深度解读特斯拉自研芯片架构
对于一家自动驾驶电动汽车制造商来说,花费数亿美元从头开始创建自己的人工智能超级计算机,超大规模人工智能训练的成本和难度有多大?公司创始人必须多么自负和肯定才能组建一支能够做到这一点的团队? 像许多问题一样,当您准确地提出这些问题时,他们往往会自己回答。很明显,SpaceX 和特斯拉的创始人兼 OpenAI 联盟的联合创始人埃隆马斯克没有时间或金钱浪费在科学项目上。 就像世界上的超级大国低估了完全模拟核导弹及其爆炸所需的计算能力一样,也许自动驾驶汽车的制造商开始意识到,在复杂的世界中教汽车自动驾驶这种情况总是在变化,这将需要更多的超级计算。一旦你接受了这一点,你就可以从头开始,建造合适的机器来完成这项特定的工作。

简而言之,这就是特斯拉的 Project Dojo 芯片、互连和超级计算机工作的全部内容。
在Hot Chips 34大会上,曾在Dojo超级计算机上工作的芯片、系统和软件工程师首次公开了该机器的许多架构特性,并承诺将在特斯拉AI日上谈论Dojo系统的性能。
Emil Talpes 在 AMD 工作了近 17 年,研究各种 Opteron 处理器以及命运多舛的“K12”Arm 服务器芯片,他介绍了他的团队创建的 Dojo 处理器。Debjit Das Sarma 则同期在 AMD 担任 CPU 架构师,他在演讲中受到赞誉,目前是特斯拉的自动驾驶硬件架构师,Douglas Williams 也是如此,我们对他一无所知。这家汽车制造商的首席系统工程师 Bill Chang 在 IBM Microelectronics 工作了 15 年,设计 IP 模块并致力于制造工艺,然后帮助 Apple 将 X86 处理器转移到自己的 Arm 芯片上,而Rajiv Kurian一开始在特斯拉工作,然后在Waymo工作。据我们所知,在去年 8 月的 Tesla AI Day 1 上发言特斯拉自动驾驶硬件高级总监Ganesh Venkataramanan负责Dojo项目。过去十五年里,Venkataramanan 还是 AMD CPU 设计团队的领导者。
所以以一种奇怪的方式,Dojo 代表了一个可替代的人工智能未来,如果特斯拉来帮助从头开始设计定制的人工智能超级计算机,从全新核心内核中的向量和整数单元一直到一个完整的 exascale 系统,专为 AI 训练用例的规模化和易于编程而设计。
与来自 AI 初创公司的许多其他相对较新的平台一样,Dojo 设计优雅而彻底。最引人注目的是特斯拉工程师在关注规模时抛出的东西。
“我们应用定义的目标是可扩展性,”Talpes 在演讲结束时解释道。“我们不再强调典型 CPU 中的几种机制,例如一致性、虚拟内存和全局查找目录,因为当我们扩展到非常大的系统时,这些机制不能很好地扩展。相反,我们依赖于整个网格中非常快速且非常分布式的 SRAM 存储。与典型分布式系统相比,互连速度高出一个数量级。”
基于此,让我们深入了解 Dojo 架构。
根据 Talpes 的说法,Dojo 核心有一个整数单元,它从 RISC-V 架构中借用了一些指令,并且有一大堆特斯拉自己创建的附加指令。矢量数学单元“主要由特斯拉从头开始实现”,Talpes 没有详细说明这意味着什么。他确实补充说,这个自定义指令集针对运行机器学习内核进行了优化,我们认为这意味着它不会很好地运行孤岛危机。

Dojo 指令集支持 64 位标量指令和 64 B SIMD 指令,它包括处理从本地内存到远程内存传输数据的原语(primitives),并支持信号量(semaphore)和屏障约束( barrier constraints),这是使内存操作符合指令不仅在 D1 内核中运行,而且在 D1 内核的集合中运行。至于特定于 ML 的指令,有一组通常在软件中完成的 shuffle、transpose 和 convert 指令,现在蚀刻在晶体管中,核心还进行随机舍入( stochastic rounding ),可以进行隐式 2D 填充(implicit 2D padding),即通常通过在一条数据的两侧添加零来调整张量来完成。
Talpes 明确表示,D1 处理器是我们推测的 Dojo 芯片和系统系列中的第一个,是“高吞吐量、通用 CPU”,它本身并不是加速器。或者更准确地说,Dojo 的架构旨在加速自身,而不需要一些外部设备来完成。
每个 Dojo 节点都有一个内核,是一台具有 CPU 专用内存和 I/O 接口的成熟计算机。这是一个重要的区别,因为每个内核都可以做自己的事情,而不依赖于共享缓存或寄存器文件或任何东西。
D1 是一个超标量(superscalar)内核,这意味着它在其内核中支持指令级并行性,就像当今大多数芯片一样,它甚至具有多线程设计来驱动更多指令通过该内核。但是多线程更多的是每时钟做更多的工作,而不是拥有可以将独立的 Linux 实例作为虚拟机运行的独立线程,因此同步多线程 (SMT) 的 Dojo 实现没有虚拟内存,保护机制有限,并且Dojo 软件堆栈和应用程序管理芯片资源的分配。
D1 内核是一个 64 位处理器,具有 32 B 的取指窗口( fetch window),最多可容纳 8 条指令;一个八宽解码器每个周期可以处理两个线程。这个前端馈入( front end feeds into)一个四宽标量调度器(four-wide scalar schedule),该调度器具有四路 SMT,它有两个整数单元、两个地址单元和一个用于每个线程的寄存器文件。还有一个带有四路 SMT 的两侧向量调度器,它馈送到一个 64 B 宽的 SIMD 单元或四个 8x8x4 矩阵乘法单元。
每个 D1 内核都有一个 1.25 MB 的 SRAM,这是它的主存储器。它不是缓存,如果有的话,挂在更大的 Dojo 网络上的 DDR4 内存被视为比其他任何东西都更像大容量存储。该 SRAM 可以以 400 GB/秒的速度加载并以 270 GB/秒的速度存储,并且该芯片具有明确的指令,可以将数据移入或移出 Dojo 机器中其他内核的外部 SRAM 存储器。嵌入在该 SRAM 中的是一个列表解析器引擎(list parser engine),该引擎馈入解码器对和一个收集引擎(gather engine),馈入向量寄存器文件,它们一起可以将信息发送到其他节点或从其他节点获取信息,而无需像与其他 CPU 架构。
这个列表解析功能是 Dojo 芯片设计独有的关键特性之一:

这本质上是一种封装不同数据位的方法,以便可以在系统中的 D1 内核之间高效传输。
D1 内核支持多种数据格式。标量单元支持 8、16、32 或 64 位的整数,而向量单元及其关联的矩阵单元支持多种数据格式,具有精度和数值范围的混合,其中不少是动态的可由 Dojo 编译器组合。
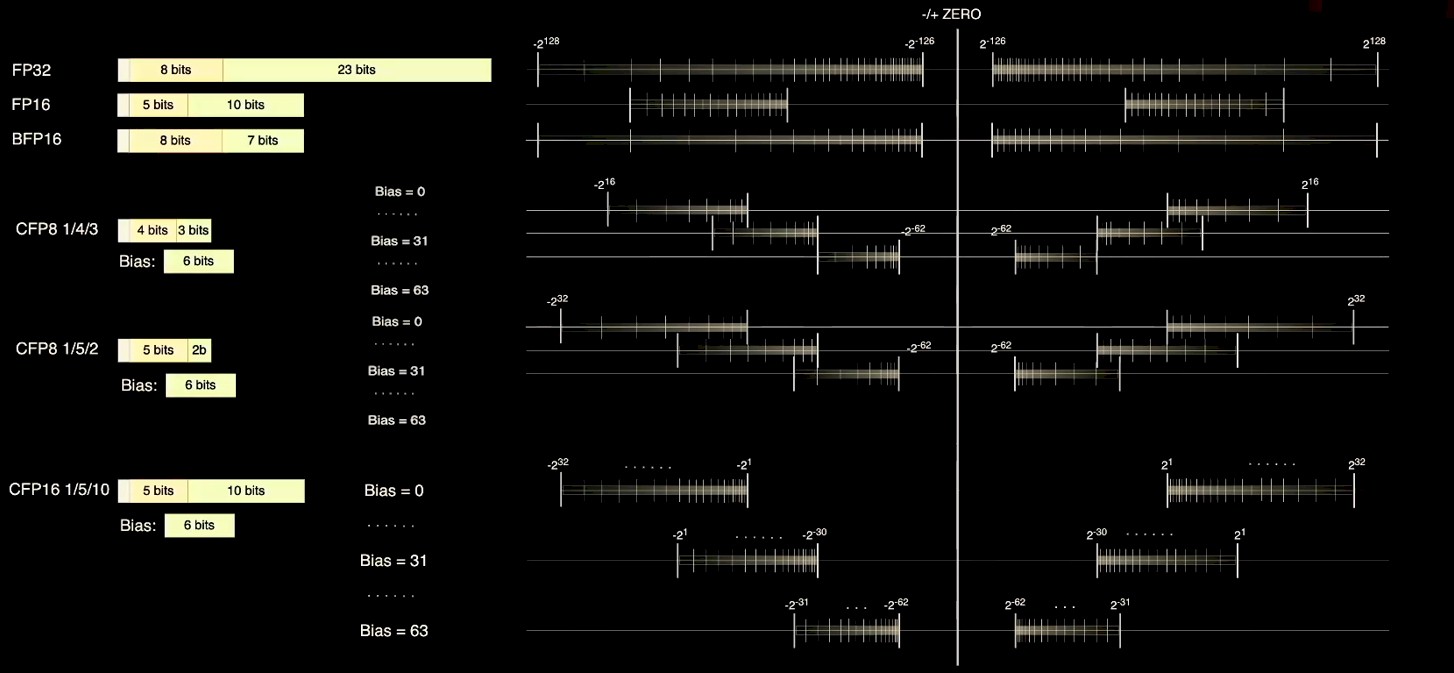
Talpes 指出,FP32 格式比 AI 训练应用的许多部分所需的精度和范围更广,IEEE 指定的 FP16 格式没有足够的范围覆盖神经网络中的所有处理层;相反,Google Brain 团队创建的 Bfloat 格式范围更广,但精度更低。因此,Tesla 不仅提出了用于较低精度和更高吞吐量矢量处理的 8 位 FP8 格式,而且还提出了一组可配置的 8 位和 16 位格式,Dojo 编译器可以在尾数的精度附近滑动和上图所示的指数,以涵盖更广泛的范围和精度。在任何给定时间,最多可以使用 16 种不同的矢量格式,但每个 64 B 数据包必须属于同一类型。
在图的右上角,您将看到片上网络路由器( network on chip router),它将多个核心连接在一起形成一个 2D 网格。NOC 可以处理跨节点边界的 8 个数据包(boundary),每个方向 64 B,每个时钟周期,即在所有四个方向上一个数据包输入和一个数据包输出到网格中每个核心最近的邻居。该路由器还可以在每个周期对本地 SRAM 进行一次 64 B 读取和一次 64 B 写入,因此可以在内核之间移动数据。
这些都在在D1 核心上完成所有蚀刻,是由其代工合作伙伴台积电以 7 纳米工艺完成的。之后,特斯拉开始复制 D1 核心并将它们互连网格,像这样:
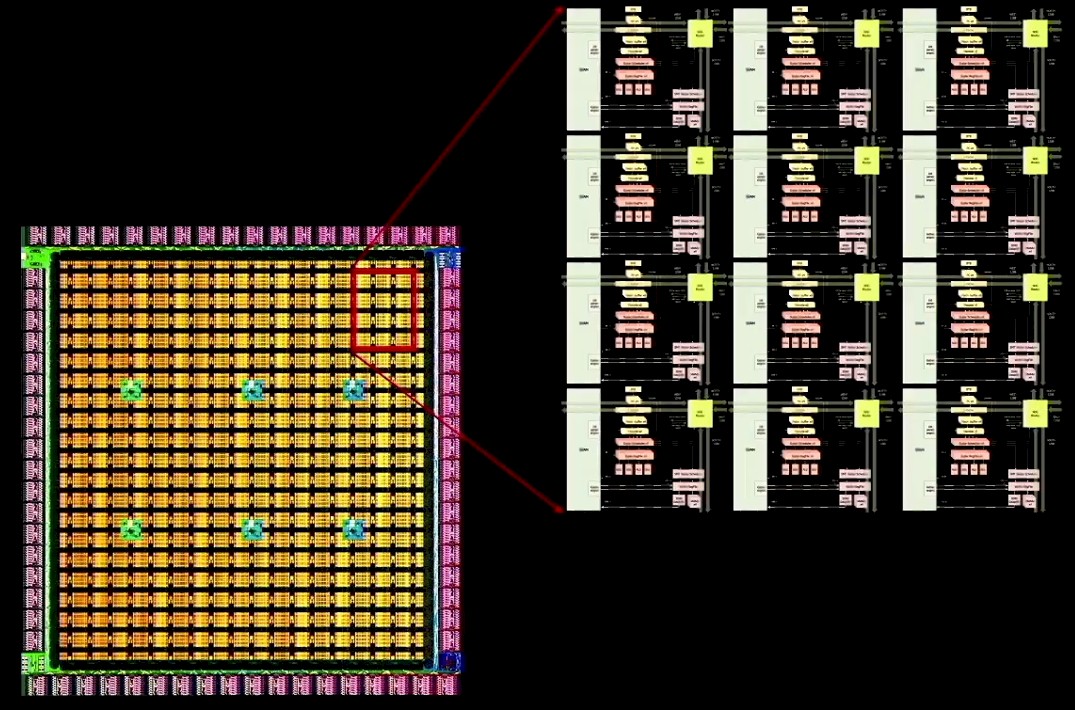
十几个 D1 核心排列成一个本地块,创建了一个 18 核心乘 20 核心的二维阵列,但由于某种原因,只有 354 个 D1 核心可用。D1 芯片以 2 GHz 运行,在这些内核上共有 440 MB 的 SRAM,在 BF16 或 CFP8 上提供 376 teraflops,在 FP32 上提供 22 teraflops。向量单元中没有 FP64 支持。如此多的 HPC 工作负载无法在此 D1 芯片上运行,一些使用 64 位矢量数学的 AI 应用也不会。特斯拉不需要关心——它只需要运行自己的人工智能应用程序,如果它想在 D2 或 D3 芯片上添加 FP64 支持来运行其 HPC 模拟和建模工作负载,以便马斯克的公司可以设计宇宙飞船和汽车,好吧,在完成所有这些工作之后,这相当容易。
D1 die 有 576 个双向 SerDes 通道,围绕在 die 周围以链接到其他 D1 die,并且 D1 die 的所有四个边缘的带宽为 8 TB/秒。这些芯片重达 645 平方毫米,可通过这些 SerDes 无缝连接到特斯拉所谓的 Dojo 训练模块中。像这样:

训练tile采用 25 个已知良好的 D1 裸片,并将它们打包成一个 5×5 阵列,相互连接。训练tile的外部边缘在 40 个 I/O 芯片上实现了 36 TB/秒的聚合带宽;这是 2D 网格的网格的二分带宽的一半,它跨越了 tile 内的 D1 芯片。该tile具有 10 TB/秒的块上二分带宽,以及跨内核的 11 GB SRAM 内存。每个 tile 提供 9 petaflops 的 BF16/CFP8 魅力。
那些Dojo训练tile消耗15千瓦,显然是水冷的,它们的设计使得多个训练tile可以与相邻tile互连。目前尚不清楚这是如何发生的,但很明显,您需要一排相互连接的tile,水平或垂直方向,而不是带有几个设备托盘的单独机架,然后需要某种巨大比例的光缆或电缆,围绕在tile之间承载数据。垂直工作,如下所示:
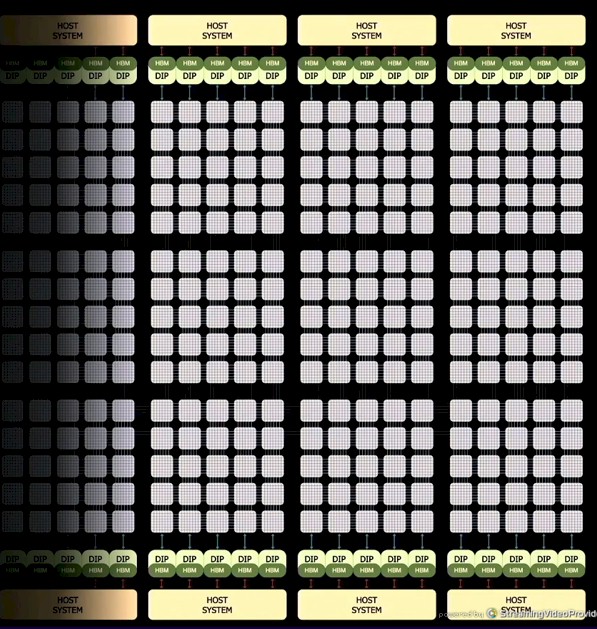
您将在上图中注意到,在 D1 网格的边缘有所谓的 Dojo 接口处理器或 DIP,它们连接到 D1 网格以及为 DIP 供电并执行各种系统管理的主机系统功能。每个训练tile总共有 11 GB 的私有 SRAM 主内存,但系统需要某种更大的内存,该内存合理地靠近网格。在这种情况下,Tesla 选择创建一个 DIP 内存和 I/O 协处理器,其中包含 32 GB 共享 HBM 内存——我们还不知道是哪种,但它是 HBM2e 或 HBM3——以及以太网接口到外部世界以及在tile和核心之间进行比通过这个巨大的网格更直接的跳跃。图片显示一对主机安装了十个这样的 DIP,每组三个 Dojo 训练图块总共有 320 GB 的 HBM 内存。但图表上的措辞表明,每个 tile 分配了 160 GB,这意味着每个 tile 一个主机,而不是此处显示的三个 tile 两个主机。

该 DIP 卡有两个 I/O 处理器,每个处理器带有两个 HBM 内存组,该卡提供 32 GB 的 HBM 内存和 800 GB/秒的带宽。对我们来说,这看起来像是稍微降低了 HBM2e 内存。该卡通过 PCI-Express 实现了 Tesla 传输协议 (TTP:Tesla Transport Protocol ),这是一种专有互连,对我们来说这有点像 CXL 或 OpenCAPI,以将完整的 DRAM 内存带宽提供给 Dojo 训练块。在卡的另一端,有一个 50 GB/秒的 TTP 协议链路在以太网 NIC 上运行,它连接到现有的以太网交换机,该交换机可以是单个 400 Gb/秒端口或成对的 200 Gb/秒端口。DIP 插入 PCI-Express 4.0 x16 插槽,每张卡提供 32 GB/秒的带宽。每个磁贴边缘有 5 个卡,有 160 GB/秒的带宽进入主机服务器和 4 个。
正如我们已经指出的那样,DIP 不仅将 DRAM 实现为fat本地存储,而且还提供了另一种网络维度,可用于绕过 2D 网格,而需要大量跃点才能跨越所有这些核心和tile。像这样:

Chang 表示,在整个系统中通过 2D 网格实现端到端可能需要 30 hops,但使用 TTO over Ethernet 协议和fat tree Ethernet 交换机网络,只需要 4 hops。显然,带宽要低得多,但在网络的第三维(因此是 Z 平面)上的延迟要低得多。
Dojo V1 训练矩阵是 Tesla 正在构建的基础系统,它有 6 个训练tile、4 个主机服务器上的 20 个 DIP,以及一组连接到以太网交换结构的辅助服务器,如下所示:
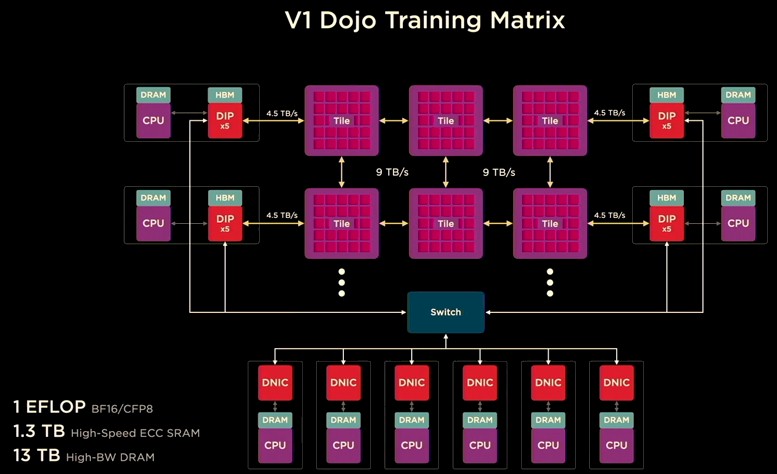
基础 Dojo V1 系统有 53,100 个 D1 内核,在 BF16 和 CFP8 格式下的额定速度为 1 exaflops,在 Tile 上有 1.3 TB 的 SRAM 内存,在 DIP 上有 13 TB 的 HBM2e 内存。完整的 Dojo ExaPod 系统共有 120 个tile,将有 1,062,000 个可用的 D1 内核,重量为 20 exaflops。
顺便说一句,这个东西运行 PyTorch。没有像 C 或 C++ 那样低级的东西,也没有像 CUDA 这样的远程。Dojo 机器的另一个巧妙之处在于 SRAM 将自身呈现为单个地址空间。它是一个平坦的内存区域,本地计算悬挂在其内存块上。
我们期待看到 Dojo 在 AI 基准测试中的表现。
