Geyecloud's Technology Director Explains How Artificial Intelligence Assists in Detection of 原创
Advanced persistent threats (APT) are hard to be detected because of their variability and strong invisibility. To combat them, enterprises have been seeking methods such as adopting artificial intelligence to solve this problem more efficiently and accurately.
In this article, we invited Mr. Fu Jixiang, Technology Director of Geyecloud.com, to share his insights on how artificial intelligence can help to tackle security issues that used to be challenging to resolve with traditional feature detection methods.
Challenges of APT detection
Generally, advanced persistent threats refer to cyberattacks carried out by an organized team that uses the information they have to build corresponding weapons and attack means, which are utilized in long-term continuous cyberattacks.
Several stages could be involved in the attack chain, including:
scanning detection,
attempted attacks,
exploiting vulnerabilities,
Trojans in downloads,
gaining remote control,
horizontal penetration,
harvesting operations,
…
Complex and highly sophisticated in terms of methods and payloads, these attacks are those viewed as advanced persistent threats by professionals in the security field.
As part of the defending process, it is necessary to determine the attack mechanisms to respond to and dispose of them. Unfortunately, traditional feature detection techniques are not well-suited to dealing with these higher-level threats.
Usually, when a new threat arises, defenders have to obtain a sample of it first. Then they need to update the network security equipment to detect or defend against it based on the analysis of the sample.
The problem, however, is that there is a defense vacuum for unknown threats before upgrading security protections or detection appliances. Today we could see variants of malicious code, such as malevolent samples and Trojan horses, and attackers will allow the sample to bypass defenses and detections. In this manner, an attacker can hide or obfuscate features that the antivirus software may have detected. Thus, the antivirus, the file hash code, or the signature code will no longer be able to see these threats effectively.
Through the entire process of the attack chain, some behaviors can be easily found by specific means such as detection engines. Despite this, there will also be hidden parts of the process that will be difficult to discover, which are equally important to assess the attacking circle. Currently, many cyberattacks use encryption techniques, and in the entire network traffic, we can only see handshakes and certificate information. With only this information, it will be impossible to determine whether there is a problem with the encrypted traffic load or whether a Trojan or malicious attack is taking place.
Upon completion of the intrusion, the computer will connect to its command and control (C&C) server to maintain communication and receive the attacker's following instructions. Today, firewalls are common network security appliances that do not intercept or deeply examine popular protocols such as DNS, HTTP, and ICMP. Therefore, using standard network protocols for C&C communication in the above back-connection process is advisable if you desire covert communication.
Cryptographic agents that are malicious will encrypt the entire session. Browsers that offer dark web access, such as Onion, can mask content and access behaviors. It is also possible to hide the communication behavior using an open VPN service. These clues may provide the key to identifying the entire attack chain.
AI application in APT detection
Protocols control how behaviors interact in a network. Multiple interactions occur between the client and server in the network whenever a client visits a website or sends an email. In this process, the information returned from the website end is usually greater than the request information sent. The process can be visualized, and the network behavior can be modeled.
Data leaking by Trojans also involves multiple rounds of data interaction. This creates a dominant pattern based on the distribution of session data in time and packet size. It is necessary to construct a pattern for all traffic to identify it, and a model of AI can be employed to learn this pattern.
This scenario would benefit from the use of artificial intelligence. For example, Apple's virtual assistant Siri captures speeches, converts them into digital signals, and then extracts linear parameters to construct feature vectors by combining multidimensional data. Later, it is given to an artificial intelligence algorithm for modeling. As soon as the model is constructed, the speech can be effectively recognized.
Likewise, network traffic patterns can be identified using a similar process. Samples of uplink and downlink bidirectional network session packets are collected first, and the packet content will be digitized. After that, the message content will be parsed by different ways, such as protocol parsing at the network, transport, and application layers. The packets can also be counted in this process, and then the data can be learned through pre-modulated algorithms and applied to network security appliances.
A key component of the above process is identifying the data source. There are many Trojan horses on the Internet that send encrypted traffic. As a result, Trojan samples can be captured and placed within a sandboxed cluster environment to generate Internet traffic and capture encrypted PCAP traffic. In addition, many websites or academic institutions will disclose some encrypted PCAP traffic and malicious encrypted traffic, which are valuable data sources.
It should be noted that not all original traffic or files can be applied directly. Once the data capture has been completed, it must be analyzed to determine the data quality and filtered accordingly. A standard or security appliance engine is used to parse the traffic and extract statistics and feature data. AI engineers analyze the acquired data by applying various models or algorithms to classify it into several categories.
Classification begins by determining whether there are other protocol traffic flows. There are many Trojans that simulate normal web browsing behaviors to avoid detection. In this case, we could capture the DNS context associated with the session and then analyze and extract the data.
Furthermore, to gather different kinds of interaction data, the session must first be authenticated with TLS.
The practice can be analyzed based on the two dimensions mentioned above: whether DNS is associated and its authentication is complete. By dividing the data into four groups and using these data to train models, different models can effectively identify the data in the corresponding categories.
Once the data has been classified, the features will need to be extracted to construct feature vectors.
First, it can distinguish what data it will extract based on whether DNS-associated data is present. If no DNS-associated data exists, its statistics and TLS protocol data are extracted.
Second, take note of the encryption certificate data. These data are converged together to generate feature vectors. As for the DNS association data, we should consider extracting DNS-related fields such as domain length, domain suffix, and TTL to form feature vectors.
Lastly, before training and modeling, it is necessary to conduct visualized dimensionality reduction analysis to determine whether AI algorithms can classify data effectively. In terms of the dimensionality reduction graph, this is more like identifying a curve or surface that will enable us to evaluate whether the AI algorithms are capable of accurately categorizing the data. Many algorithms are available for dimensionality reduction, e.g., the PCA algorithm, and different algorithms will be appropriate for various practical purposes.
Modeling is the next step in the process. Deep learning has recently gained popularity as an alternative to traditional machine learning. A better identification effect and accuracy of malicious encrypted traffic can be achieved through ensemble learning algorithms, which use multiple machine learning algorithms within one model or in conjunction with one machine learning algorithm to build multiple submodels.
Some rapidly-changed variants of malicious files are also advanced threats. The traditional feature codes have difficulty keeping up with the production of new variants of the samples. By transforming the file into an image, the file can be indirectly identified by a convolutional neural network capable of recognizing the image. Convolutional neural networks for image recognition are not as computationally intensive as traditional feature detection algorithms.
Specifically, the malicious code needs to be mapped as a grayscale image and extracted features. Then, the features are used for clustering, and clustering results are used to identify malicious code families. The next step is to build a CNN model and set up the network structure and training parameters. A convolutional neural network is then trained with grayscale image sets from the malicious code family to build the detection model. Finally, the detection model can detect malicious code families and variants.
Currently, many malicious programs communicate with external entities of the enterprises through covert channels. DNS covert channels allow leaky data to be encoded in BASE64 as a subdomain and transmitted through the firewall using the DNS protocol to the controlled server. Requests and responses can also be sent using a DNS 'text' (TXT) record. Similarly, hackers register the domain's resolution server to retrieve the desired data.
The ICMP channel is one of the most commonly used methods. Generally, it uses the ICMP packets of Echo and Reply to locate the fields within them and then populate them with data. Similarly, it may be transformed into another form by encoding or encryption before being sent out repeatedly in multiple frequencies to a controlled server.
Another common covert channel is HTTP, which is an application layer protocol. After it establishes a channel, we can use it to transmit some data on the transport layer or TCP/IP layer, i.e., data is carried through the upper application layer. When this occurs, a firewall is unable to intercept the information effectively.
We must obtain the corresponding tool traffic or real channel traffic to solve the problem. Following this, the DNS and other protocol traffic feature vectors are extracted. This includes both the content of the protocol itself as well as the statistical feature values, which form the feature vector. Finally, it is used as the basis for training a machine learning or ensemble learning model. With the trained model, the previously mentioned tools can identify traffic patterns.
Several methods can be used to improve the accuracy of the models discussed above. In utilizing AI, we can establish models based on different classes of data related to a specific issue using various algorithms. It is then possible to integrate these models and make them worthwhile. In addition, the same algorithm may be trained with different data to set up models that can be used in parallel. Blacklists and whitelists can also be considered alternatives to the AI approach for improving the model's accuracy.
Modeling involves a large number of processes and tools, and the entire process can be incorporated through modeling platforms and tool scripts. Many algorithms and libraries are currently available for application, such as TensorFlow and MLlib. Furthermore, the model can be continuously improved through multiple rounds of iteration to make it more adaptable to new sample categories or to reduce its false alarm rates.
Case studies and practical results
The trained model can be put into the appliance if the data input source is traffic. The original network traffic can be provided so that the appliance can use the built-in parsing engine to perform protocol parsing and feature vector extraction on the traffic, which can then be passed to the AI model for detection.
For the training of neural network-like deep learning algorithms requiring high computing power, you can use multiple devices or GPUs. While machine learning algorithms do not ask for high computing power. Alternatively, a distributed architecture can be used to apply the model, with the front-end appliance analyzing traffic protocols and generating metadata; the back-end appliance extracts feature vectors and pass them to the model.
Besides AI models, other detection methods can also be used in threat detection. For example, antivirus engines, Yara, features, threat intelligence, etc., can be combined with other applications to create a comprehensive solution. Furthermore, malicious encrypted traffic gives rise to another difficulty in the production environment; that is, if a problem is discovered, it is hard to determine whether it exists, which may be verified through other indirect means.
Consider the following scenario. An internal host accessed an external server and triggered an alarm on malicious encrypted traffic. Thus, we could assess the original host and attempt to make sure whether it has recently been attacked, whether there are harmful samples or Trojans, and whether it has been compromised successfully. On the remote end, we can identify whether there is a problem with the remote server by using IP or domain name intelligence. There is a greater chance of the event being malicious if both ends of the chain are risky.
A web-based attack can be evaluated by extracting its payload. For example, if it had experienced SQL injection, the injected content can be extracted in the traffic, allowing the injected statements to be seen after decoding. Webshell can also identify whether the content inside is abnormal access, much like XSS and other threats.
A complete attack process could be like the below image: a ransomware program is delivered to an asset of internal concern. The asset parses DNS and obtains an IP address, and then covert HTTP channels occur. All events are recorded in raw format. Additionally, the system automatically combines different events to form a more advanced alert. The entire process can also be visually and dynamically displayed, making it easy to understand and retrace which assets, external IP addresses, or devices have been connected to our network.
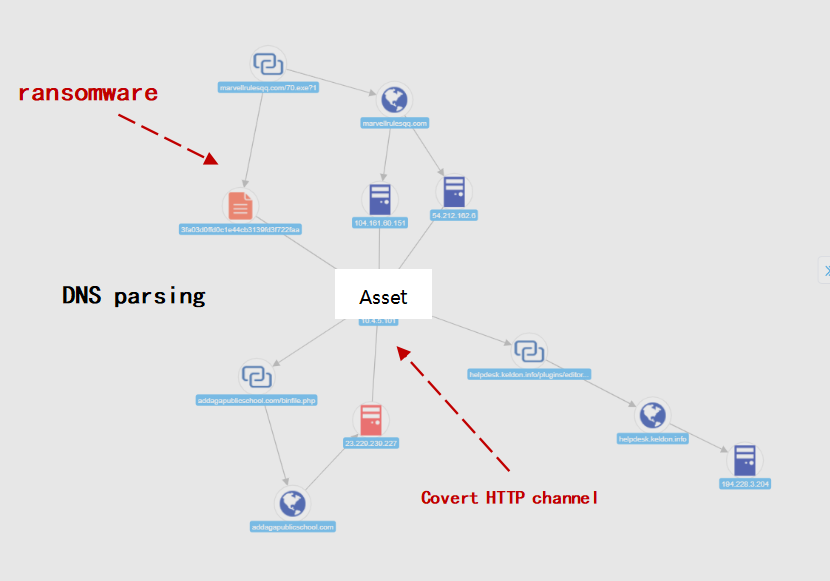
Upon threat detection with AI algorithms, it is possible to associate threats with different dimensions, such as the asset we are concerned about, the network behavior of the asset, and external threat intelligence. Then, a dynamic knowledge graph can be created. By relating form data intelligently, we will be able to improve the analysis efficiency, traceability, and ultimately, our daily operations.
Guest Introduction
Mr. Fu Jixiang is a graduate of Northeastern University with a degree in Information Security. Prior to joining Geyecloud.com as the technology director and pre-sales leader, he worked for KDDI China, Huawei, and WebRAY. As a network security expert with over ten years of experience, he specializes in applying artificial intelligence, big data, and network traffic analysis to detect advanced persistent threats.
Previously Mr. Fu was invited as a guest speaker at the Information Security Conference and the XFocus Information Security Conference (Xcon). Besides being interviewed, he also gave an impressive speech at the release conference of the 'Enterprise Advanced Threat Protection Guide' by one of China's leading cybersecurity media outlets aqniu.com.
