芯片开发成本大涨10倍,汽车厂商自研芯片,不划算!
因为厌倦了为半导体付出高昂的代价,因此通用汽车公司的自动驾驶汽车部门决定开始自己设计芯片。这是一个大胆的举动,但可能会让汽车公司迷失方向。
就在 18 个月前,半导体巨头 Nvidia展示了Cruise Origin Robotaxi,作为在 Cruise 汽车中使用图形处理单元的案例研究,“以实时处理其车队在旧金山混乱的街道上收集的大量数据。”
这家总部位于加利福尼亚的自动驾驶汽车公司的硬件负责人Carl Jenkins最近告诉路透社,现在这种关系看起来已经破裂,因为使用“来自著名供应商的 GPU”的成本高且回旋余地小。Nvidia 没有直接点名,但它是仅有的两家 GPU 供应商之一,另一家 Advanced Micro Devices Inc. 不是汽车行业的参与者。
Cruise 并不是第一家使用英伟达芯片,然后放弃的汽车公司。三年前,特斯拉公司宣布将独自开发用于其全自动驾驶 (FSD) 计算机的芯片。当时,英伟达随后发布了一篇详细的博客文章,解释了为什么特斯拉CEO Elon Musk 在评估性能差异时是错误的。
实际上,Cruise、Tesla 和 Nvidia 都对他们的芯片为何优越有充分的论据。当汽车制造商几乎没有能力定制产品或谈判价格时,他们对支付高昂的芯片成本感到沮丧,这是可以理解的。但汽车行业的高管需要评估自己的核心竞争力,并在走上独立之路之前做出艰难的决定。
为此,他们可以从 Jeff Bezos 和卢森堡啤酒行业获得指导。根据 Amazon.com Inc. 创始人现在著名的演讲,欧洲国家的酿酒商曾经自己发电,因为这是啤酒制造过程中需要的输入,他们无法从集中式电力中获取电力网格。
但对这家酿酒商来说不幸的是,正如他在2008 年的一次演讲中指出的那样,这种繁重的工作没有区别——所有的电力都是一样的——但需要在世界级的水平上完成。他们越快将发电外包,他们就能越快重新专注于酿造。
“他们自己发电的事实并没有让他们的啤酒味道更好,”贝佐斯说。他的劝告今天继续响亮:专注于让您的啤酒味道更好的东西。
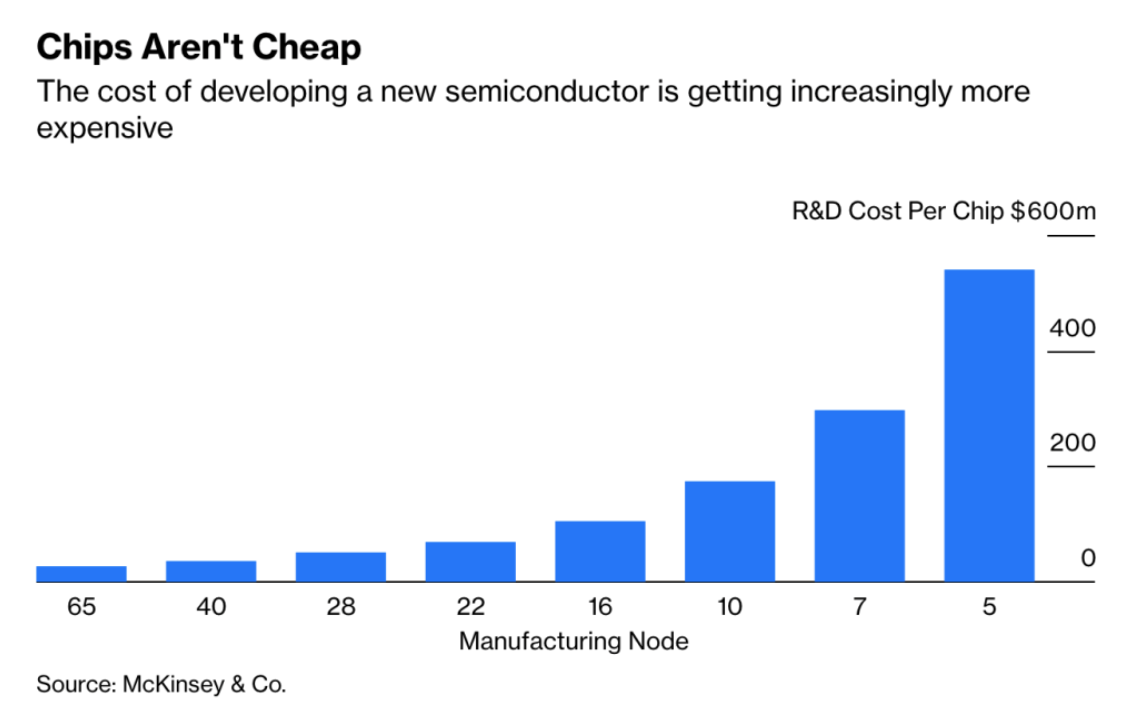
汽车制造商需要进行同样的计算,而且它的成本越来越高。过去十年,随着半导体制造技术的进步,开发新芯片的价格上涨了 10 倍。在将其送去生产之前,每个组件都需要进行设计、验证、测试和原型制作。根据麦肯锡公司的分析,目前最新的 5 纳米制造节点的前期成本为 5.4 亿美元,而11 年前首次推出的较旧的 28 纳米技术的前期成本为 5000 万美元。
英伟达能够承担这些成本的一个主要原因是,它每年通过销售用于计算机显卡、人工智能服务器、数据处理中心和自动驾驶汽车的芯片获得 270 亿美元的收入。设计芯片是英伟达的工作,因此半导体是英伟达的啤酒。
特斯拉和Cruise以及其他所有汽车制造商都需要询问他们的产品与竞争对手的区别是什么。驾驶员做出选择的因素有很多,包括发动机功率和性能、外观、内部设计、安全性和配件。未来,FSD 将只是买家考虑的另一个功能。
而且,设计自己的芯片并不能解决当前的短期供应短缺问题,但它可以让汽车制造商更好地根据自己的需求定制组件,而不是购买现成的产品。性能很可能会优于第三方供应商可以提供的产品,但这并不意味着他们销售的最终产品——汽车——会好得多。多年前, Alphabet Inc 的 Google走上了独立之路,押注为其庞大的数据中心设计定制芯片的好处——并远离英特尔公司——这将使其投资获得回报。大这里的不同之处在于,从谷歌服务器存储和抽取的数据是世界上最大的搜索引擎购买和销售的数据。
汽车制造商要确保他们的半导体赌注是值得的,他们不仅需要相信自动驾驶功能将成为客户购买决定的主要因素,而且他们自己内部开发的芯片是这种差异化的关键。这是一项艰巨的任务。
经过多年的发展,并与越来越高的成本作斗争,汽车制造商很有可能最终会发现,虽然他们自己的芯片更出色,但它们并没有让啤酒的味道更好。
英伟达超强汽车芯片来袭
作为其秋季 GTC 2022 活动的一部分,NVIDIA 早前发布了大量公告,该公司正在对其 DRIVE 汽车 SoC 计划进行令人惊讶的更行,且立即生效。NVIDIA表示将取消Atlan,这是他们计划用于 2025 年汽车的后 Orin SoC。取而代之的是,NVIDIA 宣布推出 Thor,这是一款功能更强大的 SoC,将于 2025 年推出。
NVIDIA 的 Atlan SoC 于 2021 年春季 GTC 首次亮相,NVIDIA 宣布将其作为下一代汽车 SoC,以接替(现在的)Orin SoC。在宣布时,Atlan 计划成为一款高性能 SoC,提供 1000 TOPS 的 INT8 推理性能,采用下一代(Lovelace)GPU 设计和下一代 Grace CPU 设计。该芯片甚至集成了 BlueField DPU 作为网络和安全处理器,旨在提供一个可以处理自动驾驶汽车所需的所有计算功能的 SoC。

但无论 Atlan本应是什么,现在都已不复存在。截至 NVIDIA 新的 DRIVE SoC 路线图,Atlan 已被废弃。取而代之的是一个新的 SoC——Thor,它比Atlan 更强大。
与 2021 年的 Atlan 公告一样,NVIDIA 仅在发布之前发布了有关 Thor 的少数细节。高级细节包括,没有命名特定的 NVIDIA CPU 和 GPU 架构,但 SoC 正在利用 Grace CPU、Ampere GPU 架构和 Lovelace GPU 架构首次引入的功能。与此同时,NVIDIA 关于此事的博客文章确实更进一步,指出 SoC 使用了 Arm 迄今为止秘密的 Poseidon CPU 内核的汽车增强 (AE) 版本。我们对Poseidon 知之甚少,它是 Arm 正在开发的下一代高性能 CPU 内核,将用于其下一代 Neoverse V 系列平台,取代刚刚发布的Neoverse V2。

从性能的角度来看,Thor 计划使用新标准化的 FP8 数据格式提供 2 PFLOPS (2000 TFLOPS) 的浮点推理性能。尽管与 Atlan 的 1000 TFLOPS INT8 数字相比,这不是一个公平的比较,但它仍然代表了 8 位精度计算吞吐量的两倍。SoC 的张量核心还将采用 NVIDIA 的 transformer engines,使 SoC 能够进一步加速transformer networks的处理。
值得注意的是,整合所有这些性能将使 Thor 成为一个非常庞大的芯片。虽然 NVIDIA 没有宣布工艺节点,但他们已经表示它将使用 770 亿个晶体管,这比他们的新旗舰 GH100 GPU 少了 30 亿个晶体管。NVIDIA 的性能声明并未表明是否使用了矩阵稀疏性,但即使是这样,Thor 的 FP8 性能也将是 NVIDIA 旗舰 GPU 的一半。所有这些都突显了 NVIDIA 对计划中的 SoC 的极端性能目标。
虽然 NVIDIA 的芯片模型在 AGX 板上以单芯片配置显示它,但今天的公告还明确提到了 NVLink 芯片到芯片 (NVLink-C2C) 芯片互连技术。这是一个奇怪的提及,因为 NVIDIA 的关键艺术并没有显示 Thor 是基于chiplet的。这可能意味着 NVIDIA 将转而使用 NVLink-C2C 来实现更强大的多芯片 DRIVE AGX 板(ala Pegasus),或者很可能 Thor 是基于chiplet的设计,而 NVIDIA 故意将其通用化艺术。
除此之外,NVIDIA 没有提供有关 SoC 的任何进一步技术细节。因此,有关使用的内存类型、GPU 架构和其他功能块的详细信息仍有待观察。
在这一点上,NVIDIA 也没有详细说明为什么他们取消了 Atlan 来代替 Thor。Thor 无疑是一个更强大的设计,并且似乎包含了一些在 Atlan 上找不到(或至少从未公开过)的新功能。这是否意味着 NVIDIA 正在以某种方式引入本应是后 Atlan 芯片的芯片,或者他们是否因为客户需要更好的自动驾驶汽车 AI 推理性能而放弃了 Atlan,还有待观察。
抛开硬件升级不谈,很明显,NVIDIA 正在为与 Atlan 相同的细分市场设计 Thor。也就是说,它是一种高性能的单芯片设计,用于处理自动驾驶汽车的所有计算需求,从信息娱乐系统和传感器融合到实际的自动驾驶算法本身。与 Atlan 一样,其目标是用一台可以完成所有工作的计算机取代目前汽车内的独立计算机,利用具有广泛隔离(包括 MIG)的功能安全设计技术来防止单独的任务相互干扰。
然而,也许最令人惊讶的是,SoC 的这种变化预计不会影响 NVIDIA 的 SoC 交付日期。英伟达表示,他们将在 2025 年为汽车厂商提供Thor,这与亚特兰的计划到达时间相同。因此,虽然魔鬼在细节中,但在高水平上,英伟达的目标是提供接近相同的Thor时间,因为他们会交付Atlan 。不过值得注意的是,虽然 NVIDIA 此前曾宣布 Atlan 将在 2023 年出样,但尚未发布关于 Thor 的此类公告。因此,Thor 的送样日期可能最终会晚于 Atlan 的送样日期。
英伟达2019年对特斯拉自研芯片的评论原文
在2019年的特斯拉 Autonomy Day 投资者活动中,埃隆·马斯克 (Elon Musk) 公布了他的新型自动驾驶汽车电脑的规格,他向全世界明确了几件事。
首先,特斯拉正在提高所有其他汽车制造商的标准。
其次,特斯拉的自动驾驶汽车将由基于其两个新 AI 芯片的计算机提供动力,每个芯片都配备 CPU、GPU 和深度学习加速器。该计算机每秒可提供 144 万亿次操作 (TOPS),使其能够从一系列环绕摄像头、雷达和超声波收集数据,并为深度神经网络算法提供动力。
第三,特斯拉正在研发下一代芯片,据说 144 TOPS 还不够。
在 NVIDIA,我们一直坚信特斯拉重申的愿景:自动驾驶汽车需要具备非凡能力的计算机。
这正是我们几年前设计和制造 NVIDIA Xavier SoC 的原因。Xavier 处理器具有可编程 CPU、GPU 和深度学习加速器,可提供 30 TOPS的算力。我们基于双芯片解决方案构建了一台名为 DRIVE AGX Pegasus 的计算机,将 Xavier 与强大的 GPU 配对以提供 160 TOPS,然后将两组放在计算机上,总共提供 320 TOPS。
正如我们一年前(2018年)宣布的那样,我们并没有坐以待毙。我们的下一代处理器 Orin 即将问世。
这就是为什么 NVIDIA 是马斯克比较特斯拉的标准——我们是唯一一家以每秒数万亿次操作或 TOPS 来描述这个问题的公司。
但是,尽管我们在大局上同意他的观点——这是一个只能通过超级计算机级系统才能解决的挑战——但特斯拉的演示文稿中存在一些我们需要纠正的不准确之处。
将特斯拉的两芯片全自动驾驶计算机与英伟达的单芯片驾驶辅助系统的性能进行比较是没有用的。Tesla 的 144 TOP 的两芯片 FSD 计算机将与NVIDIA DRIVE AGX Pegasus 计算机进行比较,后者在 AI 感知、定位和路径规划方面以 320 TOPS 运行。
此外,虽然 Xavier 提供了 30 TOPS 的处理能力,但特斯拉错误地声称它提供了 21 TOPS。此外,带有单个 Xavier 处理器的系统是为辅助驾驶 AutoPilot 功能而设计的,而不是完全自动驾驶。正如特斯拉所说,自动驾驶需要更多的计算。
然而,特斯拉最重要的问题是完全正确的:自动驾驶汽车——这是提高安全性、效率和便利性的关键——是该行业的未来。它们需要大量的计算性能。
事实上,特斯拉认为这种方法对行业的未来非常重要,因此它正在围绕它建立自己的未来。这是前进的道路。其他所有汽车制造商都需要提供这种水平的性能。
只有两个地方可以获得 AI 计算能力:NVIDIA 和 Tesla。其中只有一个是可供行业构建的开放平台。
