ASIC,风潮降至
随着机器学习、边缘计算、自动驾驶的发展,大量数据处理任务的产生,使得人们对于芯片计算效率、计算能力和计能耗比都提出了很高的要求,在此背景下,ASIC得到了越来越多人的关注。
1981年3月,Sinclair公司推出了一款8位个人电脑ZX81,其中的Z80处理器则被认为是最早的ASIC原型。ASIC(Application Specific Integrated Circuit)芯片是专用集成电路,是针对用户对特定电子系统的需求,从根级设计、制造的专有应用程序芯片,广泛应用于人工智能设备、虚拟货币挖矿设备、耗材打印设备、军事国防设备等智慧终端。在硬件层面,ASIC 芯片由基本硅材料、磷化镓、砷化镓、氮化镓等材料构成。在物理结构层面,ASIC 芯片模块通常包括 32 位微处理器、存储器块、网络电路等。
01
不同的ASIC芯片
ASIC 芯片可根据终端功能不同分为 TPU 芯片、DPU 芯片和 NPU 芯片等。其中,TPU 为张量处理器,专用于机器学习。如 Google 于 2016 年 5 月研发针对 Tensorflow 平台的可编程 AI 加速器,其内部指令集在 Tensorflow 程序变化或更新算法时可运行。DPU即Data Processing Unit,可为数据中心等计算场景提供引擎。NPU 是神经网络处理器,在电路层模拟人类神经元和突触,并用深度学习指令集直接处理大规模电子神经元和突触数据。
ASIC 有全定制和半定制两种设计方式。全定制依靠巨大的人力时间成本投入以完全自主的方式完成整个集成电路的设计流程,虽然比半定制的ASIC 更为灵活性能更好,但它的开发效率与半定制相比甚为低下。 ?
随着功能模块电路和单元库的设计日趋成熟,半定制的ASIC 设计逐渐取代了全定制方法。设计人员可以更为轻松地直接使用预先完成的单元库中的标准逻辑单元进行设计,或使用门阵列的方式,现在用全定制方法进行完整电路设计的情况很少出现。基于标准逻辑单元和基于门阵列是当前半定制的ASIC 设计主要采用的两种设计方法。 ? ?
基于标准单元的方法直接从单元库里挑选标准逻辑单元,诸如各种中小规模的集成电路单元和门级、行为级甚至系统级电路模块,这些标准单元在进行ASIC设计使用之前已经被预先设计好并经过了严格的设计规则验证,可靠性很高,半定制的设计人员可以直接从单元库中拿来进行系统设计,使用方便。 ? ?
基于门阵列的方法是在互联金属层排列形成的晶体管阵列上,以全定制确定掩膜,通过掩膜之间的互相连接完成设计,这种门阵列由其突出的形式故被称为MGA(掩膜式门阵列)。门阵列库在相同逻辑单元版图的基础上,定制金属的互连线。
ASIC 设计的流程自顶向下——“Top-Down”的设计思想通常为基于标准单元的ASIC 所采用,其设计基本流程图所示。
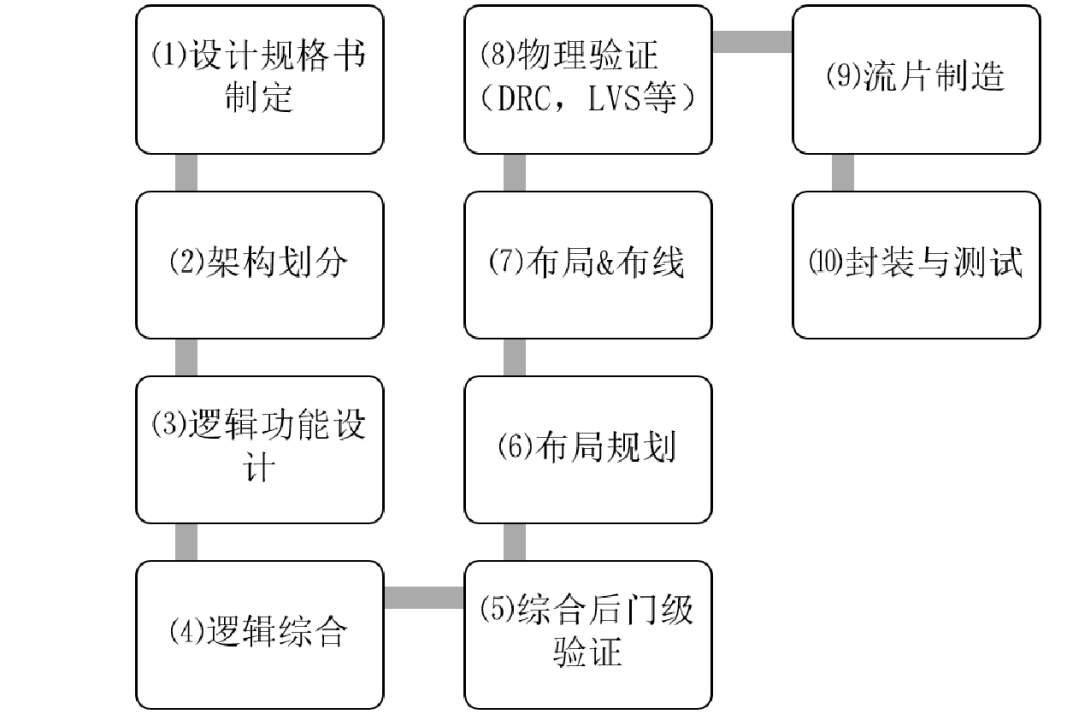
02? ?
ASIC和CPU、FPGA等对比
ASIC和CPU、FPGA等对比CPU :基于低延时的设计,有强单次逻辑处理能力,但面对有限功耗的大量数据处理能力有限。中央处理器?CPU 需要很强的处理不同类型数据的计算能力以及处理分支与跳转的逻辑判断能力,这些都使得 CPU 的内部结构异常复杂.深度学习模型需要通过大量的数据训练才能获得理想的效果。骤然爆发的数据洪流满足了深度学习算法对于训练数据量的要求,但是算法的实现还需要相应处理器极高的运算速度作为支撑。当前流行的包括 X86 和?ARM?在内的传统 CPU 处理器架构往往需要数百甚至上千条指令才能完成一个神经元的处理,但对于并不需要太多的程序指令,却需要海量数据运算的深度学习的计算需求,这种结构就显得非常笨拙。尤其是在当前功耗限制下无通过提升 CPU 主频来加快指令执行速度,这种矛盾愈发不可调和。? ??
GPU:较成熟生态系统,最先受益人工智能爆发。GPU 与 CPU 类似,只不过是一种专门进行图像运算工作的微处理器。GPU 是专为执行复杂的数学和几何计算而设计的,这些计算是图形渲染所必需的。GPU 在浮点运算、并行计算等部分计算方面可以提供数十倍乃至于上百倍于 CPU 的性能。但其有三个方面的局限性:1.应用过程中无法充分发挥并行计算优势。2.硬件结构固定不具备可编程性。3.运行深度学习算法能效远低于 ASIC 及 FPGA。 ? ?
FPGA:能效中等、灵活度高、成本较高的 AI 白板,具有三类局限。FPGA 称为现场可编程门阵列,用户可以根据自身的需求进行重复编程,与 GPU、CPU 相比,具有性能高、能耗低、可硬件编程的特点。同时具有三类局限:1、基本单元的计算能力有限;2、速度和功耗有待提升;3、FPGA 价格较为昂贵。 ? ?
ASIC :专为特定目的而设计。不同于 GPU 和 FPGA 的灵活性,定制化的 ASIC 一旦制造完成将不能更改,所以初期成本高、开发周期长的使得进入门槛高。目前,大多是具备 AI 算法又擅长芯片研发的巨头参与,如 Google 的 TPU。ASIC 芯片有以下几个优势1.规格优势:ASIC 芯片在设计时充分利用单位运算单元功能,避免冗余计算单元存在,有利于缩小芯片体积。2.能耗优势:ASIC 芯片单位算力能耗相对 CPU、GPU、FPGA 较低,如 GPU 每算力平均约消耗 0.4 瓦电力,ASIC 单位算力平均消耗约 0.2 瓦电力,更能满足新型智能家电对能耗的限制。3. 集成优势:因采用定制化设计,ASIC 芯片系统、电路、工艺高度一体化,有助于客户获得高性能集成电路。如TPU1 是传统 GPU 性能的 14-16 倍,NPU 是 GPU 的 118 倍。寒武纪已发布对外应用指令集,ASIC 将是未来 AI芯片的核心。
03
ASIC的未来如何
ASIC 芯片及其配套产品在下游智慧家电市场已初步形成应用模式,具有广阔市场空间。受物联网趋势影响,如美的、格力、海尔、海信等家电厂商相继布局各类智能家电产品。通过嵌入 ASIC 芯片,家电产品制造商可获得更高利润,推动智慧城市建设。 ? ?
谷歌开发的优化算法架构 Tensor Processing Unit,TPU在算法架构上介于 CPU 和全定制化 ASIC 之间,兼具桌面计算设备与嵌入式计算设备功能。TPU 算法具备较宽容错性,在硬件组成上相对 CPU 类通用芯片更加简洁。相同数量晶体管条件下,TPU 算法架构的 ASIC 芯片可完成更高运算量。相对同级别CPU、GPU,该类 ASIC 芯片可提高运算性能 15 倍至 30 倍,并提高能耗效率 30 倍至 80倍。另外如思科推出防火墙专用 ASIC 芯片在算法上采用网络加速协议,高通推出基带专用ASIC 芯片采用通信协议、傅里叶变换等优化算法。自动驾驶运算系统处于快速更迭、进化阶段,或于 5 年内进入算法稳定阶段。专家指出,基于固定算法最优化设计的ASIC芯片将成自动驾驶运算系统主流核心模块。
因 ASIC 算法架构更接近底层 算法且在物理结构上大幅缩减冗余晶体管和连线,ASIC 芯片在运算吞吐量、延迟度、功耗等参数方面表现优于传统芯片。现阶段自动驾驶系统核心芯片已从 GPU 转向 FPGA,并逐步向 ASIC 过渡。相对 FPGA 芯片,ASIC架构下,自动驾驶系统计算效率、计算能力皆可定制,一旦达到量产规模,其平均成本将低于 FPGA 芯片。相同工艺条件下,ASIC 计算速度约为 FPGA 运算速度 5 倍及以上。
04
国内外发展现状
ASIC芯片在芯片行业正在受到重视。包括DPU和NPU等类别。DPU主要承担网络、存储和安全的加速处理任务,旨在满足网络侧专用计算需求,尤其适用于服务器量多、对数据传输速率要求严苛的场景。具体看来,DPU对CPU所不擅长的网络协议处理、数据加解密、数据压缩等数据处理任务,可以顺滑地接手,并且对各类资源分别管理、扩容、调度。2020 年上半年,NVIDIA以69 亿美元的对价收购以色列网络芯片公司 Mellanox Technologies,并于同年推出 BlueField-2 DPU,将其定义为继 CPU 和 GPU 之后“第三颗主力芯片”,正式拉开 DPU 大发展的序幕。
谷歌公司日前在I/O 2022活动中发布其新一代张量处理器TPU v4集群,该公司CEO Sundar Pichai介绍称,新的算力集群被称为Pod,包含4096个v4芯片,可提供超过1 exaflops的浮点性能,Pichai表示其将在位于俄克拉荷马州的数据中心部署8个TPU v4集群,合计实现约9 exaflops的性能,
今年8月,英特尔Agilex FPGA 和 Stratix 10 NX FPGA 两大产品已部署至中国创新中心。英特尔 Agilex FPGA 集英特尔 SuperFin 制程技术、Chiplet、3D 封装等众长于一身,在生产、工艺、封装、互连等方面较前代产品有明显进步,能够广泛应用到 5G、人工智能场景中,为以数据为中心的世界提供敏捷性和灵活性。相较于英特尔Stratix 10 FPGA,英特尔 Agilex FPGA 性能提高了 45%,功耗降低了 40%。
国内也在ASIC市场上发力。阿里巴巴正式对外发布了全新的含光800AI芯片。平头哥含光800芯片性能的突破得益于软硬件的协同创新:硬件层面采用自研芯片架构,通过推理加速等技术有效解决芯片性能瓶颈问题;软件层面集成了达摩院先进算法,针对CNN及视觉类算法深度优化计算、存储密度,可实现大网络模型在一颗NPU上完成计算。
中科驭数设计了业界首颗网络数据库一体化加速功能的DPU芯片和智能网卡系列产品。创始团队来自科研院所,正开展第三代DPU芯片K2 Pro的研发工作,致力于DPU芯片的国产替代。OPPO发布自主研发的影像专用NPU芯片“马里亚?MariSilicon?X”。
寒武纪公司出品的diannao系列NPU芯片。2021年8月18日,百度在世界大会上,推出了自家的首款7nm自研“昆仑2代AI芯片”。昆仑芯2的性能、通用性、易用性较1代产品均有显著增强。该芯片采用全球领先的7nm 制程,搭载自研的第二代 XPU 架构,相比1代性能提升2-3倍。整数精度(INT8)算力达到256 TeraOPS,半精度(FP16)为128 TeraFLOPS,而最大功耗仅为120W。
ASIC深度学习,数据中心、边缘计算等各个领域都得到了广泛的应用并正在飞速发展.
更多信息可以来这里获取==>>电子技术应用-AET<<

