英特尔详细介绍Ponte Vecchio 性能可达英伟达A100平台的2.5倍
在 Hot Chips 34 大会期间,英特尔再次详细介绍了 Sapphire Rapids HBM 处理器 + Ponte Vecchio(2-Stack)GPU 平台的潜力,称该服务器平台的性能可达英伟达 A100 竞品的 2.5 倍。英特尔首席 GPU 计算架构师 Hong Jiang 在演讲中指出,Ponte Vecchio 具有三种配置。

(via?WCCFTech)
从单一 OAM、到配备 Xe Links 的 x4 子系统,Ponte Vecchio GPU 不仅能够单独运行、也可部署于 Sapphire Rapids 双路服务器平台之上。

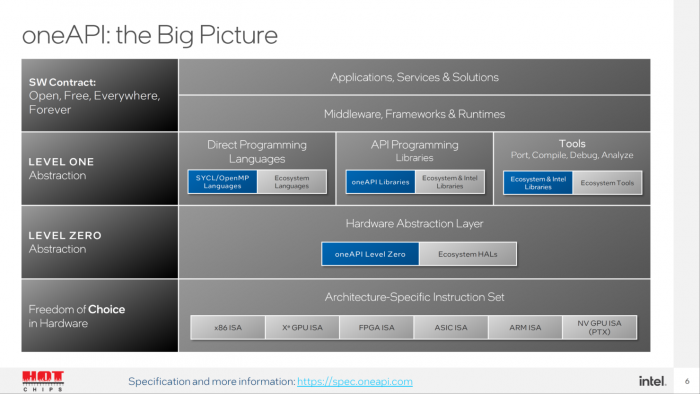
其中 OAM 支持 4 GPU 和 8 GPU 平台的 all-to-all 拓扑,辅以英特尔 oneAPI 软件堆栈。
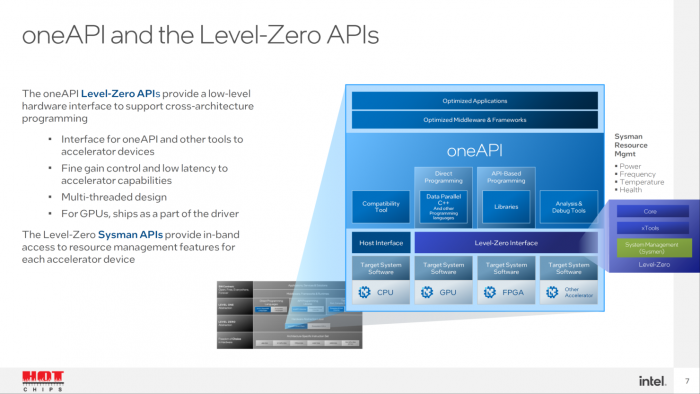
作为一个零级(Level Zero)API,其为跨架构编程支持提供了低层级的硬件接口。
oneAPI 主要特性如下:
● 提供面向其它工具和加速器设备的接口;
● 支持精细的增益控制、以及低延迟的加速器特性;
● 具有多线程设计;
● 将 GPU 作为驱动程序的一部分而提供。

性能指标方面,2-Stack Ponte Vecchio GPU 配置(如单一 OAM 上的配置),可提供高达 52 TFLOP 的 FP64 / FP32 算力。
另有 419 TFLOP 的 TF32(XMX Float 32)、839 TFLOP 的 BF16 / FP16,以及 1678 TFLOPs 的 INT8 算力。
英特尔还详细说明了 Ponte Vecchio 的缓存大小 / 峰值带宽 —— 比如 GPU 上的寄存器为 64 MB,提供 419 TB/s 的带宽。
L1 缓存也为 64 MB,带宽 105 TB/s(4:1)。L2 缓存为 408 MB,带宽 13 TB/s(8:1)。HBM 内存池高达 128 GB,辅以 4.2 TB/s(4:1)的带宽。

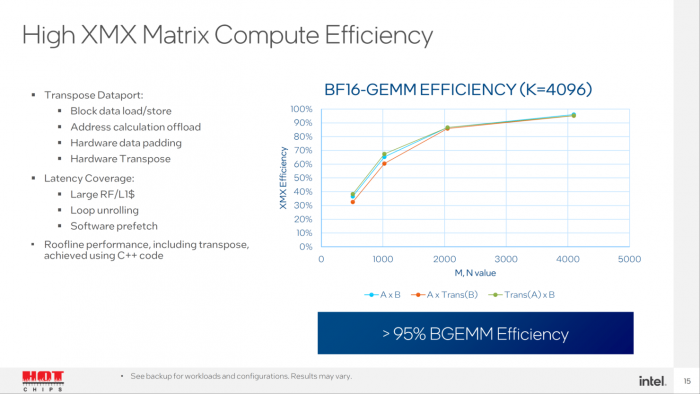
以下是英特尔为 Ponte Vecchio 配备的系列计算效率(compute efficiency)技术。
Register File(寄存器文件):
● Register Caching(寄存器缓存)
● Accumulators(累加器)

L1 / L2 Cache:
● Write Through(直写)
● Write Back(回写)
● Write Streaming(流式写入)
● Uncached(不缓存)

Prefetch(预取):
● 支持 L1 和(或)L2 缓存的软件(指令)预取;
● 支持到 L2 获取指令和数据的 Command Streamer 预取。

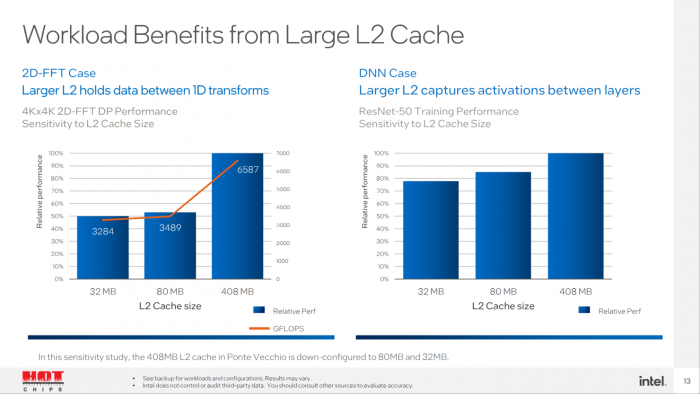
英特尔解释称,更大的 L2 缓存,可为 2D-FFT 和 DNN 等工作负载带来巨大的效益,并且分享了完整 Ponte Vecchio GPU 和 80 / 32 MB 模块之间的一些性能比较。
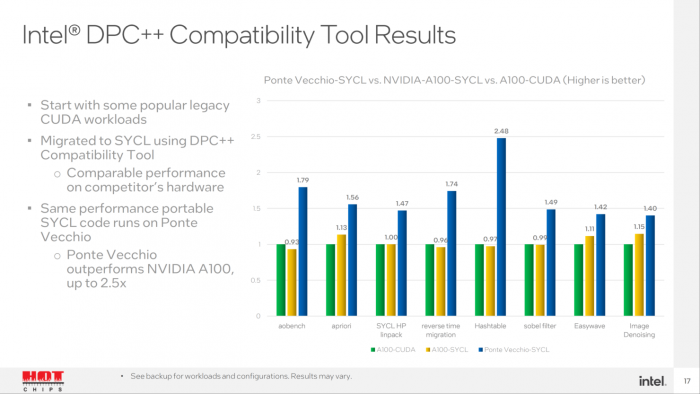
此外英特尔搬出了运行 CUDA 和 SYCL 的英伟达 Ampere A100,与使用 SYCL 的 Ponte Vecchio GPU 平台展开了性能横比。
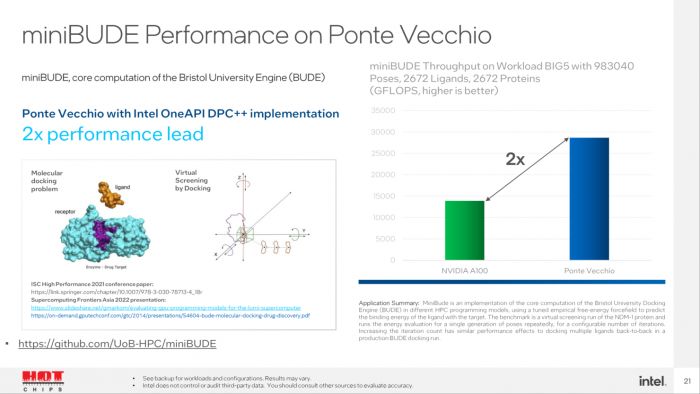
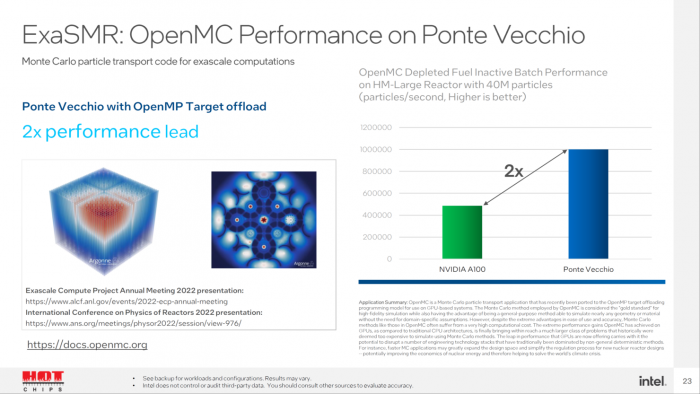
在 miniBUDE(一种可预测配体与目标结合能的计算工作负载)中,Ponte Vecchio GPU 模拟测试结果的速度,更是 Ampere A100 的 2 倍。
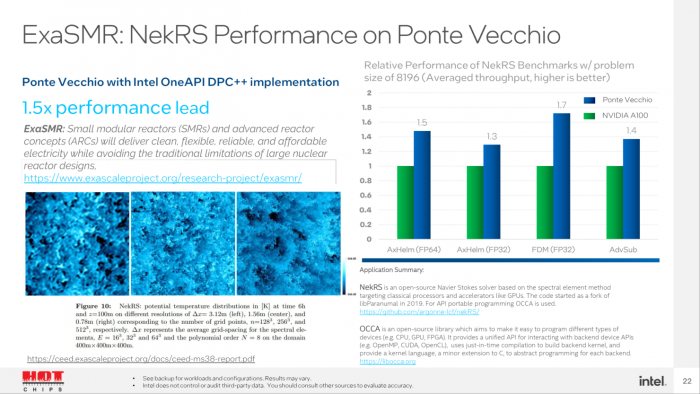
另外在 ExaSMR 核反应堆设计仿真设计中,英特尔 Ponte Vecchio GPU 也以 1.5 倍领先于英伟达竞品方案。
不过需要指出的是,英伟达早已向市场投放了性能更加强悍的 Hopper H100,所以英特尔这里拿 Ampere A100 进行比较还是相当投机取巧的。
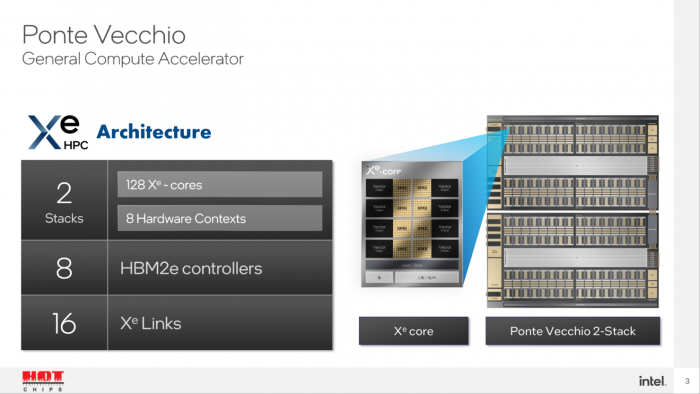
言归正传,英特尔概述了 Ponte Vecchio 旗舰数据中心 GPU 的一些关键特性,例如 128 个 Xe 内核、128 个光追(RT)单元、HBM2e 显存、以及连接到一起的 8 个 Xe-HPC GPU 。
该芯片在两个独立的堆栈中提供了高达 408 MB 的 L2 缓存、之间通过 EMIB 互连,且各部分芯片混用了 Intel 7 和台积电 N7 / N5 等多个工艺节点。
由两块(2 Tiles)组成的每个堆栈有 16 裸片,最大的 active die 尺寸为 41 m㎡、Compute Tile 则是 650 m㎡ 。
以下是 Ponte Vecchio GPU 的完整小芯片 / 工艺节点描述:
● 英特尔 7nm
● 台积电 7nm
● Foveros 3D 封装
● EMIB 互连
● 10nm 增强型 Super Fin
● Rambo Cache
● HBM2 高带宽显存
以下是英特尔 Ponte Vecchio 芯片的 47 块(Tiles)组成:
● 16 个 Xe HPC(内/外部)
● 8 个 Rambo Cache(内部)
● 2 个 Xe Base(内部)
● 11 个 EMIB(内部)
● 2 个 Xe Link(外部)
● 8 个 HBM(外部)
Ponte Vecchio GPU 使用了 8 个 HBM 8-Hi 堆栈,总共包含 11 个 EMIB 互连,完整封装尺寸为 4843.75 m㎡ 。

设计中还提到了高密度 3D Forveos 封装的 Meteor Lake CPU,可知其 bump pitch 的间距为 36u 。

【总结】Ponte Vecchio GPU 不是一个单独的芯片,而是由 47 个不同工艺制程的小芯片“组合”得来。

遗憾的是,受英特尔多次跳票的影响,使用 Ponte Vecchio GPU 和 Sapphire Rapids CPU 的 Aurora 超级计算机项目也被迫推迟。

即便如此,英特尔还是透露了下一代 Rialto Bridge GPU 。可知作为 Ponte Vecchio GPU 的继任者,其有望于 2023 年开始提供样品。
