细看三星4nm:今年为数不多的真·4nm
在TechInsights前不久把台积电N4、三星L4X称作假4nm以后,今年一大批已经上市的4nm芯片也就成了假4nm芯片——当然苹果A16所用的N4P工艺,以及英伟达Hopper/Ada Lovelace的4N工艺有概率成为真·4nm。
当前真正能够板上钉钉,被TechInsights认为是真·4nm的也就只有三星4LPE了,也就是三星自家Exynos 2200芯片用的工艺,虽然其实际表现好像不怎么样,而且作为一个完整工艺节点,其改进幅度并不大。
其实到目前为止,我们都不怎么清楚4LPE的实际性能水平。一方面是高通用的三星4nm并非4LPE,而是据说差别甚大的4LPX;另一方面Exynos 2200的性能水平虽然拉跨,但同节点没有直接的对比对象,更何况三星LSI的芯片设计水平在座各位也是知道的(删去)…

无论如何,技术和工程层面所作的努力,在半导体尖端制造工艺上都是不易的。去年的IEEE国际电子器件大会(IEEE International Electron Devices Meeting)上,三星曾大致介绍过这代工艺。
虽说4LPE工艺已经是三星foundry的最后一代FinFET器件工艺了,但这仍然有利于我们了解三星foundry目前的技术发展水平,乃至当前半导体制造最尖端技术都有哪些特点。
器件微缩与密度变化
我们之前撰文谈4nm时提到过,三星4nm工艺属于7nm工艺之后的一次完整迭代,或者说这是个full node(不过它在基本规则上仍然较多地继承了7LPP)——虽然不知就实际应用来看,其寿命会多久:毕竟后续的3nm才是三星要推的重点。这就意味着4LPE和台积电N4的定位是不一样的,后者是其前代工艺的改良版。

就器件层面,从Wikichip的总结来看,三星4LPE工艺的fin(鳍)、S/D(源极/漏极)都已经来到了第7代(7nm和5nm分别是第5代和第6代);应用更多EUV光刻也是已知信息了。
似乎从HP高性能和HD高密度单元来看,两种CPP(Contact Poly Pitch)间距相比于5LPE都是没有变化的。三星在此前谈到4LPE是有器件层面的pitch scaling的——或者说晶体管间距变小,但没有说具体怎么个缩法;2019年的时候,Wikichip曾说4LPE工艺的fin pitch有变化(27→25nm),金属互联尤其是M1层有显著变动(40→28nm)。
在晶体管密度方面,Wikichip早前就估算4LPE密度大约有8%的提升。这就让三星4LPE在晶体管密度上和台积电N5达到了相似的水平,都在140 MTr/mm?(百万晶体管每平方毫米)左右——这是HD高密度单元库的密度情况。
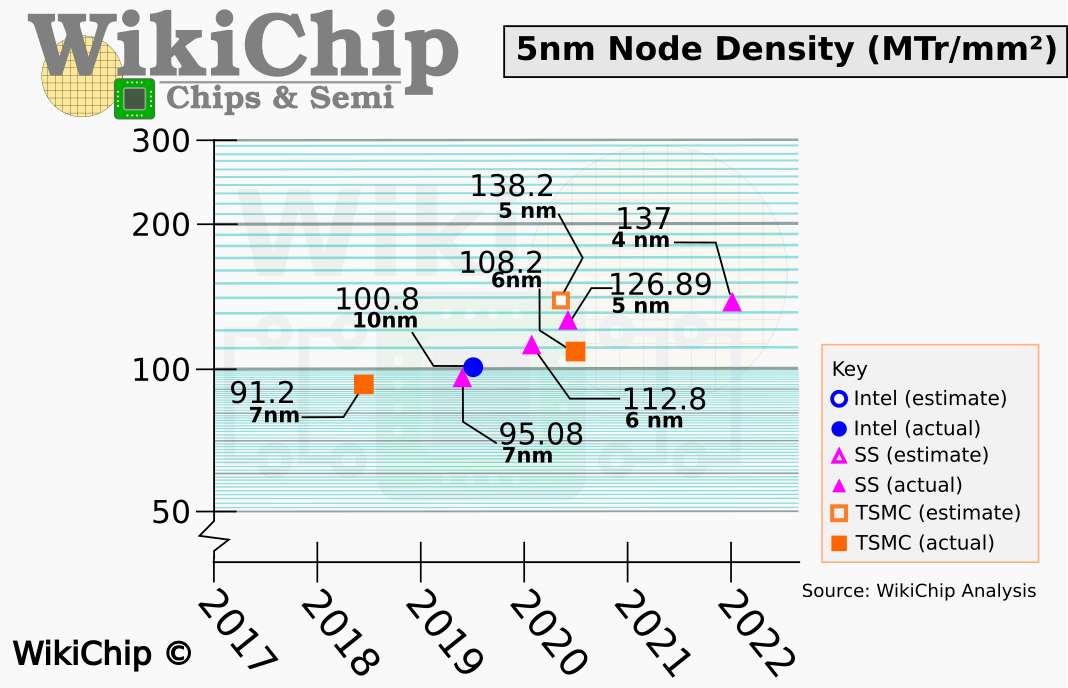
来源:WikiChip
HP高性能单元部分,4LPE的晶体管密度约为97.1 MTr/mm?。这个值和台积电N5的高性能单元库也相对接近,但略密一些。目前尚不清楚台积电“真·4nm”(因为N4已经被TechInsights认为和5nm区别不大了)可达成的实际密度提升,N4或N4P理论上也会有器件密度的小幅提升(台积电公开的值是6%)。单纯从器件密度来看,N4和4LPE应该也差不了多少。
不过不要忘了尖端制造工艺的另一名选手Intel。从Intel此前公开的信息来看,Intel 4工艺的HP高性能单元晶体管密度可能达到了大约120 MTr/mm?。这就让台积电和三星的4nm都不怎么够看了。但一方面是Intel 4至少也要等到明年才来,另一方面是Intel 4工艺是没有HD库的。
器件密度问题上另外值得一提的是,4LPE在SRAM部分提供了一种UHD(超高密度)SRAM单元,不过利用的主要是COAG特性,也就是单元scaling booster方面的优化。只不过三星也没有公开UHD SRAM单元的尺寸信息,也无从谈起和台积电工艺的比较了。
单元层面的密度优化
一般器件层面的各种间距若无太大变化,则密度提升或者说die size缩减要靠的就是所谓的scaling booster优化方案了。前文已经提到,4LPE至少提供了HP高性能和HD高密度单元,这两个单元选择都包含了两种gate pitch,分别是54nm和60nm,相比于5LPE是一样的。HD单元高度200nm,HP单元高度254nm。据说这让4LPE的单元成为目前已知单元高度的工艺节点里最短的单元。
三星表示,4LPE相比于5LPE有额外的一些BEOL(back-end-of-line)和MOEL(middle-end-of-line)优化,令HD和HP单元的性能分别提升了3%和5%。
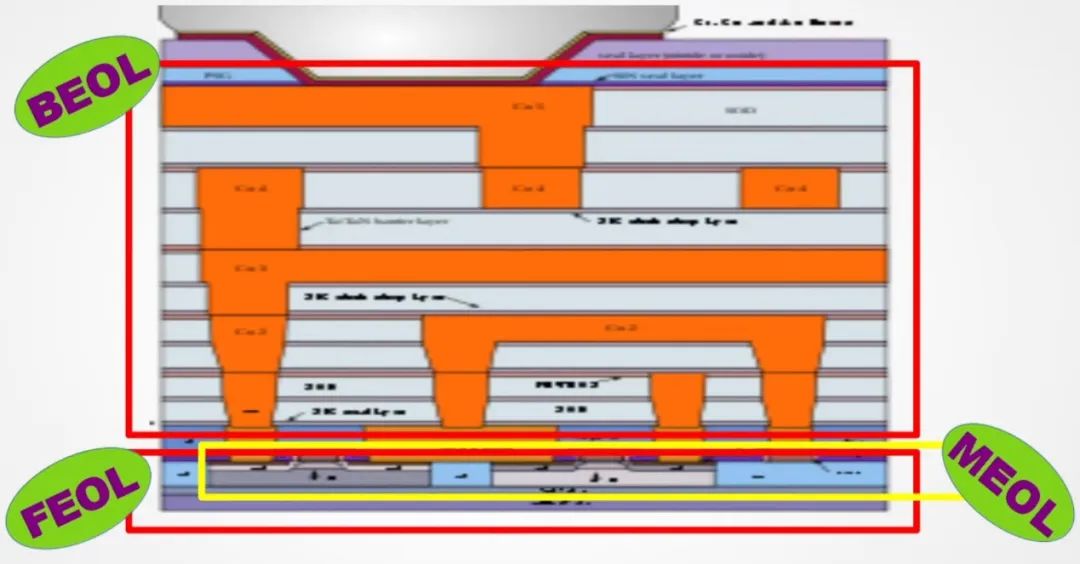
在此多做一点解释,此前有同学问FEOL、MEOL、BEOL是什么意思。CMOS制造大方向可以切分成3块,就是FEOL、MEOL和BEOL。FEOL也就是前端制造过程,一般是wafer之上的晶体管/器件级别的layout;而MEOL则可理解为晶体管级别的互连——不过MEOL仅限在晶体管层级的互连上,是低层级的互连;BEOL后端流程进行的是P&R(placement and routing)阶段的互连。当然其中还涉及到很多细节。
藉由各方面的优化,典型Vdd之下,4LPE相比于5LPE性能综合提升大约7%,而功耗降低12%;低Vdd之下,这两个数字则分别是10%和12%。
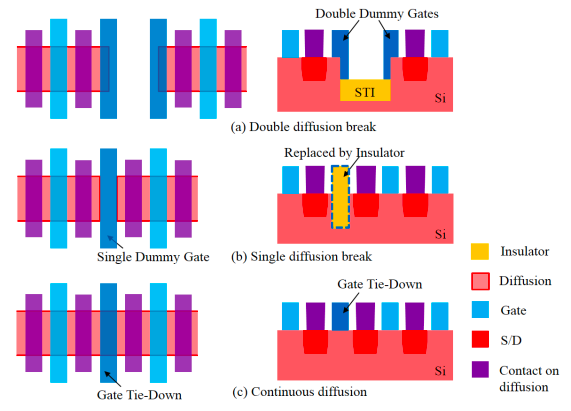
来源:S. Badel et al., "Chip Variability Mitigation through Continuous Diffusion Enabled by EUV and Self-Aligned Gate Contact," 2018 14th IEEE International Conference on Solid-State and Integrated Circuit Technology (ICSICT), 2018, Fig.2,9, doi: 10.1109/ICSICT.2018.8565694.
具体谈谈scaling booster方面的特性。三星早在14nm工艺之上就引入了SDB(single diffusion break;也叫做single dummy gate;如上图(b)),此前的科普文章里解释过什么是SDB,不了解的可移步阅读。这是一种典型的可缩减单元尺寸的方案,简单来说是缩减原本用于隔离相邻单元的位置的长度,达到让单元更紧密的目的。4LPE也不例外,三星用类似的技术已经很多年了。
不过值得一提的是,在7nm工艺前后,三星引入了一种MDB(mixed diffusion break)。对应的技术似乎是三星的独家方案,据说能够更为精确地进行diffusion break相关时序与漏电分析,混合使用SDB和DDB(double diffusion break,上图(a))达成更好地性能与功耗平衡。8nm、7nm和5nm都选择了MDB方案。
其实单纯使用SDB需要考虑很多复杂的问题,像这样的方案在某些情况下会面临电特性、性能方面的不良效应。未知是三星已经最小化影响,还是为了追求更高的密度。但三星也给出了在SDB方案下,和dummy gate(insulator)不同距离之下的gate的漏电情况,似乎差别还是非常小的。
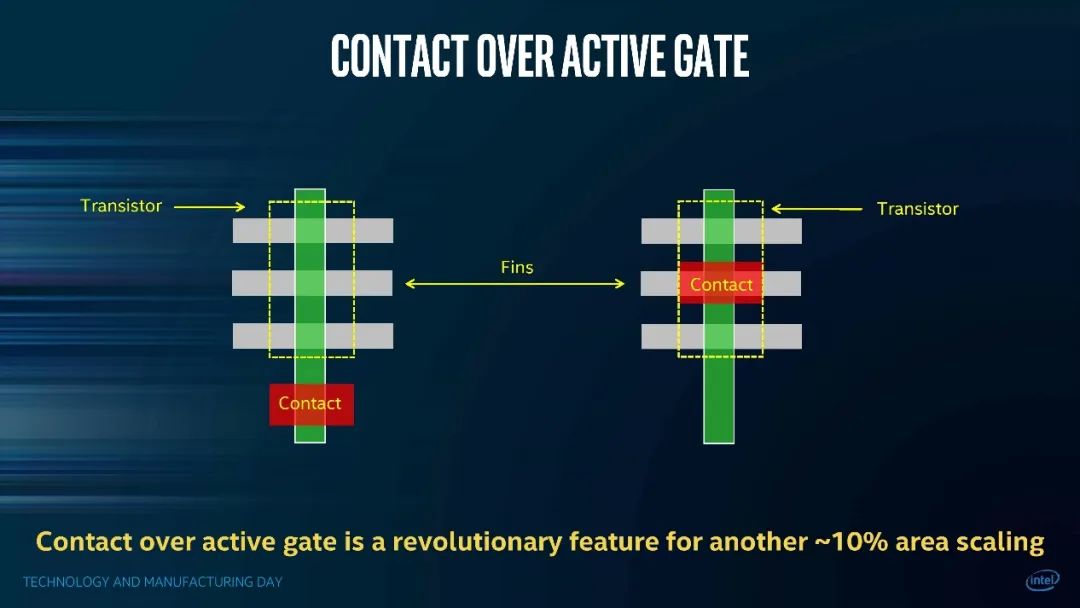
另外一个比较重要的方案是COAG(contact over active gate)。以前的gate contact(栅极接点)是放在nMOS与pMOS器件之间的所谓ETE部分的——接点位置要伸到单元外面去,这就要占据额外的die面积了。三星是从7nm开始,把这个触点位置逐渐移到边缘位置。
而在4nm上,三星终于是把gate contact搬到了active area位置(Rx),进一步缩减了单元高度。似乎此前我们在介绍Intel 10nm工艺的时候就提到,Intel早就这么干了。但可能当时的工艺水平还没有像现在这么高,台积电也是在5nm工艺上达成的COAG。COAG的实现据说是挺不容易的。
实则像SDB、COAG这种看起来只是位置问题,牵扯的因素很多。且不说达成位置摆放精度之类的工程问题,要在不同位置下确保某些关键电特性的一致性,还是相当考验foundry厂的技术能力的。比如SDB的应力控制;而像COAG这类方案下,三星还特别公布了把contact接点放在不同位置上,阈值电压的变化情况。至少就三星公布的数据来看,从现在的gate contact接点,到此前放置的边缘,不同位置的电压漂移不到10mV。
到这种微观世界的小调整,尖端制造工艺上任意物理位置layout变化、材料、化学等相关的微调都会带来很多副作用,对于最终的性能造成影响。所以像pitch scaling之外的这些scaling booster方案要实施起来也很费时费力。
不过从这两年foundry厂的推进工作来看,尤其是三星自7nm之后开展的工作,都充分说明了foundry厂当下寻求密度突破、die size缩减正越来越多地把工作放到单元层面,或者说减少die上很多看起来像是浪费的面积;毕竟晶体管/器件层面的各种pitch scaling真的没那么容易。
更多信息可以来这里获取==>>电子技术应用-AET<<

