Arm架构是如何一步步成为全球计算的基石?
以前,提起Arm,人们更多想到的是手机和嵌入式,然而自从2018年开始,Arm宣布推出Neoverse并进军高性能计算市场,至今已过去了四年,如今Arm架构的基础设施已经成为了一个明显趋势,正如Arm 首席执行官 Rene Haas所说:“目前世界上所有主要的公有云服务提供商现在都在使用 Arm 架构。”
盘点2022年Arm Neoverse的里程碑
Arm高级副总裁兼基础设施事业部总经理 Chris Bergey 盘点了2022年Arm Neoverse的重要事件,其中包括:
在全球范围内,Arm 现已被用于各个主要公有云,包括 AWS、微软、谷歌、阿里巴巴、甲骨文等科技巨头。值得一提的是AWS,在一个月前,亚马逊副总裁James Hamilton 讲述了他们如何开始定制芯片之旅,2013 年,James 向Jeff Bezos 提出了一项双论点。其一,鉴于使用 Arm 架构的芯片出货数量,他确信 Arm 最终一定能设计出优异的服务器 CPU;其二,James 注意到,随着时间的推移,越来越多的功能逐渐从主板迁移到 SoC 上。手机领域已现端倪,他认为服务器方面自然也会效仿。AWS 多年来一直在打造定制服务器,并通过定制,为客户创造了更多价值。但如果服务器中的所有创新都转移至芯片上,而 AWS 不打造芯片的话,他们的创新将有所局限。从 James 的论点得出的结论是,AWS 需要开始打造 CPU。这也促使他们收购 Annapurna Labs,该公司基于 Arm Neoverse 创建了 AWS Graviton 系列 CPU。
在5G RAN领域,Neoverse无处不在。在世界移动通信大会 (MWC) 上,戴尔宣布将采用Marvell 的 OCTEON Fusion 平台开发O-RAN加速卡。高通也与乐天、HPE 达成了合作,同样基于Arm Neoverse平台。
而在HPC市场,NVIDIA 发布了面向 AI 及高性能计算 (HPC) 的 Grace超级芯片,基于最新的 Armv9 架构,单个 socket 拥有 144 个 CPU 核心,具备最高的单线程核心性能,支持 Arm 新一代矢量扩展。可实现当今领先服务器芯片内存带宽和能效的 2 倍。
除此之外,在软件和系统层面,Arm的Neoverse也正在得到越来越多的认可。比如,VMware 运用 DPU 开展 Monterrey 项目,RedHat 的 OpenShift 支持 Arm 架构,SAP HANA 正将其云基础设施迁移到 AWS Graviton 上,HPE的ProLiant 第 11 代平台,搭载了基于 Arm Neoverse 的 Ampere Altra 处理器,等等。
Neoverse已经在处理器上取得的一系列成就,包括:
第一个总内存带宽超过每秒 1TB 的 CPU
第一个单块裸片上能配置超过 100 个核心的 CPU,核心数达到 128 个
第一个将 DDR5 和 PCIe Gen5.0 推向市场的 CPU
第一个在 SPEC CPU 2017 基准测试中打破 500 整型跑分的 CPU
Arm公布最新Neoverse路线图
“Arm 架构是全球计算未来的基石。”Bergey如是说。“如今的基础设施是定制化打造,从 SSD 到 HDD,从 DPU 到视频加速器,服务器 CPU 算是最后的标准产品,将不会作为通用型产品继续发展。与此同时,计算工作负载正极力增长,而且愈加复杂。ML 和 AI 正在发挥取代作用。另外一个问题则是功耗问题,目前大型互联网公司的电力支出占到总拥有成本 (TCO) 的 30-40%,仅微次于电信网络运营商。”
也正因此,Arm公布了最新的Neoverse路线图,以满足基础设施的升级要求。
Neoverse共分为V、N 和 E 系列内核,针对了三种不同类型的性能。其中V 核追求最大化的性能表现,E核关注性能效率,而N 核则更关注吞吐效率。
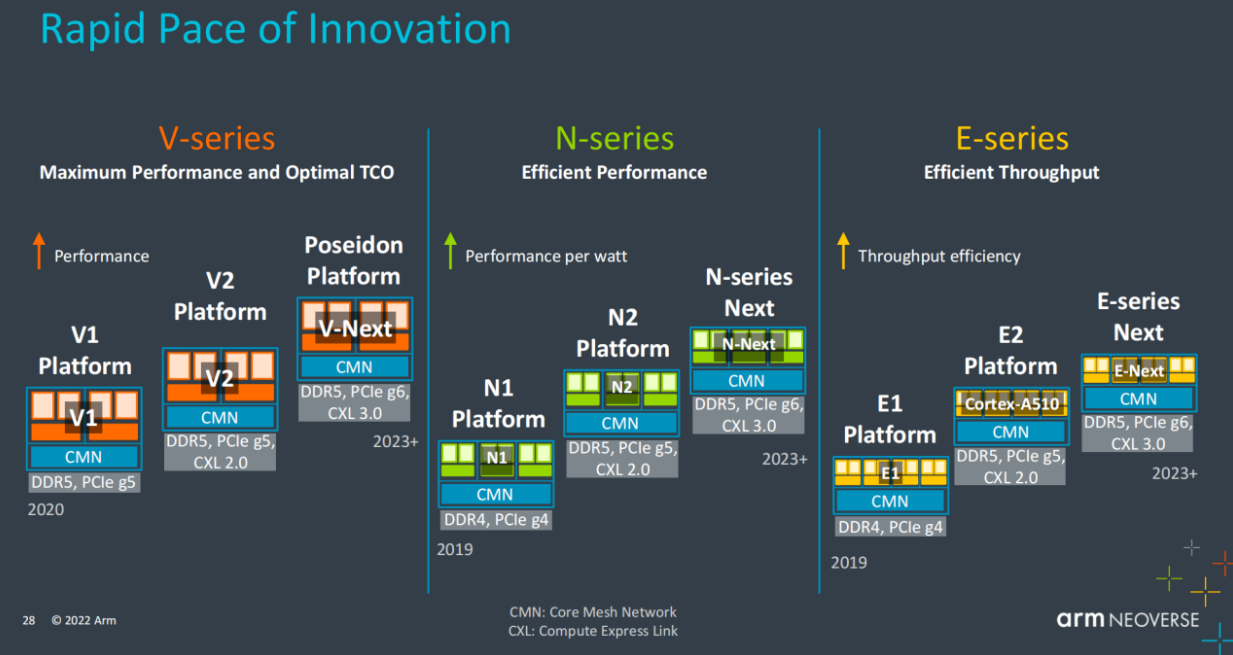
如图所示,无论是V、N还是E系列,Neoverse都有详细的路线图升级规划公布。
Arm 基础设施事业部产品解决方案副总裁 Dermot O’Driscoll表示,单芯片性能和单线程性能是云决策者的两大关键指标。其中单线程性能是决策者是否可将对 “扩展” 要求最高且性能需求大的工作负载迁移到 Arm的指标。而单芯片性能则是其是否可以通过大量运行在平台上的 “横向扩展” 工作负载,来实现投资价值的最大化的关键所在。“使用 Arm Neoverse V1 核心的 AWS Graviton3 可提供最高的单线程性能,即便是即将上市的竞品 CPU 也无法动摇它的领先地位。我们预期 Graviton3 能提供出色的性价比和每瓦性能,而Ampere Altra Max 和阿里的倚天 710 能在所有 CPU 中提供最佳的单芯片吞吐量。”
而除了硬件,Driscoll还提到Arm一直在努力实现并优化全栈解决方案,从架构和 IP到技术库、运行环境和编译器,在全部基础设施软件范围内实现最佳性能。
而实际测试结果也表明,Arm在基础设施处理上已经实现甚至超越了传统架构。Driscoll以主流数据存储 MongoDB应用程序为例,通过从 AWS 处对比基于 Graviton2 和 Intel Xeon 的实例,测得 MongoDB 性能优于x86架构117% 之多。
Driscoll还表示,随着机器学习的流行,Neoverse V1 也拥有一组专门用于增强 ML 应用程序性能的功能。其中包括:
在架构方面,添加了 Bfloat16 (BF16)
调整了 V1 、N2 以及后续设计的微架构,旨在通过 BERT 提高 BF16 的执行
为 Arm 计算库 (ACL) 增加 BF16 支持
将 ACL 集成到 oneDNN ML 框架中?
oneDNN 框架与 Tensorflow 搭配使用以运行 BERT
同样的,Arm也在基于 V1 核心的 AWS EC2 C7g 上运行 BERT,并将其与使用最新 Xeon 核心的 C6i 进行对比,在 Arm 架构上经 BF16 优化的堆栈性能比英特尔高出 80%。同时,在 V1 添加的 BF16 和 Int8 MatMul意味着 ML 模型可以更紧凑地植入内存,因此它们需要更少的内存带宽,从而使 Graviton3 的 ML 性能达到 Graviton2 的 3 倍。
Driscoll在谈到Neoverse V2平台时,表示该平台可以同时满足客户“希望提升云工作负载的性能”、“在平衡功耗和面积的同时,继续推进单线程性能”以及“尽早发货,帮助快速开拓市场”这三点需求。
在机器学习性能方面,Neoverse V2 将提供市场领先的整型性能,目前Arm是用 SPEC Integer Rate 对预估值进行测量,并且一直利用模型中的各种云基础设施工作负载对微架构进行调整,整个系列的成果令Driscoll“十分兴奋”。对于像 HPC 之类正快速迁移到云端的工作负载而言,矢量性能依然很重要,在 Neoverse V2 上,Arm完成了从 SVE 到 SVE2 的过渡,SVE2 可以帮助满足更多非 HPC ML 类型的工作负载,同时添加了更多加密指令。另外矢量引擎重构为 4 通道的 128 位,并对微架构进行了调整,以提高其有效吞吐量。
?
此外,在系统层、IO层以及安全层等方面,Neoverse V2均有了一系列提升,这点从NVIDIA的Grace超级芯片的性能表现上就可看出。
Driscoll并没有更多透露N和E系列的进展,只表示,N 系列产品线将在明年迎来一次更新。市场采用方面,目前已经也有近 20 家客户正基于 N2 平台进行设计。
Driscoll表示:“基础设施市场正在被重新定义,以 Arm 的高性能、可扩展效率计算为中心,并通过我们合作伙伴的专用处理得以增强。在 Arm Neoverse 平台路线图的原则基础上,我们将为全球计算基础设施奠定新的起点。”这也是对Arm Neoverse诞生这四年的一次总结与展望。
