火山引擎韩云飞:数据驱动的ROI将无限大 原创 精选

嘉宾 |?韩云飞
整理 | 云昭
字节跳动内部有着非常浓厚的数据文化和实验文化,数据中台已经成为研发流程中的新基建,A/B测试也基本上是整个研发链路上的必经一环。那么如何将数据驱动有效应用在研发体系中呢?
日前,在51CTO主办的WOT全球创新技术大会上,火山引擎DataTester技术负责人韩云飞从“研发流程中无处不在的数据驱动”、“如何建立可持续的数据驱动文化”、“数据驱动的ROI”三个方面,带来了以“构建数据驱动的新型研发体系”为主题的精彩分享。现整理如下,希望能对诸君有所启发。
无处不在的数据驱动
字节跳动在整个研发流程中,数据驱动无处不在。首先,以火山引擎的AB测试为例,探究研发流程中数据驱动。

火山引擎A/B测试,由来已久。包括抖音、今日头条的名字都做过A/B测试,今天再爆个料,西瓜视频的名字也做过A/B 测试,我还有幸参与过这件事,当时取的名字叫“咸蛋视频”,如果没有AB测试,也许现在用的就是“咸蛋视频”这个名字。
平台自建立之初至今,已经承载着500+业务线、150W+实验总量的能力,日新增实验2000+,同时运行试验3W+的。
AB测试,究竟是怎样支撑这样海量的实验和这么多的并行度的呢?
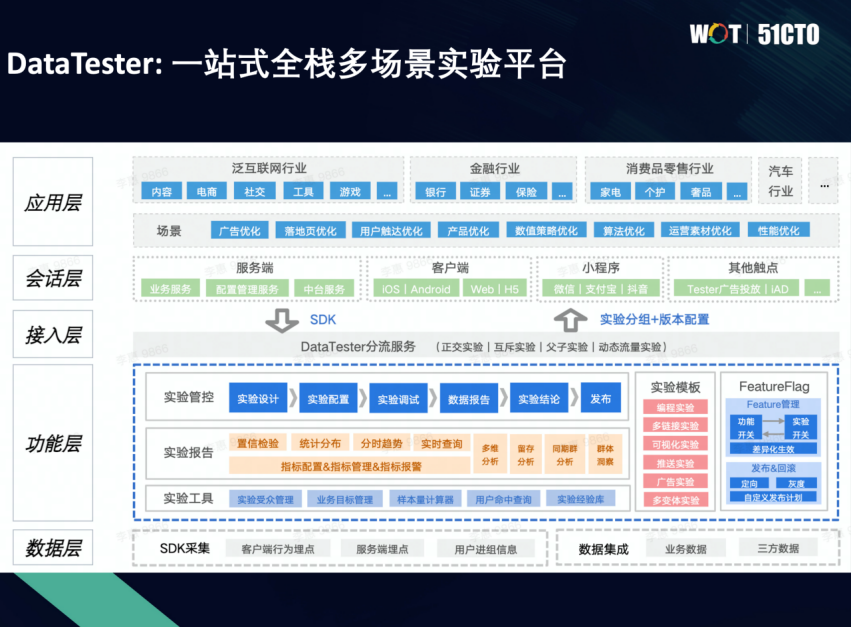
首先在数据层我们是有SDK来采集我们端上的埋点和服务端的埋点,还包括用户进组的信息。在数据集成上,其实我们会有大量用户业务的数据和第三方的数据,我们通过数据集成的能力把它进入到我们的系统。
在功能层,它又分成几个模块。首先是从整个实验的设计、实验的配置、调试、数据报告,包括这种出结论,以及上线发布,这些都归由实验管控的模块来负责。
做实验最重要的是要来评估报告,所以我们在实验报告里面其实提供了包括执行度的检验、统计的分布,包括实验数据的趋势,还有一些指标的配置。还有更多的能力,这里不再赘述。
除此之外,我们还配套了一些比较好用的工具,包括比如说实验受众管理,因为我们做实验其实有时候会针对于特定的用户群体,比如我的新用户,某个城市的用户,甚至于说它有一些用户的画像。
还有业务目标管理,随着接入的业务线越来越多,我们是想沉淀出可复制的经验,可能用于提升留存,或者是其他的业务目标,进一步将它拆解成业务上有哪些事要做,最终通过指标跟实验之间建立关联,未来其他的业务线再做类似的事,或者同一个业务线到了第二年,可以考量之前针对这个指标到底做了哪些实验。
除此之外,我们还提供了端到端的实验模板,包括比如编程实验、多链接实验、可视化实验,还有针对于不同的场景,推送运营的实验等。
在接入层其实我们提供了SDK以及分流,来给各种业务系统包括会话层的服务端、客户端,还有一些to B的其他的小程序做一些对接。
应用层,我们提供了面向不同行业的解决方案,包括比如在泛互联网,其实泛互联网分得更细,有内容、电商、社交、工具。金融其实包括银行、证券、保险,也都会用到这样的能力。包括在大消费的行业,比如包括家电、客户、汽车行业等等。
接下来,我们一起看看研发流程中怎么使用数据驱动。?
开发新功能的正确姿势是什么?
假设PM提了一个需求,如果要给抖音增加一个“熟人tab”,如果在数据驱动情况下,我们是怎么做这件事呢?
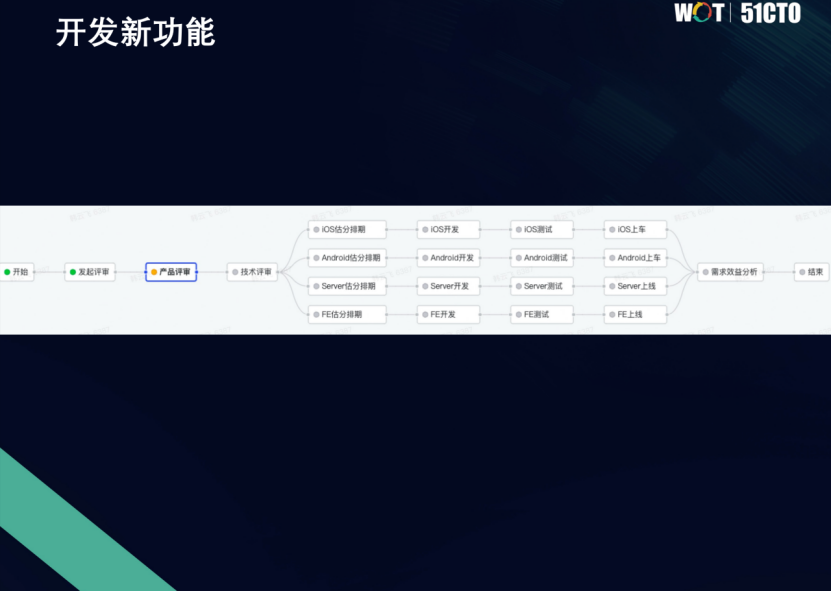
我们在产品评审的环节之后,会增加两个东西,一个叫做埋点的设计,一个叫做AB方案的设计。其实从前面开始,PRD的方案开始,就可以猜出来,它可能是提供了不只一种方案。tab,到底是加在顶部,还是加在底部?策略到底应该是什么样的。这是一个不确定的事。
草率的决定可能会对整个抖音大的生态有很大的影响。所以其实是需要来试验,先小规模、小流量的来试验。
我们可能就有这样一个方案。

比如我们有了V1组和V2组,把熟人tab加了进去。这时候通过验证各自的流程时长等指标得到最终的实验结论,发现V2组是比较好的,对社交价值有更为显著的提升,就把这个方案全量上线。?
怎样才能做好一次复杂系统重构?
今日头条是一个通用信息平台。头条早期的信息流服务是用一个Python的单体服务。随着业务发展迅猛,流量在爆发式增长,业务工程上的复杂度也在急剧升高。为了更好地长期支撑业务发展,信息流同学做了一次大规模的服务化重构:
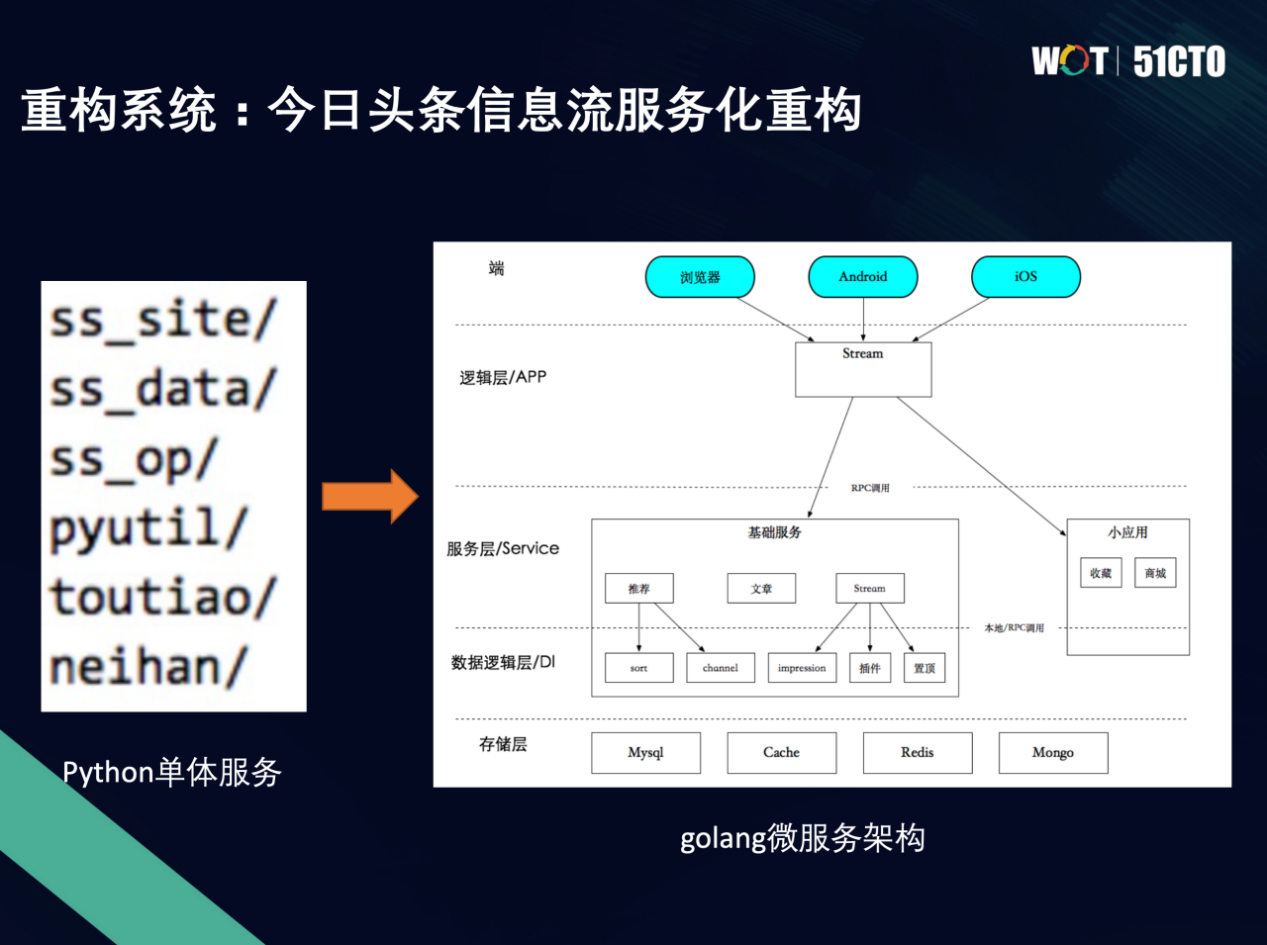
语言选型从Python切换到了golang,从单体服务架构演变成了分层的微服务架构。以往大家做重构时更多关注质量、性能等技术上的指标,以为这样就够了,其实是对用户体验和业务目标的忽视。这样一次大规模重构,设计实现并没有太久,但需要保障重构的信息流服务在各种业务指标上是不能有损的,这就花了大半年的实验去做AB测试,通过几十次AB测试不断的灰度,分析业务指标影响,最终在大部分全局指标几乎没有影响,甚至有些关键指标正向的情况下完成了这个复杂系统大规模重构上线。
Bugfix难道不是应该修复完就上线?
这是一个我们直播的场景,整个直播的实验背景我介绍一下。在一个精排的模型里用到了抖音的Universal Embedding,用到了一些特征,我们在召回阶段也用一下这些特征,能够让召回的模型学习到更多信息,提前做一些召回符合用户兴趣的一些内容,保持召回和精排在一致性的情况下,能够提升一些指标。

这个想法很好,但是由于配置的问题,导致文章的一些内容特征获取是失败的,这个功能没有成功上线。现在对这个功能做了fix,那是不是fix完就能直接上线呢?其实是未必的。这个bug你会发现它很隐蔽,它不会造成用户很明显的感知,但是你的系统跟你设想的是不一致的。即使修了但是不是真的修了就是好的呢?我觉得也未必,因为这个系统本身太复杂了,加了这个特征,如果没有用,但它让系统变得更复杂了,也不是一件好事。更不用说还有负向的风险。所以我们还是采用了AB测试。我们分了新用户、老用户分别去测,发现对于新用户其实是没有什么实质性的影响,指标就是在波动。这是可以理解的,新用户可能本身就没有太多的特征可以用。对于老用户实验,我们发现在他的人均的展现上和人均的阅读上,都有0.3%左右的显著提高。这个数字可能不高,但是对于抖音的体量,提升这么多,其实已经是非常大的了。
上线发布如何更安全丝滑?
说下上线发布的例子,比如整个微服务中,上游服务对下游服务的调用过程中,很多流量直接打到各个机器上。在一些场景上,这么做会有一些问题。比如说新模型上线,模型需要机器来承载,在测试阶段的流量显然是远远不及真实上线时那么大。那么上线时能不能让流量直接打过来,以及上线过程中重启机器等等是否会带来一些不太好的影响,这都是需要做AB测试的。
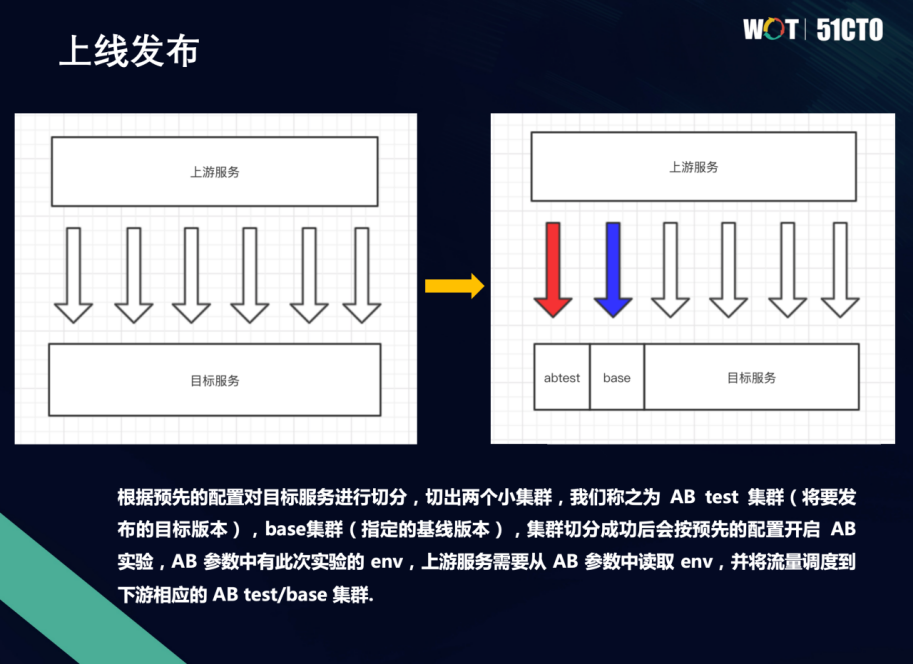
所以我们针对于上线场景,把AB的能力开放给基础架构部门。首先根据预先的配置对目标服务进行切分,切分成不同的集群,比如说里面有AB的集群,还有基线版本的集群。集群切分之后,会调平台的OpenAPI来开启实验,实验里面配了一些环境参数,比如叫env。上游服务会通过RPC框架跟我们AB之间有一个交互,能读到环境参数具体是什么,然后它就能够把它的流量正确的调度到下游相应的集群。
这个过程中,需要多大流量,分配多少机器,开发人员可以通过OpenAPI是能够把这两件事关联起来的,可以得到恰当的处理。线上的整个升级包括重启机器等都可以非常平稳、非常丝滑。?
SQL优化让人秃头,怎么破?
再比如Spark SQL的优化,首先想做好优化,你需要知道mapper数、reducer数、excutor数等参数怎么设置,还要面料executor堆内内存不够、driver堆外内存不够、序列化结果过大等让人头大的错误。
其次,SQL运维优化会花费大量的人力,随着数据量的上升,随着整个逻辑越来越复杂,包括其执行的环境也会变化。一次好的优化不一定永远都是对的,可能需要随着数据量上涨、需要随着环境的变化不停地去调,有可能未来也变得很差。我们有一些SQL专家是非常厉害的,他的SQL优化经验都可以写成一本书了,写的SQL也确实比平均水平好很多倍。但是让每位同事都具备SQL优化的能力,其实既不现实,也没有太大的必要。
针对这件事怎么做更好呢?我们大数据的同学想到了AB测试。
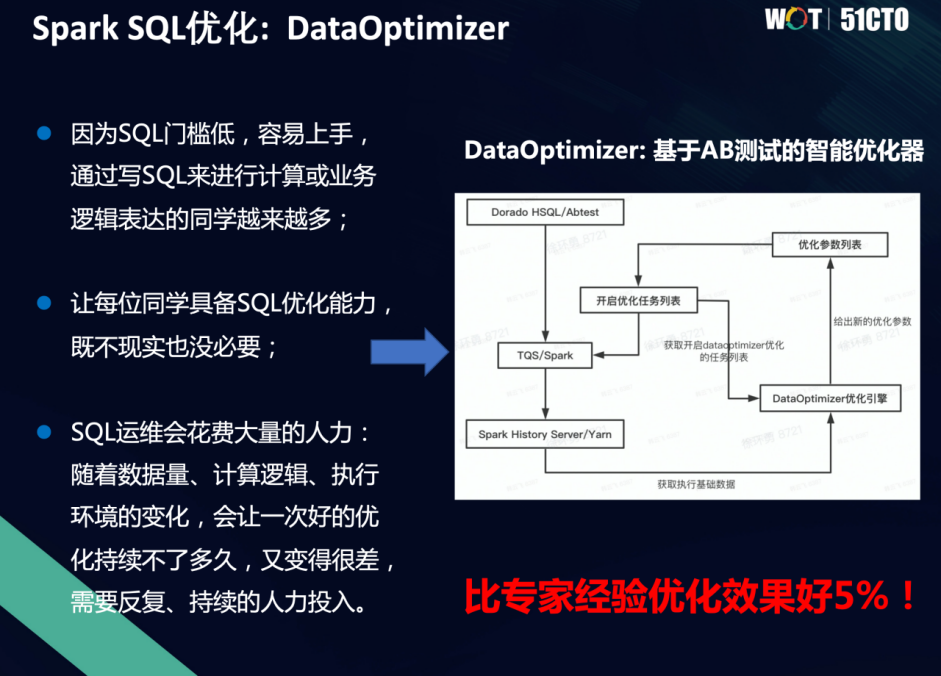
在数据提交的阶段引入AB测试,在开启任务的时候能够开启一个优化列表,这个过程中我们团队开发了一个叫做DataOptimizer的优化引擎,会根据任务来不断优化,比如它历史跑的执行情况,环境数据等,最终会让你进行一些调优,调完之后看效果。最终我们发现,这套优化系统会比专家经验还要好5%。
AB测试作为研发全流程基础设施
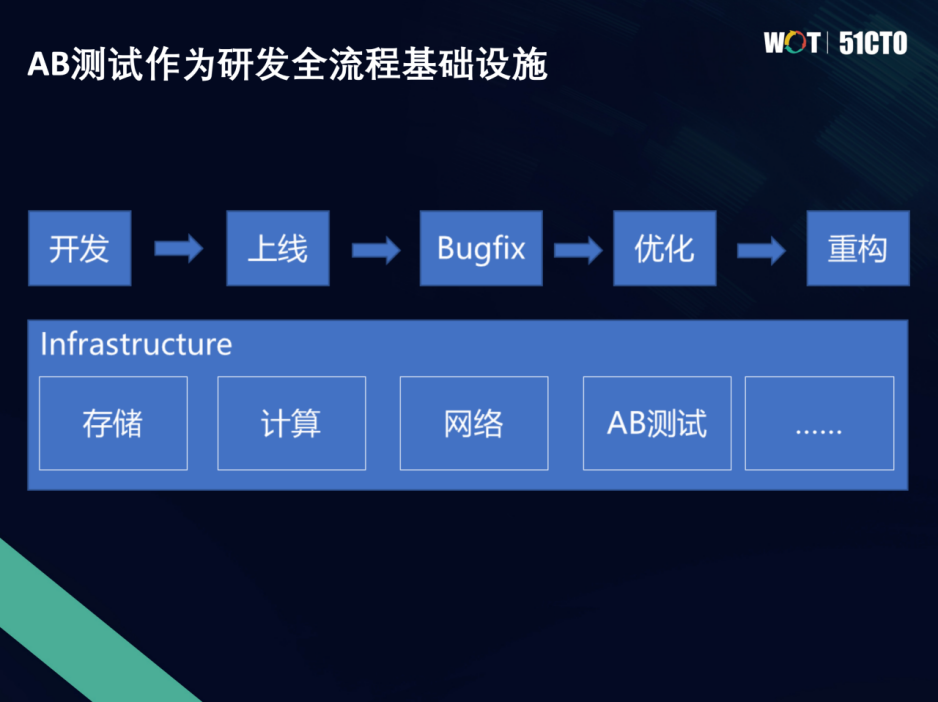
因此,把刚才的案例串联起来,包括开发、上线、BugFix、优化、重构。你会发现在整个研发流程中,其实AB测试是可以像存储、计算、网络一样,作为一个基础设施来服务于整个研发流程。通过刚才的例子,大家应该会比较有体感,在我们整个研发的日常流程中,怎样去把它用于我们的工作实践,成为我们一个得力武器。
建立可持续的数据驱动文化
第二部分介绍一下基于我们前面的大量的实践,我们总结出来怎么样能够在一个公司内去建立一个可持续的数据驱动的文化。
前面说了很多案例,其实就是想让大家更深有体会,通过这样大量的实践,得出来一些小小的知识,就是怎么来建立可持续的数据驱动的文化。
字节跳动的数据驱动的文化是怎么建立的?从我个人来看,我认为有三件事是非常重要的。

价值观:从企业基因上鼓励数据驱动
第一,价值观。整个公司的价值观是不是在引导数据驱动这件事,我做数据驱动是不是被鼓励的、被允许的,不会是跟价值观相违背的。
其次,我们会有一些平台、工具来承载大家日常去做数据驱动这件事。
再次,在机制流程上我们有一个叫做Launch Review的机制,它来确保大家在日常中不会被变形,是真的在做数据驱动,而不是在做一个假的数据驱动。
我分别介绍这三部分。
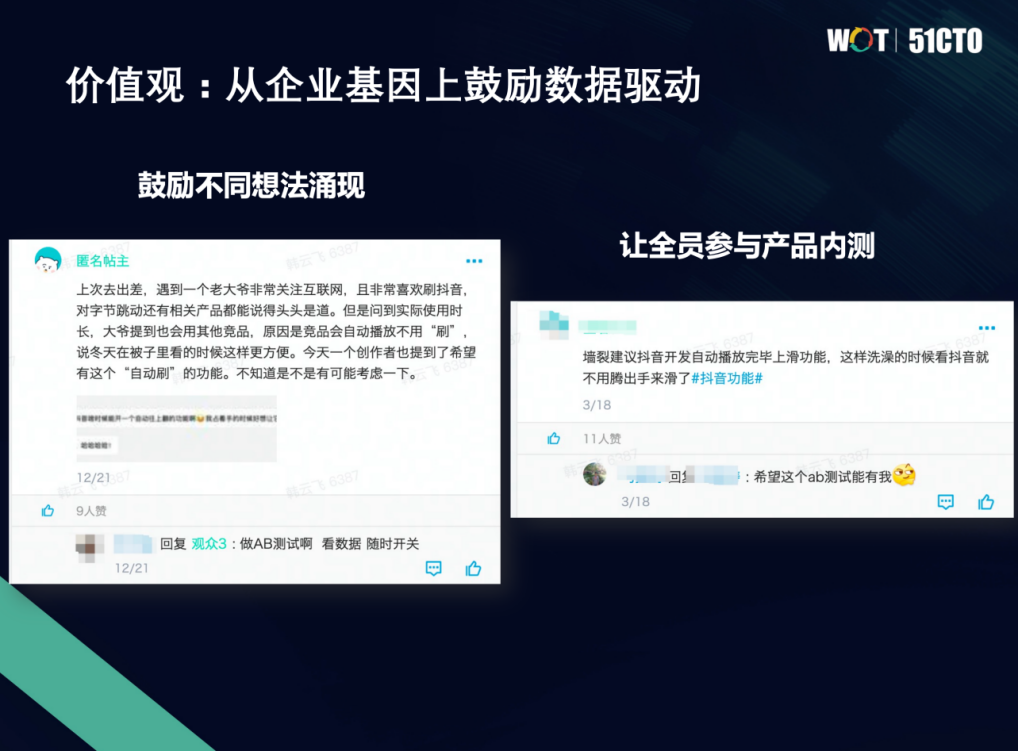
首先第一部分价值观,要从整个企业的基因上去鼓励大家去做数据驱动,这里我截了几个我们字节圈的截图。这个例子是说,上次去出差,遇到一个老大爷,非常关注互联网,喜欢刷抖音。他说了好多问题。但是他又提到,竞品的自动播放不用刷,但是冬天特别冷,可能没有暖气,可能会比较舒服。还有一些创作者也提出来这样的功能,就是我们公司比较鼓励大家提出想法,包括跟用户去交流。
大家直接就说,你其实可以做一个AB测试,或者我们把这个反馈给相关的抖音的业务部门,让他们来做这样一个尝试,看是不是有收益的,或者能够对用户非常友好。所以我们其实是鼓励大家不同的想法去涌现的。
第二个例子,其实跟这个有点相似。抖音自动播放完毕之后,上滑的功能,其实跟上面这个需求是非常相似的。其实已经在做了,就有同学说,我希望能够加入到这个内测,先体验体验。
还有两个例子更生动有趣的例子。
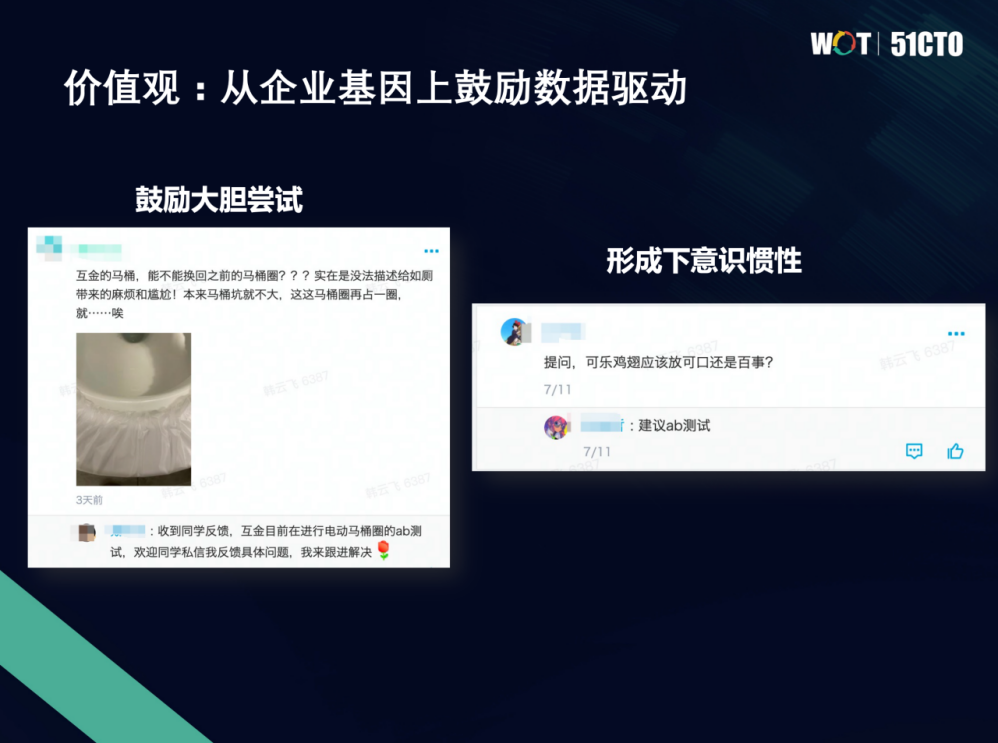
我们在北京有很多工区,有一个互金的工区,有一天行政把马桶圈给换了,有同学就反馈说,好像很尴尬,非常麻烦。我们行政的同学就在下面回复,其实这件事是我们在做一件AB测试,是非常小的流量,只不过这个同学比较倒霉,刚好可能命中了实验组。我们的行政同学就跟进去解决。其实你会发现,到行政这样离研发流程非常远的序列都在积极参与,已经在尝试把数据驱动的理念用于他们的生产。我觉得我们做研发就更需要做了。
其次,还有大家已经形成了很多段子,比如大家在内网发“我要做可乐鸡翅,到底是应该放可口可乐还是放百事可乐”,其实这个问题猛然问到你,你可能也不一定能那么好的回答起来,到底哪个口味更好,这个就需要试,有同学就说你需要自己在家AB测试一下。
数据平台:从数据应用把门槛降到最低
刚才讲到价值观和企业文化,接着我们讲第二个,我们需要一个好的工具。前面的分享讲了底层基建,怎么样把数据弄进来,大家直接可以看数据,怎么治理数据之类。到这里其实我们想强调的我们的特色我们是在数据应用层做了比较多的工作,去降低大家的使用门槛。

我们拿三个我们的数据应用层的工具举例。比如我们的DataFinder,它其实是一个用户行为分析的工具。它有两个典型的功能就在降低门槛。一个叫做场景模板,它会根据大家不同的业务场景,甚至于不同行业的需求,可能有40多个模板,企业来了之后,也许可能一开始不知道怎么样把看板搭起来,这个模板就给你参考,告诉你要做运营该怎么做,我要做支付转化该怎么建看板。其次我们还提供了看板的洞察,就是背后我们其实用了一些AI的能力,这个数据假设有一些波动,我们告诉你它可能真的是波动了,虽然每天都在波动,有一些集群点的偏离,发现它也许有一些有意思的地方,我们会把这个东西告诉你,我们帮你分析出来这个点,也许它不一定是完全对的,但可能我们会有一个概率的保证。但它就相当于代替了一部分大家原来手动分析的功能。
我们的DataTester就是AB测试的工具,里面也提供了可视化编辑的能力,我们把SDK接入之后,我们的一些PM、运营同学可能直接就在网站上比如改变一下它的Slogan、改变一下它按钮的文案、甚至一些颜色,能做一些所见即所得的AB测试。在运营触达上也是,我们接通了很多通道,运营、增长的同学来到我们平台上,可以直接测试一下不同的推送时机、不同的推送文案、不同的频次,想到的都可以去试。
还有一个DataWind,它是一个BI的工具,它提供的其实就是可视化的拖拉拽分析,在有这个平台之前原来是写SQL非常多,但仍然还是会有更多人不会写SQL。我们通过把想要的数据,比如它的一些指标、维度通过拖拽建立一个数据集,直接就能去使用。这里面也提供了一些比较偏智能化的能力,比如自动归因,来帮你发现整个数据集、数据看板中的一些增长/下降是什么维度上的变化引起的。
总之,这些能力都是在帮助大家降低门槛。
Launch Review:业务一号位的科学决策流程
Launch Review是字节的一个传统,公司业务线负责人会对大家做的事情进行科学决策,具体的流程流程如下。
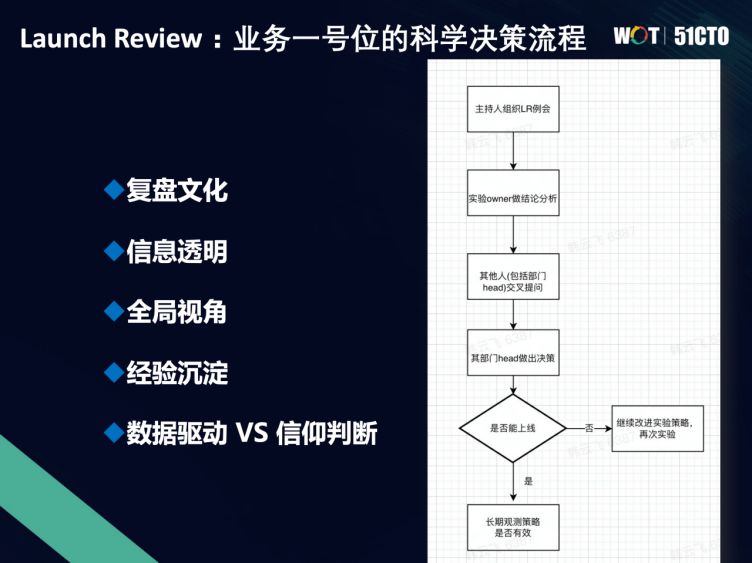
每一周或双周,我们部门都会主持这样一个例会,大家会对做的一些算法迭代的实验或者产品的实验,来做一个总结分析。中间会有包括部门的负责人、业务方、peers等很多人来听,大家会进行提问和互动。但最终是要部门的一号位来做出决策,确定是不是能上线。
有时候实验做得正向了,并不一定能上。如果只是在某些指标正向了,但是在一些更重要的地方没有做出改进,甚至可能让整个系统变得更复杂了,但收益提升却不足够,这样也上不了,这样要去考虑更好的方案。有时候你会发现它负向了,也能上,为什么也能上?大家会判断,它可能损失了一些时长,甚至影响一部分广告收入,但是用户体验变得更好了,或者对产品这个阶段是非常重要的,也许这个事情是可以上的,这都需要部门的领导业务一号位来做好平衡。
总结一下,这个流程体现了下面几个点。
复盘的文化:复盘是需要天天做,日常每天都要做的,我做这件事到底它的价值是什么,SWOT分别是什么。
保持信息透明:我要上线了,这件事是怎么做的,为什么做,5W1H到底是什么,大家要始终保持信息透明的。比如推荐系统有那么多工程师在改进,现在就是一个非常黑盒的系统,但是对于部门的一号位或者非常核心的负责人来说,他还是要非常清楚里面的一些关键的东西到底是怎么work的。
全局视角:其实通过这个机制,就能保证大家每次上新的东西的时候,他们会思考这个东西对我既有的系统加上去之后,整个系统是长什么样子,这样能够帮助业务一号位总揽全局,这样在新的改进加进来之后,才能做出更趋全局最优的决策。
经验沉淀:我们通过这种比较开放的会议,鼓励让大家都能参与进来,互相借鉴,也许抖音做了一件什么改进,头条的人说我也可以拿去试试,这样大家的想法收益就能够无限的放大。
数据驱动VS信仰判断:正向的不一定能上,负向的也许可以上。数据驱动不是唯一,数据驱动是你要在业务价值信仰之间跟数据驱动之间做一个平衡和判断,它是来辅助人的科学决策。
数据驱动的ROI
前面讲了怎么建立数据驱动的文化,但是在降本增效的大背景下,如果要落地数据驱动,它的ROI应该是什么样的,是不是值得大家去做呢?
数据驱动的成本
我们先讲成本。首先有这样三件事:
第一,我们需要在企业文化上进行数智化转型,这里我用了智能的“智”,而不是数字的“字”。这是有区别的,我们不能光是有数据的,还需要数据要真正驱动业务。数据如何跟业务结合,来辅助进行决策。
第二,我们需要在整个研发流程上做数智化转型。因为很多互联网企业、科技企业很重要的流程就是在做产品的研发、业务的研发,最终在最核心的流程中是否能够让数据被驱动,而不是让大家在一个错误的方向上越走越远,这也是非常重要的。
第三,为了完成以上两点的落地,需要搭建一个以数据驱动的基础设施,这里有两种方法,一个是自建,可以根据自身的实际情况来进行,再一个是外采,最终要能帮助业务来实现价值。

总结成一句话,你需要让整个企业变成一家数字原生的企业,这就是付出的成本。
当企业变得数智化原生,意味着企业进化得更好了,这本身也是一种收益。
这里再分享个小故事。我们之前有个用户,后来他从A公司离职了,去创业了,去到B公司,他刚到B公司又采购了我们的产品。后来我们就经常会跟他交流,你为什么那么快就想到用我们的产品呢?他说他们对工具还是非常挑剔的,企业办公用Lark、产品设计用Figma、AB测试就用DataTester。他解释说,除了好用,还能间接帮助他们融资。对工具的挑剔给投资人留下了深刻的印象,最终体现出团队品味、能力和前景。
数据驱动的收益
讲完成本,我们来看下收益。数据驱动的收益,一言以蔽之,“帮助业务团队低损耗地朝正确方向持续小跑!”

第一,它能激发创新,提升收益。只有大家对业务比较有Owner意识,才能去贡献自己的想法,才能激活这个企业的发展,大家才会有更多的创新涌现出来。
其次,我们能够低成本低去试错,就是试错成本会降低,人效是提高的。比如通过AB测试要搞两个版本,好像听起来成本是增加的,其实是未必的。也许你拍的那个版本压根儿没有用,甚至带来了比较大的负向,这个损失是更大的。我们通过在非常小的范围去做这样的验证,反而是降低成本,提高人效的。这个对应的,可能有一定的损耗,它的损耗对应的收益是,你能持续一直做正确的决策,你也不用做AB测试,但是谁能保证你一直对呢?所以数据驱动是有损耗的,但它的损耗是可接受的必要成本。
再次,通过数据驱动是能够积累大家的经验的,最终提升整个团队的决策力。我们刚才讲的Launch Review,它其实是让整个团队共同决策个通过数据驱动最终实现了一个决策的平民化和公平化。
最后,我们整个研发流程做的大部分事情,收益是可以被量化的,这样就知道什么改进对业务帮助更大,最终就能赋能给我们公司的管理团队,让大家在管理上有更好的科学的辅助。
这就是我想讲的整个数据驱动的收益。
嘉宾介绍

韩云飞 火山引擎DataTester技术负责人
火山引擎DataTester技术负责人韩云飞。负责火山引擎企业级实验平台团队,致力于打造业界最先进好用的实验平台,把A/B测试变成驱动业务增长的新基建。从0到1参与搭建了字节跳动内实验中台Libra,服务于抖音、今日头条等500多个业务线;对外发布火山引擎A/B测试DataTester等产品。
