NVIDIA在Hot Chips 2022上公布更多Grace信息
数据中心 AI供应商NVIDIA 本周在 Hot Chips 2022 研讨会上展示了公司更多产品的详细信息,包括即将推出的Grace CPU 架构、用于 HPC(高性能计算)和云工作负载的 Grace Superchip 实施,以及用于大规模 AI 训练的Grace Hopper架构——包括Grace CPU和 Hopper GPU的集成。这些新的 NVIDIA 多芯片模块产品标志着该公司首次涉足数据中心和超级计算核心 CPU 技术,并融合了其GPU技术。这也是数据中心中基于 Arm 的架构的一个重要里程碑。
剖析 NVIDIA 的超级芯片——Grace
NVIDIA 的 Grace CPU 架构基于 Arm Neoverse 内核和 ArmV9 指令集。Grace 的架构已针对可扩展性、共享内存和缓存一致性进行了高度优化,而Arm架构在业界获得了 NVIDIA 等主要芯片厂商的极大关注。
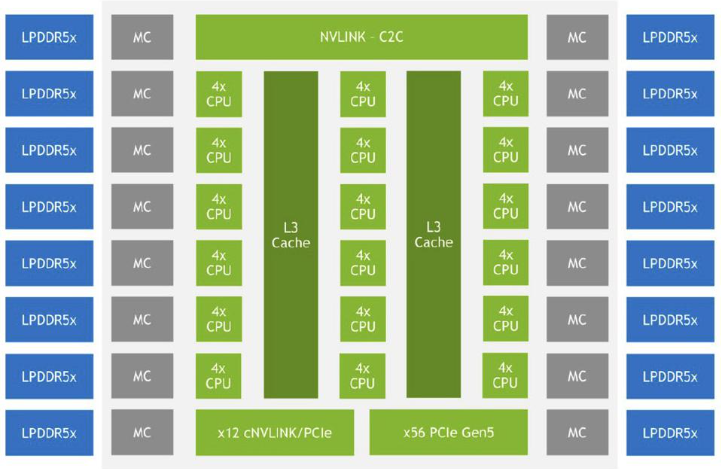
72 核 NVIDIA Grace CPU 框图
Grace 核心 CPU 组合由72核和117MB分布式缓存组成,并且可以在单个 Grace Superchip 中扩展到 144 个核心(234MB 缓存),或在 Grace Hopper中扩展至 72 个核心并与Hopper GPU集成——它们都与 NVIDIA的Scalable Coherency Fabric(SCF)连接在一起,SCF 提供网状结构架构和分布式缓存设计,带宽高达 32 TB/s。
通过 NVIDIA 的 NVLink-C2C 高速芯片到芯片互连实现进一步扩展,该互连在单个封装(Grace Superchip 或 Grace Hopper)中的提供 900 GB/s 的双向带宽,并通过 SCF 进一步扩展至四个插槽,以支持跨插槽的一致性。它还允许在 Grace Hopper 实现中扩展 GPU 内存池,允许 Hopper 通过 NVLink 网络直接访问连接到 Grace 的 LPDDR5X 内存。
总而言之,NVIDA 的 Grace 不仅为现代数据中心、云、人工智能和 HPC 工作负载采用了尖端的 Arm 核心架构,而且它具有非常强大的总线,可实现最大的芯片间通信和可扩展性。
NVIDIA Grace Hopper
虽然 Grace Superchip 针对更通用的 HPC 和云工作负载进行了优化,但 NVIDIA 的 Grace Hopper 组合 Superchip 通过 NVLink-C2C 在单个模块上将 72 核 Arm CPU 核心与 NVIDIA Hopper GPU 结合在一起。该芯片以美国海军上将和计算机编程先驱 Grace Hopper 命名,针对更密集的 HPC 和 AI 训练工作负载进行了优化,具有共享内存和一致性。
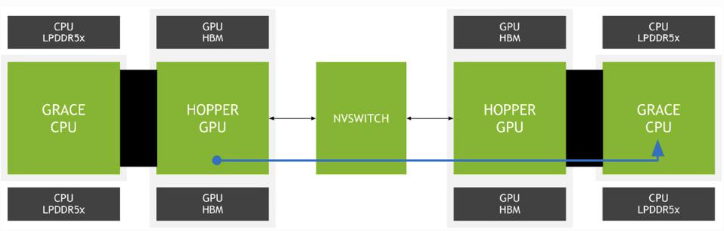
Hopper GPU 可以使用 NVLink-C2C 访问远程 Grace CPU 的内存
Hopper GPU 也可以通过 NVLink-C2C 访问相邻 Grace CPU 的内存。与向 Hopper GPU 模块添加昂贵的 HBM2e 内存相比,这节省了成本,并显着扩展了内存容量,同时还保持了更高的能效,适用于不一定需要 HBM2 提供大带宽的工作负载。
预期、市场影响和关键要点
NVIDIA 在其 Grace 和 Grace Hopper Superchip 性能方面做出了大胆的声明,到 2023 年上半年,NVIDIA 的 Grace Superchips将成为数据中心高度可扩展的 ArmV9 架构的主要参与者。其他参与者,包括 128 核“云原生”处理器的 Ampere Computing。
随着 HPE、Google Cloud 和 Microsoft Azure 等主要 OEM 宣布承诺提供基于 Arm 的解决方案,NVIDIA 在市场扩展机遇上将会做得更好。
