是什么让Julia变得独一无二? 译文 精选
作者丨Erik Engheim
译者 | 卢鑫旺
审校丨诺亚
Julia作为一门编程语言,虽然发展很快,但其生态系统仍有进步空间,加上Julia把重点放在了科学计算这一相对小众的领域,因而关注度不如Python等热门语言。但是,这些事实都无法掩盖Julia在科学计算领域的巨大的优势。
多重派发(multiple dispatch)是Julia编程语言的杀手级特性,不过却几乎没有开发人员听说过它, 更鲜有人知道它是什么以及是如何工作的。这不奇怪,因为很少有语言支持多重派发,而那些能支持多重派发的语言又往往很好地隐藏了它。因此,在我大谈特谈多重派发的厉害之前,我必须先解释它到底是什么。
我先给你一个提示:它与函数的调用方式有关,让我们来后退一步来详细说明。
当程序运行并遇到函数调用时,它必须找出并跳转到要执行的代码。在一些过程编程语言(如C或者Pascal)中,这个过程很直接。每个函数都被实现为一个子例程,在内存中有唯一的位置,调用函数只需跳转到子例程的内存地址,并执行每个指令即可,直到处理器遇到返回指令。
在处理函数指针时,事情变得有些棘手。我们跳转到的子例程可以在运行时期间更改,因为代码允许更改函数指针中存储的子例程地址。我为什么要提到这些细节?因为我想表达的是,调用函数并决定执行什么代码并不总是一件小事。
思考一下在面向对象编程中要调用一个方法的复杂性。
1. warrior.attack(knight)
比如我们定义了一个叫“战士”的类Warrior,Warrior类中的成员函数 attack 并不是对应到一个有指定内存地址的子例程。当attack方法被一个warrior对象调用时,决定跳转到哪个子例程的复杂过程就会启动。我们必须确定是哪一个Warrior类的实例化对象在调用attack方法。你可以想象不同类型层次结构的“战士”类的实例化对象,比如弓箭手,枪手或者骑士。
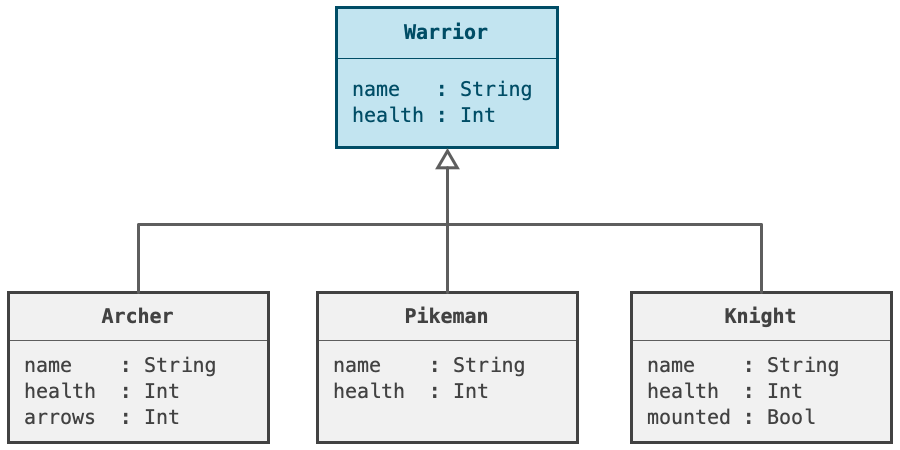
上图是具有不同属性的“战士”类的对象的类型结构
因为弓箭手的攻击方式不同于长枪手或骑士,所以不同的“战士”类的对象的攻击方法都不一样。通过一个称为单一派发的过程,我们决定调用哪个方法。从低级的角度来看,我们试图确定在执行warrior.attack(knight)这条语句时跳转到哪个子例程。
单一派发如何工作取决于我们讨论的是动态类型语言还是静态类型语言。我们看一下它在动态类型语言中的工作原理,因为我们将把这个过程和Julia语言进行比较,同时后者也是一种动态类型的语言。
想象我们有两个Warrior类的实例化 对象warrior a和 warrior b,a战士正在攻击b战士。我们的第一步是要确定战士a的类型是什么。在动态类型语言中,每个类对象都知道它的类型是什么。以Object-C语言为例,每个对象都有一个叫“isa”的属性,这个属性指向了一个类对象来描述当前对象是一个什么类型。在下图中,我们模拟了这个过程,a战士是Archer类的实例化对象,Archer类包含了每个实现方法的函数指针,为了找到正确的方法,我们对”attack”方法进行字典查找。
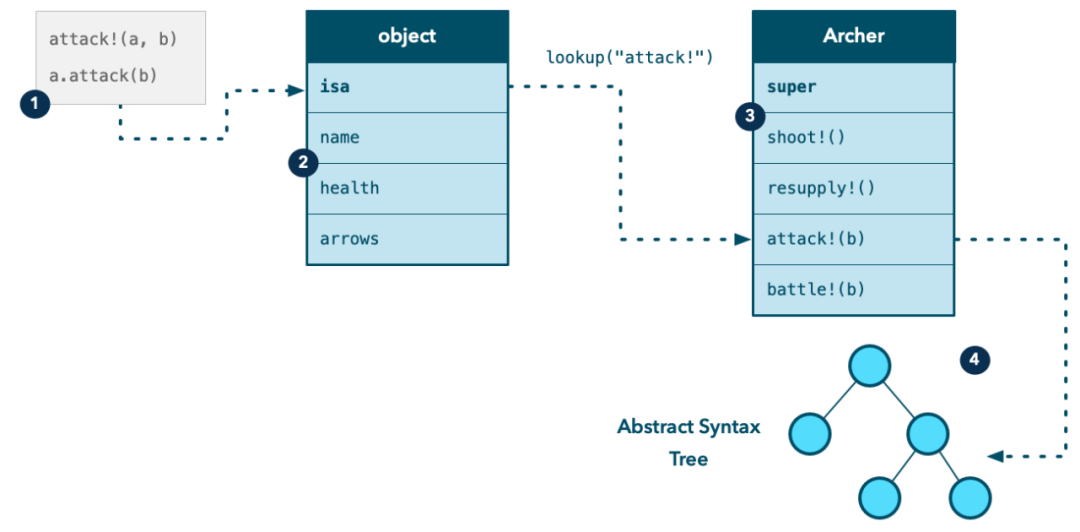
动态类型语言使用单一派发来定位要执行的代码
上图中方法名末尾的感叹号可能看起来很奇怪。不用担心,这只是一种命名约定,在Lisp语言和Julia语言中很流行,用于更改函数。它没有语义。
严格地说,在大多数动态语言中谈论函数指针是错误的。例如,在Ruby中,你实际上并没有指向任何具有机器代码的子例程,而是指向通过解析方法生成的抽象语法树(AST)。Ruby解释器解释AST以运行方法中的代码。
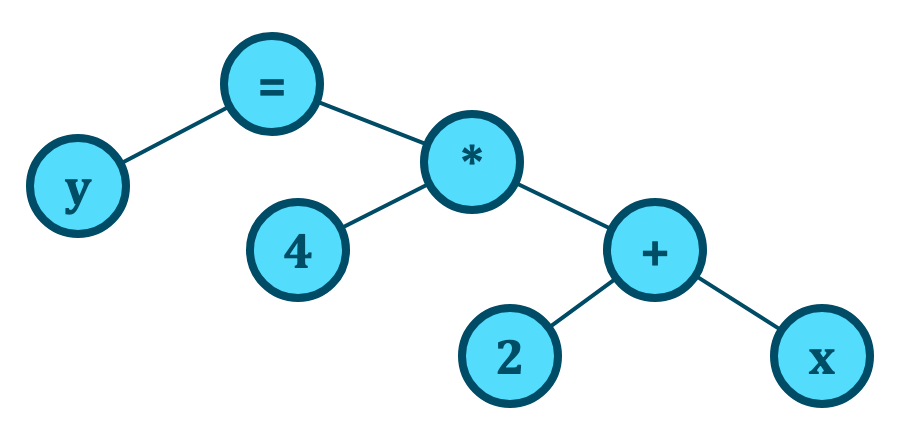
y=4*(2+x)的语法树(AST)
我们刚才讨论的称为单一派发(single dispatch),因为由我们自己根据单个对象决定调用什么方法。对象b的类型不会以任何方式影响方法查找过程。相比之下,对于多重派发,函数调用中的每个参数都在决定选择调用哪个方法中起了作用。我知道这听起来很奇怪,所以让我通过解释单一派发的问题来给你一个使用多重派发的动机。
多重派发解决了什么问题?
我们用Julia编写了一个battle!函数,它通过调用attack!函数来模拟两个战士a,b进行战斗,并根据结果将信息打印出来。下面的大部分代码是易懂的。在Julia中,我们用::来把变量名与变量类型分开。因此,在示例代码中,a::Warrior是在告诉Julia battle!函数有一个名为a的Warrior类型的参数。
1. function battle!(a::Warrior, b::Warrior)
2. attack!(a, b)
3. if a.health == 0 && b.health == 0
4. println(a.name, " and ", b.name, " destroyed each other")
5. elseif a.health == 0
6. println(b.name, " defeated ", a.name)
7. elseif b.health == 0
8. println(a.name, " defeated ", b.name)
9. else
10. println(b.name, " survived attack from ", a.name)
11. end
12. end
观察上边的代码并问自己这样一个简单的问题:类似的代码在C++或者Java中是否有效?乍一看,这似乎是可能的。这两种语言都允许你定义具有相同名称但不同参数的多个函数,你可以编写类似下面的Julia代码的代码 :
1. function attack!(a::Archer, b::Archer)
2. if a.arrows > 0
3. shoot!(a)
4. damage = 6 + rand(1:6)
5. b.health = max(b.health - damage, 0)
6. end
7. a.health, b.health
8. end
9.
10. function attack!(a::Archer, b::Knight)
11. if a.arrows > 0
12. shoot!(a)
13. damage = rand(1:6)
14. if b.mounted
15. damage += 3
16. end
17. b.health = max(b.health - damage, 0)
18. end
19. a.health, b.health
20. end
21.
22. function attack!(a::Knight, b::Knight)
23. a.health = max(a.health - rand(1:6), 0)
24. b.health = max(b.health - rand(1:6), 0)
25. a.health, b.health
26. end
代码的细节并不重要。我想让你从这个代码示例中了解到的是,我们已经定义了三个attack!函数。每个定义接受不同类型的实参。在C++和Java中,我们称这个函数为重载。在编译时,编译器将通过检查调用站点上每个输入实参的类型来选择要调用的适当函数。
关键点是:C++编译器不可能猜出battle!函数调用的是哪个attack!函数,因为它不知道实参a和b的具体类型。编译器只知道这两个实参都是Warrior类型的某个子类型。至于到底是哪个子类型只能在代码实际运行时确定。这是一个遗憾,因为函数重载只在编译时工作。
在这种情况下,多重派发可以做单一派发和函数重载都不能做的事情:它可以在运行时根据参数a和b的类型选择正确的代码。
多重派发是如何工作的?
还记得如何通过在运行时查找正确的方法来完成单一派发吗?多重派发也是关于如何选择正确的方法。你刚才看到的attack!定义实际上不是函数定义,而是方法定义。在定义attack!函数时,你可以这样写:
function attack! end
为什么没有参数呢?因为在Julia中函数没有参数,只有方法中有参数。与面向对象的语言不同,Julia中的方法是附加到函数而不是类上的。
因此,Julia中的函数调用首先通过查找被调用的函数来执行。Julia在每个函数上注册一个方法表。从上到下搜索这个表,以找到一个方法,该方法接受与函数调用站点提供的输入实参类型相匹配的实参类型。

函数被调用时Julia如何使用多重派发
来定位正确执行的代码
Julia是一种即时(JIT)编译语言,因此方法源代码需要几个步骤才能转化为可执行的机器码:
1.当Julia文件加载到内存中时,将解析每个方法的源代码并将其转换为抽象语法树(AST)。
2.每个方法的AST都存储在正确函数的正确方法表中。
3.在运行时,当一个方法被定位时,我们首先获得AST, AST被JIT编译器转化为机器码并缓存以供以后查找。
这个过程实际上比我在这里展示的要复杂得多。你可以看到,抽象语法树可以非常通用。它可以是为数字参数定义的计算。无论参数是16位无符号整数还是32位有符号整数,执行的计算都是相同的。但是,这些情况的程序集代码看起来不一样。因此,同一个AST可以产生多个机器码子例程。Julia将为方法表中的每个案例添加一个条目。因此,方法表并不局限于为其编写源代码的方法的数量。
什么让Julia的多重派发独一无二
每次调用Julia中的函数时,都会执行一个方法查找。或者更确切地说,从Julia开发人员的角度来看,情况就是这样。代码运行时就好像每次都是这样。
在支持多重派发的其他语言中,情况并非如此。只有以特殊方式标记的函数才使用多重派发。否则,将执行常规函数调用。为什么其他语言限制了多重派发的使用?因为在Julia到来之前,多重派发非常慢。
不难想象为什么多重派发会比较慢。您可能需要通过一个大表进行线性搜索O(N)的时间复杂度,而不是在常数时间内进行单个字典查找O(1)。函数可以有一个巨大的方法表。
Julia是如何规避这个问题的?Julia的设计理念是尽可能保持类型的稳定。在Python或JavaScript等语言中,情况并非如此。可以在运行时添加或删除字段和方法。单个字段的类型可以更改。在Julia身上,类型被设计得更加固定。定义复合类型时,需要固定字段及其类型的数量。
这种设计选择是如何影响多重派发的?这意味着由Julia JIT编译器完成的代码分析变得容易得多。代码的行为变得更加可预测,这使得有可能识别更多的情况,在调用函数时应该定位的方法变得完全确定和可预测。记住,如果函数调用的参数类型保持不变,那么Julia将始终查找相同的方法。如果代码分析可以确定函数的哪些参数永远不会改变,那么JIT编译器就可以用直接的函数调用替换多分派查找。如果代码很短,甚至可以内联。
因此,Julia成功地将一开始的性能劣势变成了性能优势。因此,Julia函数调用通常比面向对象语言中的单一派发调用要快得多。
一旦你达到了闪电般的速度,那么在你的编码风格发生变化的任何地方都可以使用多重派发。始终保持多重派发对Julia社区中的软件工程实践产生了深远的影响。
通过多重派发重用代码
面向对象语言的用户通过继承类和实现接口来重用代码,这允许将新代码插入到现有框架中。Julia方法是在函数级重用。不同的开发人员都可以向相同的函数添加方法。我们不扩展类,而是扩展函数。因为函数存在于较低的粒度级别,所以我们有更多的机会进行代码重用。
这种灵活性的一个简单例子是Julia标准库中定义的show函数。Julia使用它在不同的上下文中显示一个值。上下文可以是REPL(交互式命令行)、笔记本或IDE环境。匹配以下两个签名的方法可以添加到show函数中:
1. show(io::IO, mime, x)
2. show(io::IO, x)
io对象表示用于显示值x的目标。io可以是控制台窗口、文件、文本字符串、套接字或图形显示。值x可以是简单的数字、日期、文本字符串或更复杂的对象,如字典或数组。
与面向对象的编程语言不同,你可以沿着多个维度扩展显示功能。你可以为全新的IO子类型添加show方法,以在新的上下文中显示现有的值类型。假设我们创建了特殊类型来表示温度单位摄氏度、华氏度和开尔文。可以添加方法来显示,以便用正确的单位显示代表温度的数字。
注意,在Julia中可以用等号定义一行函数。
1. show(io::IO, t::Celsius) = print(io, t.value, "°C")
2. show(io::IO, t::Fahrenheit) = print(io, t.value, "°F")
3. show(io::IO, t::Kelvin) = print(io, t.value, "K")
为了理解这个扩展机制为何如此强大,请允许我指出一些你试图使用面向对象编程复制这个扩展机制时会遇到的问题。你设计一个系统,其中每个对象都必须实现一个显示方法来显示,但这种选择会导致几个问题:
- 所有的类都必须继承一个带有show方法的基类。
- 每个对象将在每个IO对象类型上获得相同的表示。
也就是说:许多面向对象的系统最终都有过于复杂的基类。原因是你想为每个对象支持太多的功能:
- 在不同的上下文中可视化一个对象,比如在调试器中
- 用于打印或存储到文件中的文本表示
- 为了允许使用集合中的对象使用哈希函数
例如,你可以在Java和Objective-C中找到这种模式。这种做法是僵化的。如果基类设计错误,将对所有相关代码产生严重后果。
更不用说,如果语言设计者忘记添加show方法,那么就没有简单的方法来改进它。只有对标准库进行更新才能修复它。作为第三方开发人员,你不能改造解决方案。相反,如果Julia标准库没有定义show函数,你可以很容易地自己定义它,并发布一个库来实现公共对象的可视化,并且你可以将其分发给其他人。
u和v是向量,而A到F是点。向量表示点之间的差。u是点F和E的差。
让我们多谈谈I/O系统的问题。假设你已经创建了一个名为Vector2D的2D向量类型。在控制台中使用时,你可能希望将向量显示为[4,8],而如果I/O对象表示图形显示,则希望显示箭头。这两种选择在Julia中都是可能的,因为你可以为io参数是一个图形显示而x参数是一个2D向量的情况编写专门的方法。相比之下,面向对象语言只能根据io或x的类型选择要执行的方法,而不能同时根据两者。记住,对于单一派发,在运行时调用的方法是基于单个参数的类型选择的,而不是基于多个参数的类型。
当然,你可以抛出一个switch-case语句来处理不同的类型,但这是不可扩展的。每次添加新类型时,都必须修改switch-case语句。这将阻止你将代码作为可重用库分发。库用户不应该修改第三方库的源代码来扩展它。
多重派发的效用
模拟不同类型的战士之间的战斗或者编写I/O系统当然只是几种情况,这些情况可以简化编码。当我在电子游戏中编写碰撞检测代码时,它第一次发现我需要这样的东西。不同的游戏对象会用不同的几何形状来表示。问题是计算两个圆,两个正方形或圆和正方形的交点是完全不同的。你不能只看一个参数就决定要使用的算法,你需要两个参数。如果没有多重派发,你的解决方案将变得混乱。
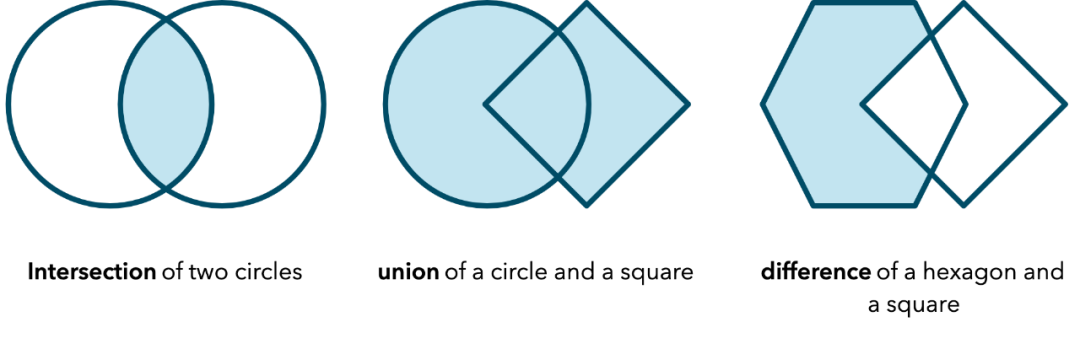
多重派发天然适合来组合不同的几何对象
多重派发也很适合任何数值工作。对数字的运算通常是二进制的。只看第一个数的类型来决定如何组合两个数是没有什么意义的。
简而言之,多重派发就像一把瑞士军刀:它帮助程序运行得更快,允许你优雅地解决许多问题,并提供了代码重用的高级方法。这听起来可能有点夸张,但我真的相信,多重派发将定义未来的编程范式。
译者简介
卢鑫旺,51CTO社区编辑,编程语言爱好者,对数据库,架构,云原生有浓厚兴趣。
原文链接:?https://itnext.io/what-makes-julia-unique-f3ad184fa4a2??
