,我们假定处理单元和控制单元之间的关系随时间的推移是相同的。
回到自动驾驶汽车案例
现在,让我们回到上面的自动驾驶汽车数据处理步骤。首先,我们编写了一个synth_predict函数,该函数将在控制城市上训练的模型作为输入,并尝试在引入自动驾驶汽车之前预测经过处理的城市迈阿密的结果。
让我们通过线性回归来估计模型。
from sklearn.linear_model import LinearRegression
coef = synth_predict(df, LinearRegression(), treated_city, treatment_year).coef_
我们在迈阿密的预自动驾驶汽车收入方面的表现如何?自动驾驶汽车的潜在影响是什么?
通过绘制迈阿密城市的实际收入和预测收入,我们可以直观地回答这两个问题。
plot_lines(df, treated_city, f'Synthetic {treated_city}', treatment_year)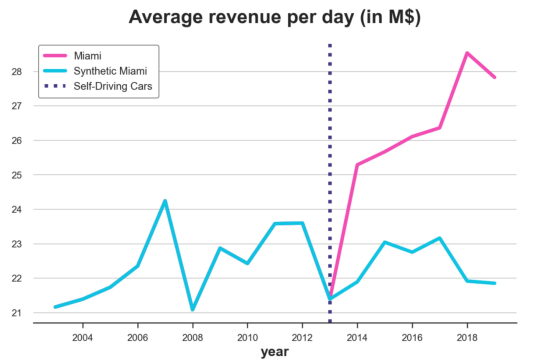
观测的和合成的Miami收入对照
看起来自动驾驶汽车对迈阿密的收入产生了明显的正面影响:预测的趋势低于实际数据,并且在自动驾驶汽车推出后就出现了偏差。
另一方面,我们显然是过度拟合:实验前预测的收入线与实际数据完全重叠。考虑到迈阿密收入的高度可变性,至少可以说这是可疑的。
另一个问题涉及权重。让我们来设计它们。
df_states = pd.DataFrame({'city': [c for c in cities if c!=treated_city], 'ols_coef': coef})
plt.figure(figsize=(10, 9))
sns.barplot(data=df_states, x='ols_coef', y='city');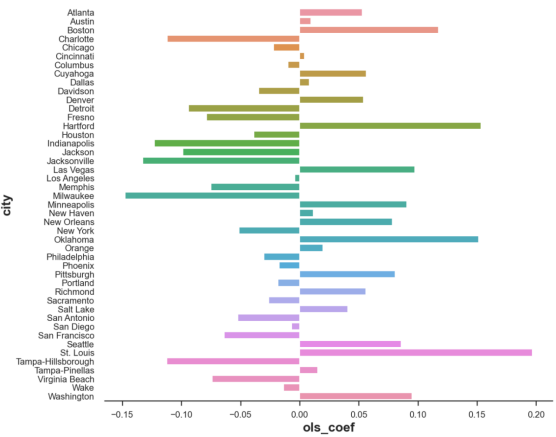
合成控制权重
我们的数据中存在许多负权重,从因果推理的角度来看,它们没有多大意义。我可以理解:迈阿密可以用0.2比例的圣路易斯、0.15比例的俄克拉何马和0.15比例的哈特福德的组合来表达。但迈阿密是密尔沃基-0.15比例是什么意思?
因为我们想把我们的合成控制解释为未处理状态的加权平均;所以,所有权重都应该是正数,并且它们的总和应该是1。
为了解决这两个问题(加权和过度拟合),我们需要对权重施加一些限制。
约束权重
为了解决权重过大和负权重的问题,Abadie、Diamond和??Hainmueller(2010)??提出了以下权重定义:
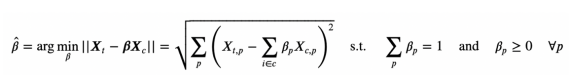
权重的约束定义
这意味着,一组权重β:
- 实验前对照组Xc的加权可观察特征与实验组X的可观察特征相匹配
- 它们的总和为1
- 并且不是负的
from toolz import partial
from scipy.optimize import fmin_slsqp
class SyntheticControl():
# Loss function
def loss(self, W, X, y) -> float:
return np.sqrt(np.mean((y - X.dot(W))**2))
# Fit model
def fit(self, X, y):
w_start = [1/X.shape[1]]*X.shape[1]
self.coef_ = fmin_slsqp(partial(self.loss, X=X, y=y),
np.array(w_start),
f_eqcons=lambda x: np.sum(x) - 1,
bounds=[(0.0, 1.0)]*len(w_start),
disp=False)
self.mse = self.loss(W=self.coef_, X=X, y=y)
return self
# Predict
def predict(self, X):
return X.dot(self.coef_)
通过这种方法,我们得到了一个可解释的反事实,即未处理单元的加权平均数。
现在,我们来编写我们自己的目标函数。为此,我创建了一个新类SyntheticControl,它使用了一个如上所述的损失函数,还有一个方法用来拟合它并且预测已处理单元的值。
我们现在可以重复与以前相同的过程,但使用SyntheticControl方法,而不是简单、无约束的LinearRegression方法。
df_states['coef_synth'] = synth_predict(df, SyntheticControl(), treated_city, treatment_year).coef_
plot_lines(df, treated_city, f'Synthetic {treated_city}', treatment_year)
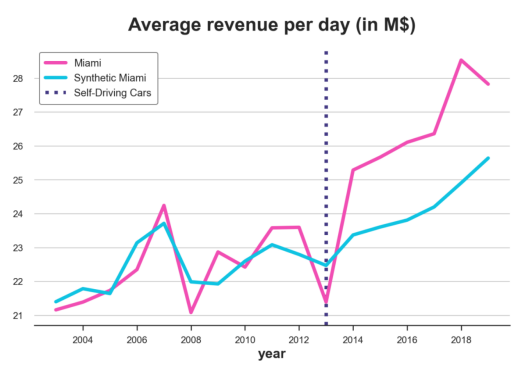
观测的和合成的Miami收入对照
正如我们所看到的,现在已经不再存在过度拟合了。预处理的实际收入和预测收入接近,但不完全相同。原因是非负性约束将大多数系数约束为零,正如??Lasso??所做的那样。
现在看起来效果又是负面的。不过,让我们仔细绘制一下两条线之间的差异,以便更好地显示幅度变化。
def plot_difference(df, city, year, vline=True, hline=True, **kwargs):
sns.lineplot(x=df['year'], y=df[city] - df[f'Synthetic {city}'], **kwargs)
if vline:
plt.axvline(x=year, ls=":", color='C2', label='Self-driving cars', lw=3, zorder=100)
plt.legend()
if hline: sns.lineplot(x=df['year'], y=0, lw=3, color='k', zorder=1)
plt.title("Estimated effect of self-driving cars");
请参考存储于GitHub网站工程仓库中的源文件synth_plot_difference.py了解更详细的代码。
plot_difference(df, treated_city, treatment_year)
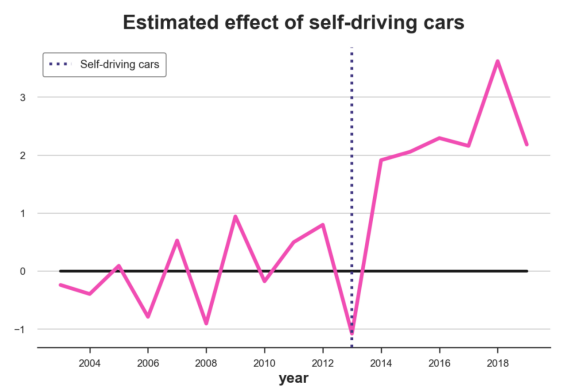
观测的和合成的Miami收入差异对照图
图中的差异显然是正面的,并且随着时间的推移略有增加。
我们还可以通过可视化权重来解释估计的反事实(如果没有自动驾驶汽车,迈阿密会发生什么)。
plt.figure(figsize=(10, 9))
sns.barplot(data=df_states, x='coef_synth', y='city');
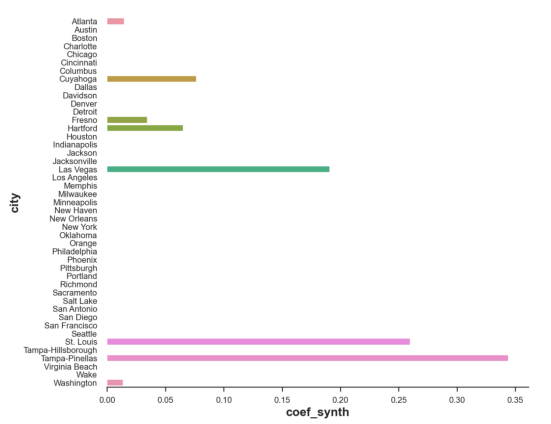
约束权重
正如我们所见,现在我们将迈阿密的收入表示为几个城市的线性组合:坦帕、圣路易斯,以及在较低程度上的拉斯维加斯。通过这种办法,整个过程变得非常透明。
推论
那么,至此我们可以得到什么推论呢?估计值是否与零显著不同?或者,更实际地说,“在没有政策效应的零假设下,这种估计有多不寻常?”。
为了回答这个问题,我们将进行随机性排列测试。我们的想法是,如果这项政策没有效果,我们观察到的迈阿密的效果应该与我们观察的任何其他城市的效果没有显著差异。
因此,我们将复制上述程序;但是,对于所有其他城市来说,将其与迈阿密的估计值进行比较。
fig, ax = plt.subplots()
for city in cities:
synth_predict(df, SyntheticControl(), city, treatment_year)
plot_difference(df, city, treatment_year, vline=False, alpha=0.2, color='C1', lw=3)
plot_difference(df, treated_city, treatment_year)
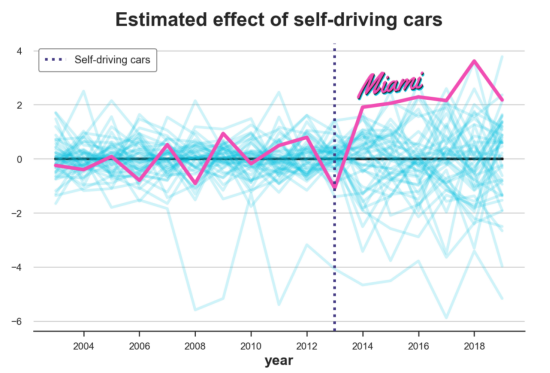
合成效果分布
从图中,我们注意到两件事。首先,迈阿密的影响非常极端,因此可能不会受到随机噪音的影响。
第二,我们还注意到,有几个城市我们无法很好地拟合之前的趋势。特别是,有一条线明显低于所有其他线。这是意料之中的,因为对于每个城市,我们将反事实趋势构建为所有其他城市的凸组合。在收入方面相当极端的城市对于构建其他城市的反事实非常有用,但很难为它们构建反事实。
为了不使分析产生偏差,让我们排除在预处理MSE方面无法构建“足够好”反事实的状态。
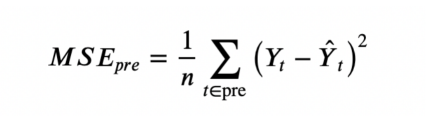
均方误差预测的预处理
根据经验,Abadie、Diamond和??Hainmueller(2010)??建议排除预测MSE大于处理单元MSE两倍的单元。
# Reference mse
mse_treated = synth_predict(df, SyntheticControl(), treated_city, treatment_year).mse
# Other mse
fig, ax = plt.subplots()
for city in cities:
mse = synth_predict(df, SyntheticControl(), city, treatment_year).mse
if mse < 2 * mse_treated:
plot_difference(df, city, treatment_year, vline=False, alpha=0.2, color='C1', lw=3)
plot_difference(df, treated_city, treatment_year)
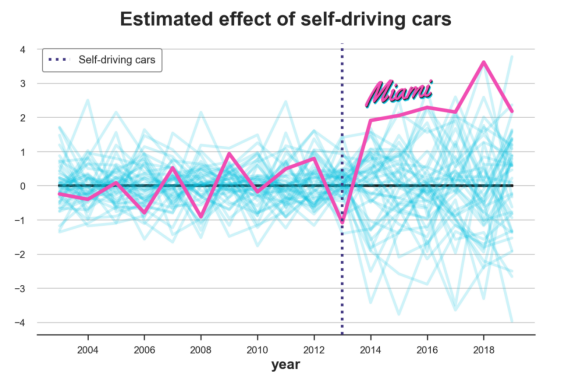
没有不可预测单元时的合成效果分布
排除极端观测后,迈阿密的影响似乎极不寻常。
Abadie、Diamond和Hainmueller(2010)建议进行随机试验的一个统计数据是治疗前MSE和治疗后MSE之间的比率。
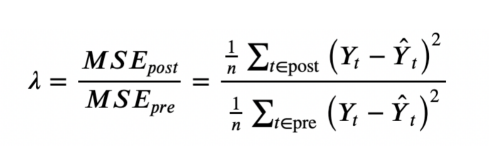
前后均方预测误差比
我们可以计算一个p值作为具有更高比率的观测数。
lambdas = {}对于每一个城市,都执行如下操作:
mse_pre = synth_predict(df, SyntheticControl(), city, treatment_year).mse
mse_tot = np.mean((df[f'Synthetic {city}'] - df[city])**2)
lambdas[city] = (mse_tot - mse_pre) / mse_pre
print(f"p-value: {np.mean(np.fromiter(lambdas.values(), dtype='float') > lambdas[treated_city]):.4}")
请参考存储于GitHub网站工程仓库中的源文件mse_predict.py了解更详细的代码。
p-value: 0.04348
似乎只有4.3%的城市的MSE比迈阿密大,这意味着p值为0.043。我们可以用直方图直观地显示排列下的统计分布。
fig, ax = plt.subplots()
_, bins, _ = plt.hist(lambdas.values(), bins=20, color="C1");
plt.hist([lambdas[treated_city]], bins=bins)
plt.title('Ratio of $MSE_{post}$ and $MSE_{pre}$ across cities');
ax.add_artist(AnnotationBbox(OffsetImage(plt.imread('fig/miami.png'), zoom=0.25), (2.7, 1.7), frameon=False));
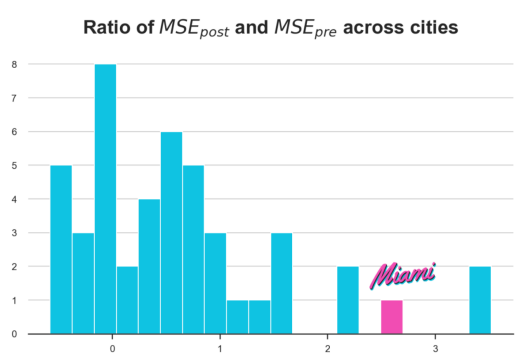
各城市前后MSE比率的分布
事实上,迈阿密的统计数据是相当极端的,这也表明观察到的效应不太可能是噪声造成的。
结论
在本文中,我们探索了一种时下非常流行的因果推断方法——合成控制方法,当我们只有很少的处理单元但有很多时间段时常常使用这种方法。这种情形经常出现在行业需求中,此时必须在总体水平上分配处理,而且可能不会进行随机化。合成控制的关键思想是将控制单元组合成一个合成控制单元,用作反事实,以估计处理的因果效应。
合成控制的主要优点之一是,只要我们使用约束是和为1的正权重,该方法就能够避免外推:我们永远不会失去数据的支持。此外,合成控制研究可以“预先注册”:您可以在研究前指定权重,以避免P值篡改(p-hacking)和择优而取(cherry-picking)。这种方法在业界如此流行的另一个原因是权重使反事实分析变得明确:人们可以查看权重并了解我们正在进行的比较。
总体来看,合成控制方法的发展尚处于发展早期,每年都会出现该方法的许多扩展。一些值得关注的扩展包括:??徐(2017)的广义合成控制???、Doudchenko和??Imbens(2017)提出的差异合成控制???、??Abadie e L(2020)的惩罚合成控制???提出的??矩阵完成方法??,等等。最后还值得补充的一个重要细节是,如果你想让其发明者之一解释这种方法,那么在Youtube上可以免费获得由Alberto Abadie在NBER暑期研究所做的精彩演讲。
参考文献
[1] A. Abadie, A. Diamond, J. Hainmueller,?Synthetic Control Methods for Comparative Case Studies: Estimating the Effect of California’s Tobacco Control Program?(2010),?Journal of the American Statistical Association.
[2] A. Abadie,?Using Synthetic Controls: Feasibility, Data Requirements, and Methodological Aspects?(2021),?Journal of Economic Perspectives.
[3] N. Doudchenko, G. Imbens,?Balancing, Regression, Difference-In-Differences and Synthetic Control Methods: A Synthesis?(2017),?working paper.
[4] Y. Xu,?Generalized Synthetic Control Method: Causal Inference with Interactive Fixed Effects Models?(2018),?Political Analysis.
[5] A. Abadie, J. L’Hour,?A Penalized Synthetic Control Estimator for Disaggregated Data?(2020),?Journal of the American Statistical Association.
[6] S. Athey, M. Bayati, N. Doudchenko, G. Imbens, K. Khosravi,?Matrix Completion Methods for Causal Panel Data Models?(2021),?Journal of the American Statistical Association.
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
原文标题:??Understanding Synthetic Control Methods??,作者:Matteo Courthoud
