汽车之家APP基于Mach-O的探索与实践 原创 精选
背景
Mach-O简介:
Mach-O文件全称Mach Object,是在MacOS、iOS、iPadOS上的可执行文件,类似于Windows上PE文件。支持的CPU架构类型主要有x86_64、armv7、arm64。
Mach-O文件的生成过程:源代码-->预处理-->词法分析-->语法分析-->语义分析-->中间代码-->生成目标代码-->汇编-->机器码-->静态链接-->Mach-O文件
Mach-O能做什么?
了解Mach-O格式的结构和加载过程,可以帮助我们更容易的理解APP的启动过程、C函数的hook、动态库的懒加载等原理。常见的应用场景有:
① Crash的符号化
② Bitcode分析
③ APP启动速度的优化
④ 优化APP包体积
⑤ 方法调用链分析
接下来,本文针对第5种应用场景,介绍下工作中用到的两个实践项目。
1.基于Mach-O文件的动态库与静态库的归属方案。
2.基于Mach-O的API扫描方案。
由于目前APP Store上基本已废弃对armv7的支持,所以接下来介绍的方案都是基于arm64架构的Mach-O分析。
实践项目一:基于Mach-O文件的动态库与静态库归属方案
背景:大部分的APP都会包含多个动态库与静态库,之家APP也一样,并且随着业务的增长,APP内集成的功能越来越多,静态库和动态库的数量也在不断增加。为了提升用户体验,之家APP进行了多个维度的数据采集,如:网络、崩溃、卡顿、秒开、图片性能等,而采集后的数据如何精准、快速的分发到研发人员进行解决,一直是我们面对的难题。
基于Mach-O结构与Runtime的原理,我们通过不断实践,实现了一套自定义归属方案,此方案可以对性能数据进行库的归属划分,再通过库归属找到开发人员,从而解决分发难题。
下面对此方案做一个详细说明。
首先,归属划分主要涉及动态库与静态库两种场景:
(1)运行时创建的某个对象归属于哪个库(通过类查找库)。
(2)公共库的某个方法被哪个库所调用(通过堆栈查找库)。
因为动态库其本身就是代码隔离的,查找非常方便,而静态库最终会被编译到主程序的二进制文件中,或者多个静态库被包到一个动态库中,所以无法直接进行类和堆栈的归属划分。
接下来本段落会先介绍下动态库的归属方法,然后重点介绍静态库的归属方法。
动态库:
类定位:先用对象查找isa指针获取类,然后使用类查找所在的可执行文件即可;
NSBundle *bundle = [NSBundle bundleForClass:objClass];
堆栈定位:获取的堆栈可以直接区分出所归属的动态库,如图:
NSArray<NSNumber *> *callAddresses = [NSThread callStackReturnAddresses];
long long callStackAddress = [callAddresses[i] longLongValue];
Dl_info info = {0};
dladdr((void *)callStackAddress, &info); //获取堆栈地址对应的可执行文件信息
NSString *dliFname = [NSString stringWithFormat:@"%s",info.dli_fname]; //取出库名
静态库:
名词解释:
Mac服务器:用于编译APP和dSYM的符号解析,以下简称Mac服务器。
日志服务器:记录线上APP上报的性能数据,以下简称日志服务器。
ASLR:全称Address spce layout randomization,地址空间布局随机化,通过对堆、栈、共享库等关键数据区域的地址空间随机化,防止攻击者直接定位代码位置来篡改程序。这种技术会使得APP或者动态库每次运行加载到内存中时的基地址都是随机的。
静态库归属常见的方案是基于dSYM的符号解析,主要流程:
???1、打包时在Mac服务器上存储所有库的dSYM文件。
???2、线上APP上报执行文件名称、发布版本、偏移量等信息。
???3、日志服务端收到APP的上报信息,通过版本号、执行文件名称查找缓存的dSYM,最后在Mac服务器上使用偏移量进行dSYM符号解析,返回静态库名。?
这种方案需要在Mac服务器上对所有动态库的所有版本dSYM进行缓存,增大了服务器的存储成本,并且由于需要三端的交互才能完成静态库的归属,稳定性较差,同时在APP运行时无法做到直接定位,可读性也不高。?
针对dSYM符号解析的问题,我们通过分析Mach-O的结构与原理,探索出了基于Mach-O的静态库归属方案,具体如下:
在编译期通过解析Mach-O和Link Map文件,生成静态库的类地址区间和汇编代码段的地址区间,在运行时根据isa指针(指向了Mach-O中的类声明地址)和代码偏移地址解析出静态库名。
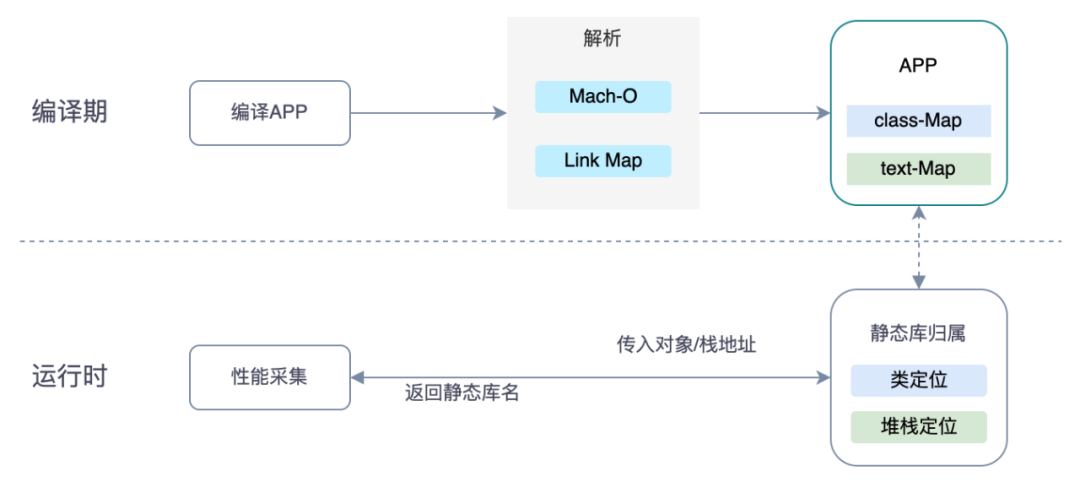
先解析Mach-O文件的结构,从Mach-O的头部开始,Header中包含了二进制文件的大小、支持的CPU类型、Load Commands的数量和大小,Segment中包括了各Section和符号表等的偏移位置和大小。
Mach-O的结构比较复杂,Segment现在已知的类型有50多种,不同类型职责不同。
该方案只用到了代码段和类列表,所以只对__text和__objc_classlist进行解析。
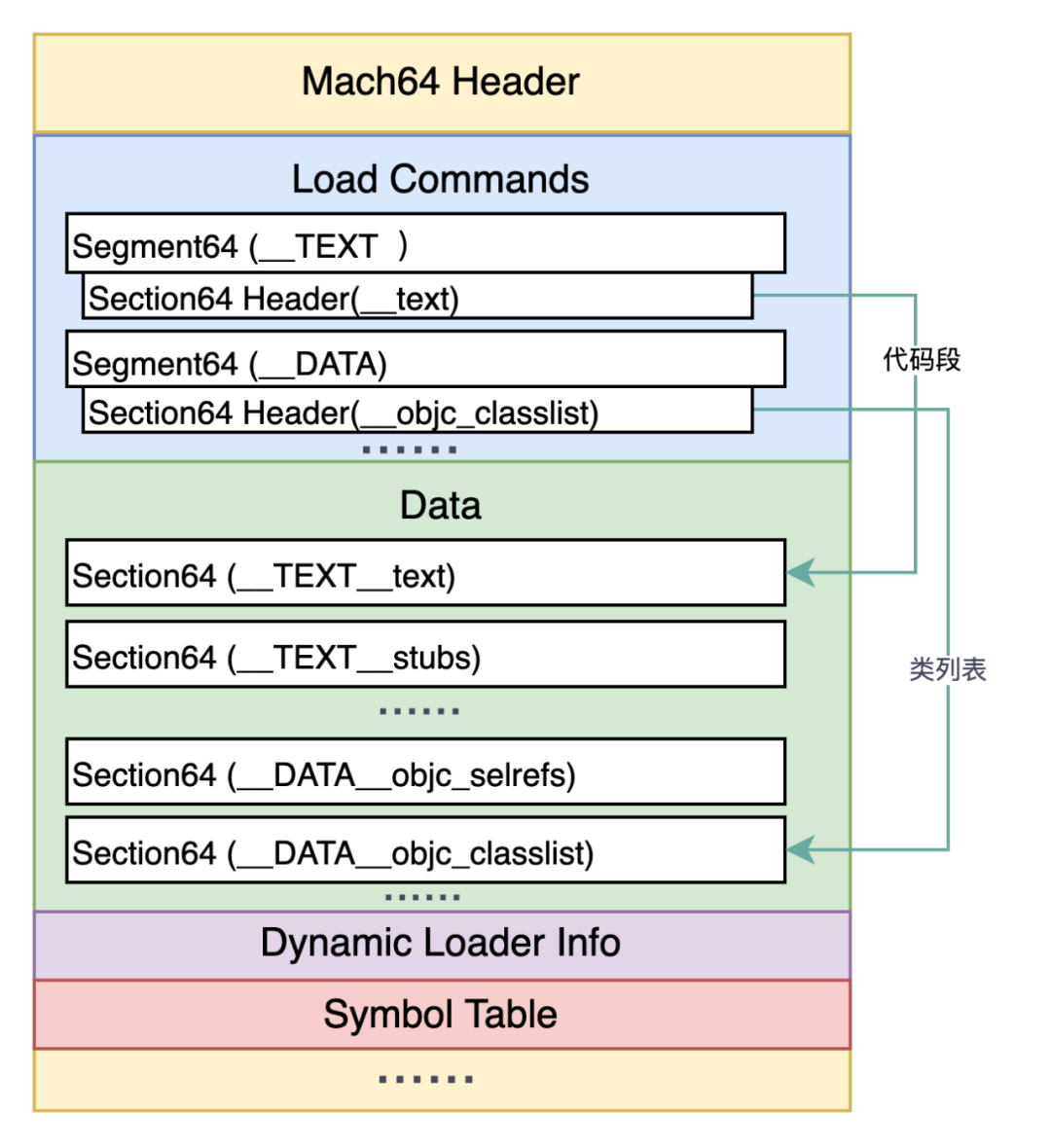
解析Mach-O头部,关键代码如下:
mach_header_64 mhHeader;
//读取头部信息
[fileData getBytes:&mhHeader range:NSMakeRange(0, sizeof(mach_header_64))];
for (int i = 0; i < mhHeader.ncmds; i++) {
load_command* cmd = (load_command *)malloc(sizeof(load_command));
//读取Load_command
[fileData getBytes:cmd range:NSMakeRange(currentLcLocation, sizeof(load_command))];
if (cmd->cmd == LC_SEGMENT_64) {
segment_command_64 segmentCommand;
[fileData getBytes:&segmentCommand range:NSMakeRange(currentLcLocation, sizeof(segment_command_64))];
NSString *segName = [NSString stringWithFormat:@"%s",segmentCommand.segname];
//提取汇编代码 __TEXT
if ([segName isEqualToString:SEGMENT_TEXT] || [segName isEqualToString:SEGMENT_BD_TEXT]) {
section_64 sectionHeader;
[fileData getBytes:§ionHeader range:NSMakeRange(currentSecLocation, sizeof(section_64))];
NSString *secName = [[NSString alloc] initWithUTF8String:sectionHeader.sectname];
}else if ([segName isEqualToString:SEGMENT_DATA]) {
//提取指定DATA sectionHeader信息
unsigned long long currentSecLocation = currentLcLocation + sizeof(segment_command_64);
}
//符号表
}else if (cmd->cmd ==LC_SYMTAB){
symtab_command tsymtabcommand;
[fileData getBytes:&tsymtabcommand range:NSMakeRange(currentLcLocation, sizeof(segment_command_64))];
symtabcommand = tsymtabcommand;
}else if(cmd->cmd == LC_FUNCTION_STARTS){
[fileData getBytes:&funcStartHeader range:NSMakeRange(currentLcLocation, sizeof(linkedit_data_command))];
}
}
如果对每个类都标记库名会使生成的ClassMap文件会过大,对包体积影响较大。通过分析APP的编译过程,发现静态库是顺序编译,在每个Section下静态库也都是分段的,所以最终通过计算每个静态库的偏移地址和大小来生成静态库的位置标记。
- 静态库类的标记:?解析Mach-O的ClassList段,借助LinkMap文件,反向解析出每个静态库的类声明位置,找到第一个类的声明地址为起始地址,最后一个类的声明地址+类声明的字节大小为类声明的结束地址。
- 静态库代码段标记:原理与查找类声明类似,结合__TEXT、Symbol Table和Function Starts, 找到静态库第一个类的第一个方法的起始地址作为库的代码段起始地址,找到静态库的最后一个类的最后一个方法的结束地址,作为静态库代码段的结束地址。
通过上面两步生成ClassMap和TextMap导入到ipa中,文件小于1kb,对APP大小几乎无影响。

生成脚本的位置要在Link?Binary With Libraries之后,Copy?bundle Resources之前。
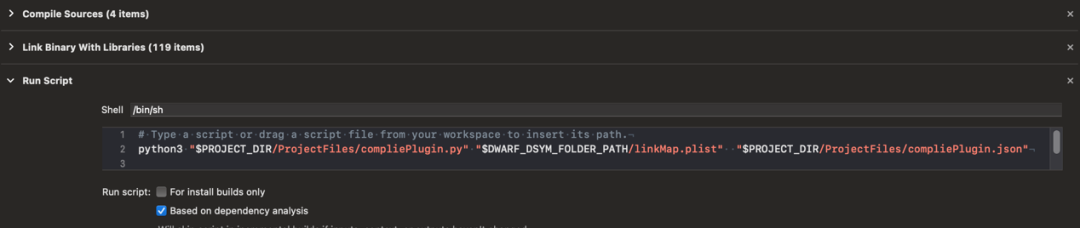
前面介绍了编译期的工作,下面介绍下运行时的定位原理。
1.运行时获取对象对应的isa指针,找到class,再通过class指针地址减去动态库加载到内存的起始地址,算出对应的偏移量(上面提到的ASLR,会使每次运行APP的内存基地址发生改变,所以需要计算偏移地址),然后使用偏移量去ClassMap中找到对应的静态库名。
NSString *imageName = [[NSString alloc] initWithUTF8String:_dyld_get_image_name(i)];
//找到APP主二进制
if (_dyld_get_image_header(i)->filetype == MH_EXECUTE &&
[imageName containsString:mainBundle.executablePath]) {
mainExecuteAddress = _dyld_get_image_vmaddr_slide(i);
break;
}
uintptr_t os = (uintptr_t)objClass;
//计算出类的偏移地址
uintptr_t classInBundleAddress = os-mainExcuteAddress;
NSDictionary *classMap = [self pluginAllAddressWithClass];
for (NSString * key in classMap.allKeys) {
NSDictionary *addressDic = classMap[key];
if (addressDic && [addressDic[@"end"] longLongValue]>classInBundleAddress && classInBundleAddress>=[addressDic[@"start"] longLongValue]) {
return key;
}
}
2.基于堆栈定位静态库。首先获取到无符号的堆栈数组,然后找到上一个调用的callback地址,检索到堆栈地址所在动态库起始地址,使用栈地址-动态库起始地址得到偏移量,再用偏移量去TextMap中找到对应的静态库名。
NSBundle *mainBundle = [NSBundle mainBundle];
Dl_info info = {0};
//获取堆栈地址对应的插件信息
dladdr((void *)callStackAddress, &info);
//获取二进制名
NSString *dliFname = [NSString stringWithFormat:@"%s",info.dli_fname];
//获取偏移量
uintptr_t callStackBundleAddress = callStackAddress-[self mainStartAddress];
NSDictionary *textMap = [self pluginAllAddressWithText];
for (NSString * key in textMap.allKeys) {
NSDictionary *addressDic = textMap[key];
//查找所属静态库
if ([addressDic[@"end"] longLongValue]>callStackBundleAddress &&callStackBundleAddress>=[addressDic[@"start"] longLongValue])
{
return key;
}
}
这样静态库的归属便可以在运行时完成,耗时小于1ms,可以大范围应用于APP各种场景中。
小结:基于Mach-O文件的动态库与静态库归属方案介绍完了,在静态库归属上,相比之前dSYM的方案,它的复杂度更低、易用性更高,可以在运行时实时解析,而且更容易迁移到其它APP上使用。
实践项目二:基于Mach-O的API的扫描
背景:在实际工作中,由于经常需要定位APP中调用过的API,为了减少重复的工作,我们实现了一套自动扫描的工具。
API扫描常见的方案是基于语法树的扫描,代码在编译时会生成语法树,通过遍历语法树可以实现API的扫描。
由于语法树扫描存在以下缺点,无法满足使用需求。
1、不支持黑盒扫描,语法树是在编译时才能生成,所以无法扫描三方SDK。
2、扫描速度太慢,语法树扫描的功能强大但是在扫描性能上较低,对2万行代码树的扫描在优化的情况下也需要1分钟左右的时间。
为了解决上面的两个问题,我们实现了基于Mach-O的API扫描方案。
实践项目一中介绍的Mach-O结构,本段落还会继续用到
__objc_classrefs:类引用列表。
__objc_selrefs:方法引用列表。
Mach-O解析的主要步骤:
1、首先解析__objc_classrefs,读取所有调用的外部API,检索被扫描API的类地址记录为class_addr。
2、解析__objc_selrefs,检索被扫描API的方法地址记录为method_addr。
3、把二进制机器码解析出汇编代码,找到所有的bl指令,计算bl指令最近的x1寄存器的值,对比x1寄存器与method_addr是否相等,相等则记录bl指令的位置。
4、在bl指令的位置向上检索是否有要找的类地址class_addr,一直检索到最近的函数入口,找到则输出结果,未找到进入第5步。
5、找到调用者类的起始和结束地址,检索起始与结束地址的所有汇编指令是否存在被扫描API的类,出现则输出结果。
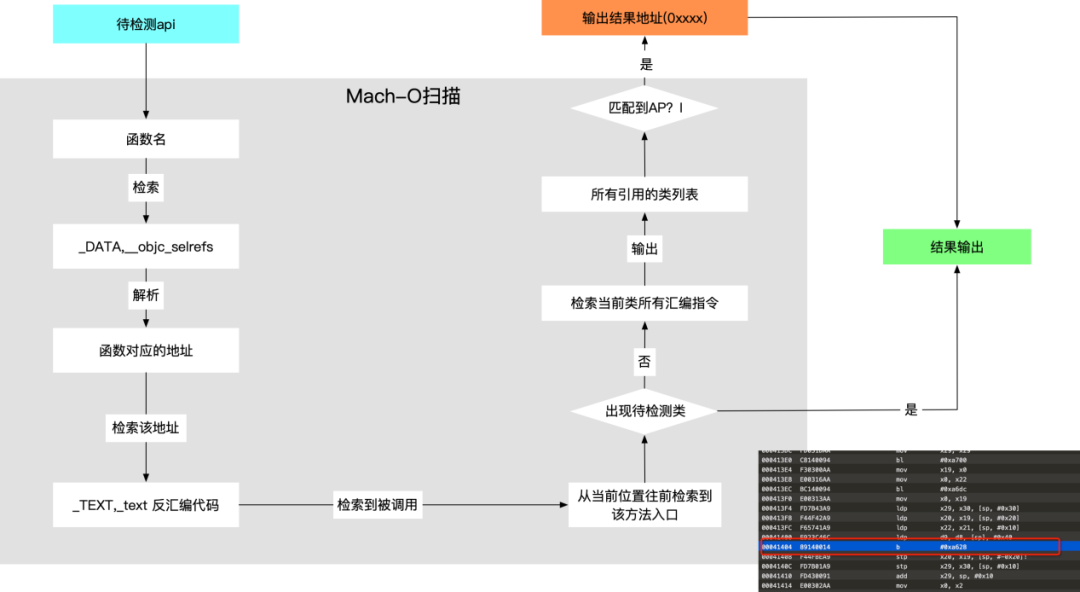
API扫描流程图
反汇编代码:
vm:(unsigned long long)vm {
mach_header_64 mhHeader;
//解析头部
[fileData getBytes:&mhHeader range:NSMakeRange(0, sizeof(mach_header_64))];
// 获取汇编代码的偏移地址和大小
char *ot_sect = (char *)[fileData bytes] + begin;
uint64_t ot_addr = vm + begin;
csh cs_handle = 0;
cs_insn *cs_insn = NULL;
cs_err cserr;
if ((cserr = cs_open(CS_ARCH_ARM64, CS_MODE_ARM, &cs_handle)) != CS_ERR_OK ) {
NSLog(@"未能初始化: %d, %s.", cserr, cs_strerror(cs_errno(cs_handle)));
return NULL;
}
// 设置解析模式
cs_option(cs_handle, CS_OPT_DETAIL, CS_OPT_ON);
cs_option(cs_handle, CS_OPT_SKIPDATA, CS_OPT_ON);
// 反汇编
size_t disasm_count = cs_disasm(cs_handle, (const uint8_t *)ot_sect, size, ot_addr, 0, &cs_insn);
if (disasm_count < 1 ) {
NSLog(@"汇编指令解析不符合预期!");
return NULL;
}
return cs_insn;
}检索方法的范围:
//检索方法偏移范围
do {
@autoreleasepool {
unsigned long long index = (end - textList.addr) / 4;
char *dataStr = s_cs_insn[index].mnemonic;
//查找是否是函数跳转指令,记录方法的开始和结束地址
if (strcmp(dataStr, "b")== 0|| strcmp(dataStr, "ret")==0) {
unsigned long long nextSymoble = end + 4;
MethodHelper *nextMethodHelper = [objectSymbolMap objectForKey:[NSNumber numberWithUnsignedLong:nextSymoble]];
if (nextMethodHelper && ![nextMethodHelper.className isEqualToString:className]){
//找到类的最后一个函数地址作为类的结束地址
callClassHelper.end = end;
return callClassHelper;
}
}
end += 4;
}
} while (end <= textList.addr + textList.size);
查找objc_msgSend调用位置,检索调用的外部方法名。
依据runtime的原理,objc_msgSend调用时x1寄存器是存放的方法地址,所以主要查找bl指令前的x1寄存器信息。
在扫描过程中发现,在调用objc_msgSend时的寄存器有时是需要ldr指令计算得出,这里涉及到汇编中高低位地址的查找。
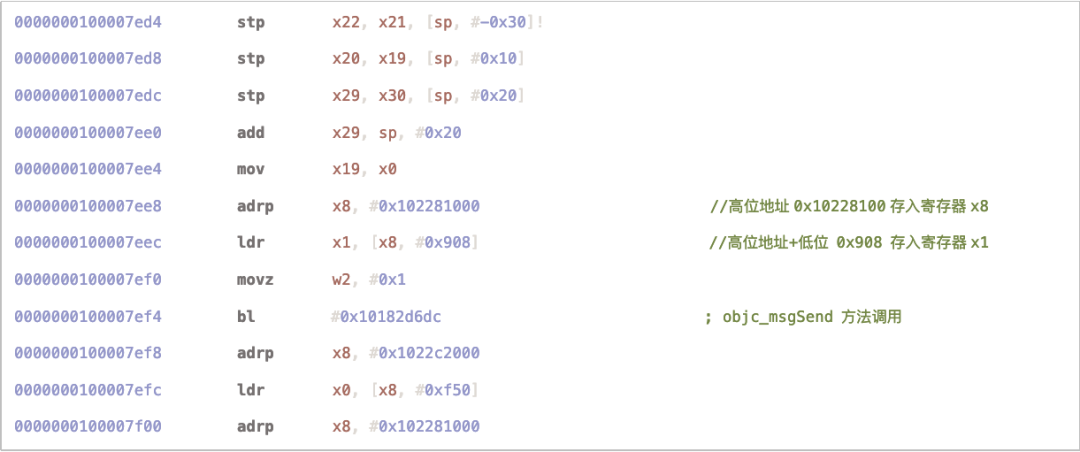
汇编指令中会把地址拆分为高低位,所以检索时要注意x1寄存器值的计算过程。如上图所示,需要计算x8寄存器+低位地址0x908,然后对比被检测API的地址与x1寄存器是否相等,最后再向上查找被检测API的类,如果匹配则输出结果。
?
小结:至此基于Mach-O的API扫描介绍完了,Mach-O的扫描方式相比传统的语法树扫描,在本质上脱离了代码,可以对任意的动态库和静态库进行扫描,而且扫描过程可以采用多线程分段扫描进行提速,能够在2秒内完成对3万行代码编译产物的扫描,相比语法树扫描在速度上有20倍以上的提升。
在语言上除了对OC方法的扫描,还支持Swift、C方法的扫描,原理与OC扫描类似,这里就不做详细介绍。
总结与展望:
以上是基于Mach-O结构的动态库与静态库的归属和API的扫描方案,已应用于生产环境,助力团队降本提效。
未来我们还会持续在以下方面进行探索与实践:
1、扩展归属检索的范围,如类别、block、常量、C方法等。
2、API使用规范的扫描,基于Mach-O生成简易的调用关系图来查看API的规范情况,可扫描冲突的分类方法,提前发现隐藏的bug。
3、安全方面:防止反编译、动态注入。
参考文档:
Overview of the Mach-O Executable Format (apple.com)
Introduction (apple.com)
