MLFlow打包和部署机器学习模型实战 译文 精选
译者? | 朱先忠
审校 | 孙淑娟
简介
ML模型生命周期开发每个阶段的基本活动之一是协作。从ML模型的概念到部署,需要构建模型所涉及的不同角色之间的参与和交互。此外,ML模型开发的本质涉及实验、工件(artifacts)和指标的跟踪、模型版本管理等,所有这些都需要通过一种有效的组织来正确维护ML模型生命周期。
幸运的是,目前已经出现类似于MLflow这样的开发和维护模型生命周期的工具。在本文中,我们将详细剖析MLflow,包括其主要组件及特性等内容的分析。此外,我们还将提供示例来说明MLflow在实践中是如何工作的。
什么是MLflow?
MLflow是一个开源工具,用于在ML模型生命周期的每个阶段进行开发、维护和协作。此外,MLflow是一个与框架无关的工具;因此,任何ML/DL(机器学习/深度学习)框架都可以快速适应MLflow提出的生态系统。
MLflow是作为一个平台的形式出现的,其中提供了跟踪指标、工件和元数据等的一系列工具。此外,它还提供了打包、分发以及部署模型和项目等的标准格式支持。
MLflow还提供了管理模型版本的工具。这些工具分别封装在下面四个主要组件中:
- MLflow跟踪(Tracking)
- MLflow模型(Models)
- MLflow项目(Projects)
- MLflow注册表(Registry)
MLflow跟踪
MLflow跟踪是一种基于API的工具,用于记录指标、参数、模型版本、代码版本和文件。MLflow跟踪与一个UI集成到一起,用于可视化和管理工件、模型、文件等。
其中,每个MLflow跟踪会话都是在运行(run)的概念下组织和管理的。运行是指代码的执行;其中,工件日志部分是被显式执行的。
MLflow跟踪允许您通过MLflow提供的Python、R、Java等语言以及REST形式的API等方式来生成运行。默认情况下,运行是存储在执行代码会话的目录中。然而,MLflow还允许在本地或远程服务器上存储工件。
MLflow模型
MLflow模型允许将机器学习模型打包成标准格式,以便通过REST API、Microsoft Azure ML、Amazon SageMaker或Apache Spark等不同服务直接使用。MLflow模型协定的优点之一是包装是多语言或多风味(flavor)支持的。
[译者注]MLflow中经常遇到“flavor”一词,其主要是指对于多种语言、多种类型组件及库的广泛支持,通过下面展示的配置文件容易看出这一点。在此,本文统一直接翻译为“风味”。
在打包方面,MLflow生成一个包含两个文件的目录,一个是模型,另一个是指定模型打包和加载细节的文件。例如,下面的代码片段显示了一个MLmodel文件的内容,其中指定了风味加载器(flavor loader)以及定义环境的“conda.yaml”文件。
artifact_path: model
flavors:
python_function:
env: conda.yaml
loader_module: MLflow.sklearn
model_path: model.pkl
python_version: 3.8.2
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 0.24.2
run_id: 39c46969dc7b4154b8408a8f5d0a97e9
utc_time_created: '2021-05-29 23:24:21.753565'
MLflow项目
MLflow项目提供了打包、共享和重用机器学习项目的标准格式。每个项目可以是远程存储库或本地目录。与MLflow模型不同,MLflow项目旨在实现机器学习项目的可移植性和分布性。
MLflow项目由名为“MLProject”的一个YAML声明文件来定义,其中公开了相应项目的一系列规范内容。
模型实现的关键特征在MLProject文件中指定,这些特征包括:
- 模型接收的输入参数
- 参数的数据类型
- 用于执行所述模型的命令,以及
- 项目运行的环境
下面的代码片段显示了一个MLProject文件的示例,其中要实现的模型是一棵决策树形式,其唯一的参数对应树的深度,默认值为2。
name: example-decision-tree
conda_env: conda.yaml
entry_points:
main:
parameters:
tree_depth: {type: int, default: 2}
command: "python main.py {tree_depth}"
同样,MLflow提供了一个CLI(command-lineinterface,命令行界面)来运行位于本地服务器或远程存储库上的项目。以下代码片段显示了如何从本地服务器或远程存储库运行项目的示例:
$ mlflow run model/example-decision-tree -P tree_depth=3
$ mlflow run git@github.com:FernandoLpz/MLflow-example.git -P tree_depth=3
在这两个示例中,环境是基于MLProject文件规范生成的。触发模型的命令将在命令行上传递的参数下执行。由于模型允许输入参数,因此这些参数可以通过`-P'标志指定。在这两个示例中,模型参数都是指决策树的最大深度。
默认情况下,如示例中所示的运行将把工件存储在一个名字为“.mlruns”的目录。
如何在MLflow服务器中存储工件?
实现MLflow时最常见的用例之一是使用MLflow服务器记录指标和工件。MLflow服务器负责管理MLflow客户端生成的工件和文件。这些工件可以存储在从文件目录到远程数据库等不同存储形式的方案中。例如,要在本地运行MLflow服务器,我们可以键入如下命令:
$ mlflow server
上述命令将通过IP地址http://127.0.0.1:5000/启动MLflow服务。为了存储工件和指标,在客户端会话中定义服务器的跟踪URI。
在下面的代码片段中,我们将看到MLflow服务器中工件存储的基本实现:
import MLflow
remote_server_uri = "http://127.0.0.1:5000"
MLflow.set_tracking_uri(remote_server_uri)
with MLflow.start_run():
MLflow.log_param("test-param", 1)
MLflow.log_metric("test-metric", 2)
其中,命令“MLflow.set_tracking_uri()”负责设置服务器的位置。
如何在MLflow服务器中执行身份验证?
在没有身份验证的情况下暴露服务器可能会有风险。因此,添加身份验证非常必要,当然也非常方便。身份验证将取决于您将在其中部署服务器的生态系统:
- 在本地服务器上,添加基于用户和密码的基本身份验证就足够了
- 在远程服务器上,必须与相应的代理一起调整凭据数据
为了说明这些,让我们看一个使用基本身份验证(用户名和密码)部署的MLflow服务器的示例。此外,我们还将看到如何通过配置客户端方式来使用此服务器。
示例:MLflow服务器身份验证
在本例中,我们通过Nginx反向代理将基本用户和密码身份验证应用于MLflow服务器。
让我们从Nginx的安装开始,我们可以通过以下方式完成:
# For darwin based OS
$ brew install nginx
# For debian based OS
$ apt-get install nginx
# For redhat based OS
$ yum install nginx
对于Windows操作系统,您必须使用本机Win32 API。您可以按照链接(https://nginx.org/en/docs/windows.html)处的详细说明进行这些操作,在此省略有关介绍。
安装结束后,我们将继续使用“htpasswd”命令生成具有相应密码的用户,如下所示:
sudo htpasswd -c /usr/local/etc/nginx/.htpasswdMLflow-user
上述命令为nginx服务的“.htpasswd”文件中指定的名字为“mlflow-user”的用户生成凭据。稍后,要在创建的用户凭据下定义代理,请使用配置文件“/usr/local/etc/nginx/nginx.conf”进行定义,默认情况下具有以下内容:
server {
listen 8080;
server_name localhost;
# charset koi8-r;
# access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}它必须看起来像这样:
server {
# listen 8080;
# server_name localhost;
# charset koi8-r;
# access_log logs/host.access.log main;
location / {
proxy_pass http://localhost:5000;
auth_basic "Restricted Content";
auth_basic_user_file /usr/local/etc/nginx/.htpasswd;
}
在这里,我们通过端口5000为本地主机定义身份验证代理。这是默认情况下部署MLflow服务器的IP地址和端口号。请注意,在使用云端类型的提供程序时,您必须配置实现所需的凭据和代理。接下来,开始初始化MLflow服务器,如以下代码段所示:
$ MLflow server --host localhost
尝试在浏览器中访问http://localhost时,需要通过创建的用户名和密码请求身份验证。
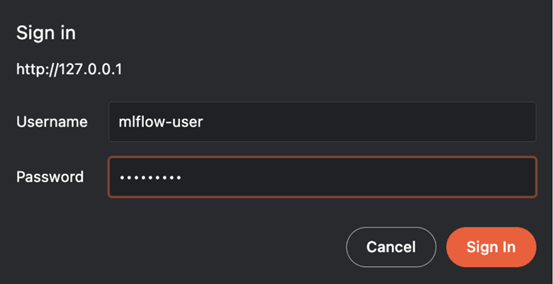
图1:登录界面
输入凭据后,您将被导航到MLflow服务器用户界面中,如图2所示。
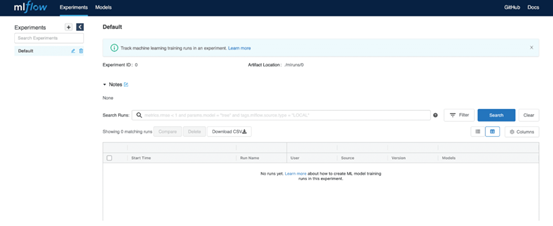
图2:MLflow服务器UI
要从客户端将数据存储在MLflow服务器中,您必须:
- 定义包含访问服务器的凭据的环境变量
- 设置存储工件的URI
对于凭证,我们将导出以下环境变量:
$ export MLflow_TRACKING_USERNAME=MLflow-user
$ export MLflow_TRACKING_PASSWORD=MLflow-password
一旦定义了环境变量,就只需要为工件存储定义服务器URI。
import MLflow
# Define MLflow Server URI
remote_server_uri = "http://localhost"
MLflow.set_tracking_uri(remote_server_uri)
with MLflow.start_run():
MLflow.log_param("test-param", 2332)
MLflow.log_metric("test-metric", 1144)
当执行上面的代码片段时,我们可以看到测试指标和参数反映在服务器上。
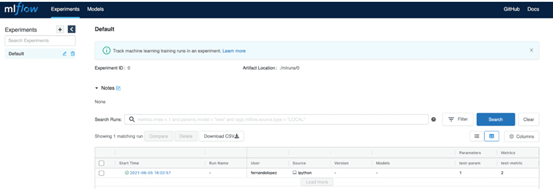
图3:从服务器上具有身份验证的客户端服务存储的指标和参数
如何注册MLflow模型?
开发机器学习模型时的一个日常需求是维护模型版本中的顺序。为此,MLflow提供了MLflow注册表。
MLflow注册表是一个扩展,有助于:
- 管理每个MLModel的版本,以及
- 记录每个模型在三个不同阶段的发展进程:归档(archive)、模拟环境(staging)和生产(production)。它非常类似于Git中的版本系统。
注册模型有四种选择:
- 通过UI
- 作为“MLflow.<flavor>.log_model()”的参数方式
- 使用“MLflow.register_model()”方法或
- 使用“create_registered_model()”客户端API。
在以下示例中,使用“MLflow.<flavor>.log_model()”方法注册模型:
with MLflow.start_run():
model = DecisionTreeModel(max_depth=max_depth)
model.load_data()
model.train()
model.evaluate()
MLflow.log_param("tree_depth", max_depth)
MLflow.log_metric("precision", model.precision)
MLflow.log_metric("recall", model.recall)
MLflow.log_metric("accuracy", model.accuracy)
# Register the model
MLflow.sklearn.log_model(model.tree, "MyModel-dt", registered_model_name="Decision Tree")
如果是新模型,MLFlow将其初始化为版本1。如果模型已进行版本控制,则将其初始化成版本2(或后续版本)。
默认情况下,注册模型时,分配的状态为“无”。要将状态分配给已注册模型,我们可以通过以下方式执行:
client = MLflowClient()
client.transition_model_version_stage(
name="Decision Tree",
version=2,
stage="Staging"
)
在上面的代码片段中,决策树模型的版本2被分配给模拟环境(staging)。在服务器UI中,我们可以看到如图4所示的状态:

图4:注册模型
为了实现模型服务,我们可以使用MLflowCLI。为此,我们只需要服务器URI、模型名称和模型状态这些信息即可,如下所示:
$ export MLflow_TRACKING_URI=http://localhost
$ mlflow models serve -m "models:/MyModel-dt/Production"
模型服务和POST请求
$ curl http://localhost/invocations -H 'Content-Type: application/json' -d '{"inputs": [[0.39797844703998664, 0.6739875109527594, 0.9455601866618499, 0.8668404460733665, 0.1589125298570211]}'
[1]%在上面的代码片段中,向模型提供服务的地址发出POST请求。在请求中传递了一个包含五个元素的数组,这是模型期望作为推理的输入数据。在这种情况下,预测结果是1。
需要指出的是,MLFlow允许定义数据结构,以便通过实现签名在“MLmodel”文件中进行推断。同样,通过请求传递的数据可以是不同类型的,可以在链接(https://www.mlflow.org/docs/latest/_modules/mlflow/models/signature.html)处查阅。
前面示例的完整实现可以在下面的链接处找到:
https://github.com/FernandoLpz/MLFlow-example
MLflow插件
由于MLflow的框架不可知性,导致了MLflow插件的出现。该插件的主要功能是以自适应方式将MLflow的功能扩展到不同的框架。
MLflow插件允许为特定平台定制和调整工件的部署和存储。
例如,下面这些是用于平台特定部署的插件:
- MLflow-redisai:它允许从MLflow中创建和管理的模型创建部署到RedisAI(https://oss.redislabs.com/redisai/)
- MLflow-torchserve:使PyTorch模型能够直接部署到torchserve(https://github.com/pytorch/serve)
- MLflow-algorithmia:允许将使用MLflow创建和管理的模型部署到Algorithmia(https://algorithmia.com/)基础设施
- MLflow-ray-serve:支持将MLflow模型部署到Ray(https://docs.ray.io/en/master/serve/)基础设施上
另一方面,为了管理MLflow项目,我们还提供了MLflow-yarn,这是一个在Hadoop/Yarn支持下管理MLProject的插件。对于MLflow跟踪的定制,我们有MLflow-elasticsearchstore,它允许在Elasticsearch环境下管理MLflow追踪扩展。
同样,也提供了特定的插件以支持部署到AWS和Azure等平台,它们是:
- MLflow.sagemaker和
- MLflow.azureml
必须提到的是,MLflow提供了根据需要创建和定制插件的能力。
MLflow与Kubeflow的比较
由于对开发和维护机器学习模型生命周期的工具的需求不断增加,出现了不同的管理方案,例如MLflow和KubeFlow等。
正如我们在本文中已经看到的,MLflow是一种工具,它允许在开发机器学习模型的生命周期中进行协作,主要关注跟踪工件(MLflow跟踪)、协作、维护和项目版本控制。
另一方面,还有一个类似的工具是Kubeflow,它与MLflow一样,是一种开发具有特定差异的机器学习模型的工具。
Kubeflow是一个在Kubernetes集群上工作的平台;也就是说,Kubeflow利用了Kubernetes的集装箱化特性。此外,Kubeflow还提供了Kubeflow管道线等工具,旨在通过SDK扩展生成和自动化管道(DAGs)。
此外,Kubeflow还提供??Katib??,这是一种大规模优化超参数的工具,并提供Jupyter笔记本的管理和协作服务。
具体而言,MLflow是一个专注于机器学习项目开发的管理和协作工具。另一方面,Kubeflow是一个专注于通过Kubernetes集群和使用容器开发、训练和部署模型的平台。
这两个平台都具有各自显著的优势,都是开发、维护和部署机器学习模型的可选择方案。然而,在开发团队中使用、实现和集成这些技术时,必须考虑相应的技术壁垒。
由于Kubeflow需要连接到Kubernetes集群才能达到实现和集成目的,因此建议由一名专家来管理该技术。同样,开发和配置管道自动化也是一项挑战,需要学习曲线,在特定情况下可能对公司不利。
总之,MLflow和Kubeflow都是专注于机器学习模型生命周期特定阶段的平台。MLflow是一种面向协作的工具,而Kubeflow更倾向于利用Kubernetes集群来生成机器学习任务。然而,Kubeflow需要MLOps部分的经验。您需要了解Kubernetes中的服务部署,这可能是尝试接近Kubeflow时需要考虑的问题。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
原文标题:??How toPackage and Distribute Machine Learning Models with MLFlow???,作者:Fernando López?
