基于TensorFlow和QuestDB的时间序列预测 译文 精选
?译者 |?朱先忠
审校 |?孙淑娟
时间序列预测的机器学习概述?

当前,机器学习正在席卷全球,机器人能够以类似人类的精度完成许多领域中的任务。例如,在医疗领域,智能助手可以随时检查人们的健康状况;在金融领域,也有一些工具可以合理准确地预测投资回报;而在在线营销中,也已经研发出一些产品推荐工具能够根据人们的购买历史向其推荐特定的产品和品牌。
在上述这些应用领域中,人们可以使用不同类型的数据来训练机器学习模型。其中,时间序列数据用于训练机器学习算法。在这种情况下,时间是关键组成部分。
时间序列数据很复杂,涉及的时间相关特征超出了传统机器学习算法(如回归、分类和聚类)的适用范围。幸运的是,如今我们可以直接使用现成的机器学习模型进行时间序列预测。由于时间的可变性质,由时间序列预测得出的预测结果可能并不完全精确,但它们确实提供了适用于各种领域的合理近似值。让我们考虑以下几种应用案例:
- 预测性维护:如今,物联网、人工智能(AI)和集成系统正在嵌入到电子、机械和其他类型的设备中,并使其智能化。这些物联网设备中安装了传感器,可以随时间跟踪相关值;人工智能是时间序列预测的一个关键组成部分,用于分析这些数据并预测设备可能需要维护的大致时间。
- 异常检测:检测系统功能中罕见事件和观察结果的过程。识别这些事件可能具有相当的挑战性,但时间序列预测通过提供可以连续监测事物的智能元素而对此类任务有所帮助。金融科技领域中的网络安全、健康监测和欺诈检测等就是利用时间序列分析进行异常检测的系统的几个例子。
- 物联网数据:物联网正在成为当今社会经济的一个重要支柱。物联网设备能够及时存储数据,并跨其他设备进行通信以进行分析和预测。其中一个例子是温度预测:在这种应用中,人们使用不同的物联网设备定期存储温度数据,因而这类预测常常应用于与天气相关的预测和决策。
- 自动调整决策:通过时间序列预测,企业可以更好地监控其产品或解决方案的需求,并及时预测未来需求,从而相应地调整其服务。
- 交易:每天股市开盘和收盘时,都会在几秒钟内输入波动数据。使用各种数据库和文件存储系统存储所有这些信息,然后可以使用不同的时间序列预测算法对未来的一天、一周甚至一个月进行价格预测。
在本文接下来内容中,我们将建立并训练一个简单的机器学习模型,该模型使用时间序列数据,并使用谷歌公司的TensorFlow框架和时间序列数据库QuestDB实现趋势和事件的预测。
TensorFlow与QuestDB简介
时间序列预测可以以不同的方式进行,包括使用各种机器学习算法,如ARIMA、ETS、简单指数平滑和递归神经网络(RNN),等等。其中,RNN是一种深度学习方法,当然其本身也具有多种变体,如LSTM和GRU。这些神经网络在神经网络层之间存在反馈回路。这使它们成为时间序列预测任务的理想选择,因为网络可以“记住”以前的数据。通过使用谷歌的TensorFlow库,这些深度学习算法的实现变得更加容易;目前,该库支持各种流行的神经网络和深度学习算法。
任何算法的核心都是数据,这与时间序列预测没有什么不同。与传统数据库相比,时间序列数据库(TSDB)为存储和分析时间序列数据提供了更多的功能。在本教程中,我选择的TSDB是QuestDB,这是一种开源的时间序列数据库,专注于快速性能和易用性。
预测性数据分析实战
现在,相信你已经对时间序列数据和时间序列分析有了更深入的了解。接下来,让我们通过构建一个具体的应用程序来使用这些数据预测趋势,从而深入研究一下其具体的实现过程。本教程将使用美元对印度卢比数据集的历史汇率,你可以在链接(https://excelrates.com/historical-exchange-rates/USD-INR)处以Excel格式下载该数据集。请确保选择1999-2022年份之间的时间跨度。此数据集包含三列:
- Date:表示汇率日期的时间部分。
- USD:以美元表示的美元价格(常数1.0)。
- INR:在特定日期以INR表示的美元价格。
正如你所了解的,时间序列预测算法存在许多不同的方案(例如ARIMA、ETS、简单指数平滑、RNN、LSTM、GRU等)。本文将重点讨论深度学习解决方案——使用神经网络来完成时间序列预测。值得注意的是,对少量数据使用RNN可能会导致称为梯度消失的问题。为此,人们引入了门控机制LSTM和GRU。由于此项目架构简单;所以,GRU是本教程中使用少量数据示例的最佳选择。
让我们开始吧!
安装TensorFlow
TensorFlow可以通过Python包管理器(PIP)轻松安装。请确保你使用的是Python 3.6与TensorFlow 1.15(以及更高版本),以便保持与本文示例项目的最佳兼容性。当然,如果你的系统中已经安装了Anaconda,则也可以使用Anaconda提示符方式。对于普通Python安装,可以使用默认命令提示符并编写以下命令来安装TensorFlow:
pip install tensorflow
注意:如果你使用的是macOS系统并且出现pip错误,请尝试运行如下的pip安装命令:
pip install tensorflow-macos
现在,我们需要安装一些依赖项,除非你已经在本地安装了它们:
docker run -p 9000:9000 -p 8812:8812 questdb/questdb
?安装QuestDB
要在任何操作系统平台上安装QuestDB,你需要:
- 首先安装Docker。
- 然后,拉取QuestDB的Docker映像并创建一个Docker容器。为此,打开命令提示符并编写以下命令:
docker run -p 9000:9000 -p 8812:8812 questdb/questdb?
这里,9000是QuestDB运行的端口,8812端口是Postgres协议所要求的。
然后,打开另一个终端并运行以下命令来检查Ques?tDB是否正在运行:?
docker ps
或者,你可以浏览localhost:9000,QuestDB应该支持通过这个本地网址进行访问。
导入依赖项
现在已经安装了依赖项,是时候开始使用TensorFlow和QuestDB实现时间序列预测了。如果你想克隆这个项目并在自己的Jupyter笔记本中继续调试,那么GitHub项目仓库的链接地址是https://github.com/gouravsinghbais/Time-Series-Forecasting-with-Tensorflow-and-QuestDB。
我们通过运行以下命令来启动本地jupyter环境:
jupyter notebook
首先,我们导入以下依赖项:
##导入依赖项
import numpy as np
import pandas as pd
##深度学习依赖性
'''
如果你使用的是python版本>3.6
你应该直接使用tensorflow代替keras导入模型依赖项
例如:from tensorflow.keras.optimizers import *
'''
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import *
from keras.optimizers import *
## QuestDB依赖项
import io
import requests
import urllib.parse as par
##时间戳依存关系
from datetime import datetime
##可视化依赖项
import matplotlib.pyplot as plt
%matplotlib inline
读取数据集
导入所有计算、深度学习和可视化依赖项后,就可以继续读取我们之前下载的数据集:
#使用pandas库读取数据集
df = pd.read_excel('Excelrates.xlsx')
##检查数据集的前几行
df.head()
由于要读取的数据集是Excel文件,因此必须使用Pandas库提供的read_excel()函数。读取数据集后,可以借助head()函数检查其前几行。你的数据集应该如下所示:
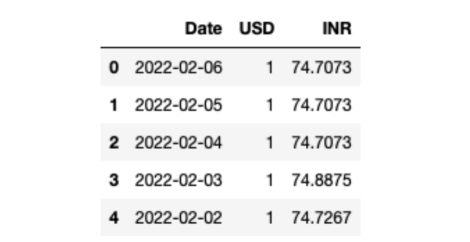
创建QuestDB表
现在,你已经看到了数据集,但Excel存储大量数据的能力有限。因此,你需要使用QuestDB来存储时间序列数据。为此,首先确保QuestDB Docker容器正在运行并可访问:
## 创建表查询
q = '''create table excel_rates (
Date timestamp,
USD int,
INR double)'''
##连接到QuestDB URL并执行查询
r = requests.get("http://localhost:9000/exec?query=" + q)
##执行表创建查询后打印状态代码
print(r.status_code)
然后,在QuestDB中创建表与在任何其他数据库(如SQL、Oracle、NoSQL等)中创建表的过程相同。只需提供表名、列名及其各自的数据类型。然后,连接到QuestDB正在运行的端口(在本例中为端口9000),并使用Python的请求模块执行查询。如果查询执行成功,它将返回状态代码200;如果没有成功,你将收到状态代码400。
将数据插入QuestDB
创建表后,需要将数据存储在其中。使用以下代码执行此操作:
## 用于跟踪查询成功执行的变量
success = 0
fail = 0
## 迭代每一行并将其存储在QuestDB表中
for i, row in df.iterrows():
date = row['Date']
##将日期转换为日期时间格式以存储在数据库中
date = "'"+date.strftime('%Y-%m-%dT%H:%M:%S.%fZ')+"'"
usd = row['USD']
inr = row['INR']
query = f'insert into excel_rates values({date}, {usd}, {inr})'
r = requests.get("http://localhost:9000/exec?query=" + query)
if r.status_code == 200:
success += 1
else:
fail += 1
##检查执行是否成功
if fail > 0:
print("Rows Failed: " + str(fail))
if success > 0:
print("Rows inserted: " + str(success))
要在QuestDB表中存储数据,需要使用insert查询。如上所示,迭代数据框DataFrame中的每一行,并在数据库中插入Date、USD和INR列。如果成功插入所有行,你将收到代码200;如果其中任何一个失败,你将得到代码400。
注意:由于数据类型不匹配,可能返回错误代码400。对于DateTime,请确保你的日期数据包含在单引号中。
从QuestDB中选择数据
从数据库而不是直接从文件中读取数据的一个优点是,我们可以轻松地通过运行过滤器或聚合运算来运行查询。在本教程中,我们将不读取整个数据集(超过17000行),而只选择三年的数据,约2200行。注意,你可以随意修改代码中的过滤器部分的代码,以比较我们的模型在使用更大的数据集进行训练时是否预测得更好。
##从QuestDB中选择数据
r = requests.get("http://localhost:9000/exp?query=select * from excel_rates where Date in ('2022') or Date in ('2021') or Date in ('2020')")
rawData = r.text
##将字节转换为CSV格式并使用pandas库读取
df = pd.read_csv(io.StringIO(rawData), parse_dates=['Date'])
df.columns
在这里,为了从QuestDB检索数据,你需要使用select查询。select查询的输出是表示数据的字节数组。检索到数据后,可以使用pandas库的read_csv()函数来读取数据。
预处理数据
到目前为止,你已经创建了表,在表中插入了数据,并从表中成功读取了数据。现在,是时候做一些时间序列预测预处理了。
首先,你可以继续删除USD列,因为它包含所有值“1”;因此,它不会以任何方式对预测结果有所贡献。为此,请使用以下代码:
##从数据帧中删除USD列
df = df.drop('USD', axis=1)
##将日期列转换为日期时间格式
df['Date'] = pd.to_datetime(df["Date"])
##将日期设置为索引
indexed_df = df.set_index(["Date"], drop=True)
indexed_df.head()
现在,你应该看到如下形式的DataFrame数据帧:
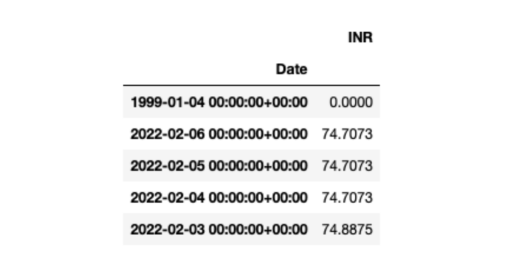
要查看INR值如何随时间变化,可以使用以下代码绘制时间和INR之间的曲线:
##绘制数据帧
indexed_df.plot()
绘制结果应该是这样的:
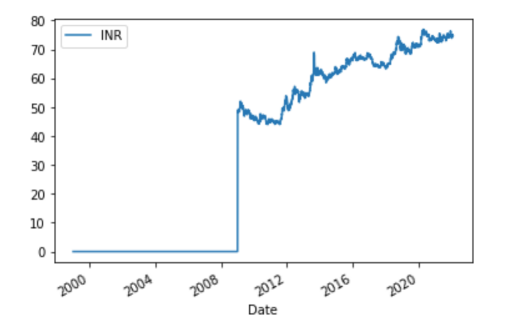
时间序列预测是一种有监督的方法,这意味着它使用输入特征和标签进行预测。到目前为止,只使用日期Date作为索引,列INR作为特征。要创建标签,需要将每个INR值移位1,使INR成为输入特征,而移动后的值将成为输出特征/标签。此外,你还需要从列中删除NaN值,使其适合于训练。使用以下代码即可完成所有这些操作:
## 把INR沿垂直方向(索引方向)向下移位1
shifted_df= indexed_df.shift()
##合并
concat_df = [indexed_df, shifted_df]
data = pd.concat(concat_df,axis=1)
## 把NaN全部替换以0
data.fillna(0, inplace=True)
data.head()
一旦完成,你的数据集应该如下所示:
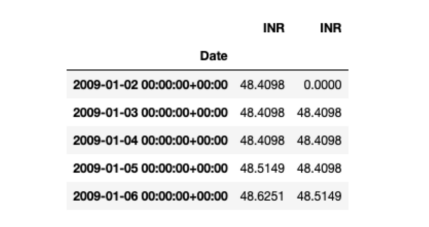
接下来,你需要将数据分为两个不同的类别—训练集和测试集:
##将数据转换为numpy数组
data = np.array(data)
##可以将最后500个数据点作为测试集
train , test = data[0:-500], data[-500:]
由于数据中存在多样性(值在大范围内变化),因此需要对数据进行一些缩放调整或规范化。为此,可以借助MinMaxScaler对象来实现:
##缩放
scaler = MinMaxScaler()
train_scaled = scaler.fit_transform(train)
test_scaled = scaler.transform(test)
##训练数据集
y_train = train_scaled[:,-1]
X_train = train_scaled[:,0:-1]
X_train = X_train.reshape(len(X_train),1,1)
##测试数据集
y_test = test_scaled[:,-1]
X_test = test_scaled[:,0:-1]
创建模型
现在,预处理已经完成,是时候为时间序列预测训练深度学习(GRU)模型了。使用以下代码执行此操作:
## GRU模型
model = Sequential()
## GRU层
model.add(GRU(75, input_shape=(1,1)))
## 输出层
model.add(Dense(1))
optimizer = Adam(lr=1e-3)
model.compile(loss='mean_squared_error', optimizer=optimizer, metrics=['accuracy'])
model.fit(X_train, y_train, epochs=100, batch_size=20, shuffle=False)
在上面代码中,将模型定义为序列模型(Sequential)。这意味着,你稍后要附加的任何层都将连续添加到上一层。然后,定义一个包含75个神经元的GRU层,并添加一个紧密集(完全连接)层作为输出层。因为我们正在创建深度学习模型,所以还需要添加优化器和损失函数。在本例这种情况下,选择Adam算法来优化GRU神经网络即可。另一方面,因为我们所处理的是数值数据,所以借助损失函数mean_squared_error即能够处理有关细节。最后,对输入数据进行模型拟合。
执行上述代码后,将开始模型训练。训练过程是这样的:
一旦模型准备好,接下来就需要在测试集上测试它,以检查其准确性:
##对测试集进行预测
X_test = X_test.reshape(500,1,1)
y_pred = model.predict(X_test)
##可视化结果
plt.plot(y_pred, label = 'predictions')
plt.plot(y_test, label = 'actual')
plt.legend()
显示实际标签和预测标签的图形绘制结果应如下所示:
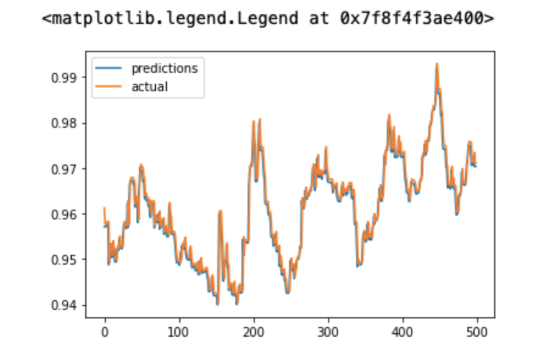
如你所见,预测值是实际值的近似值,这表明模型的性能足够好。由于测试数据使用很多点来表示,所以图中看上去出现不少簇。为了方便更仔细地查看这些值,你也可以仅可视化100个值来绘制图形:
##可视化结果
plt.plot(y_pred[:100], label = 'predictions')
plt.plot(y_test[:100], label = 'actual')
plt.legend()
仅显示100个实际值和预测值的简化图如下所示:
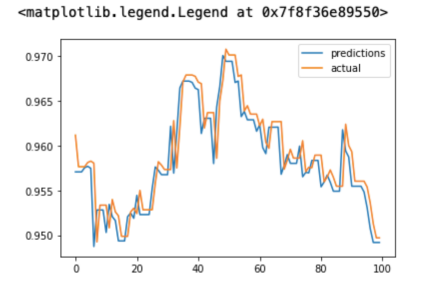
现在,你的时间序列预测模型已经就绪,你可以使用它对即将到来的日期进行预测。完整的项目源码可以在链接(https://github.com/gouravsinghbais/Time-Series-Forecasting-with-Tensorflow-and-QuestDB)处找到。
结论
在本教程中,我们介绍了如何使用深度学习框架TensorFlow和时序数据库QuestDB进行时间序列预测。随着越来越多的电子和机械设备变得智能化,手动操作已逐渐成为历史。为了有效地以自动化方式维护这些机器,你需要借助适当的工具来存储和处理机器生成的数据。
总之,当面对时间序列预测问题时,传统数据库不是一个好的方案,因为它们更侧重于处理和写入事务中的数据。相反,时间序列数据库是专门为存储不同时间间隔的观测值而设计的,所以更适合这一领域。正如你在本教程中所看到的,时间序列数据库还提供了帮助处理时间序列的其他功能和相关工具。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
原文标题:??Time-series Forecasting With TensorFlow and QuestDB???,作者:Gourav Bais?
