复旦自然语言处理科研团队14篇长文被EMNLP 2022录用
EMNLP 2022 (The 2022 Conference on Empirical Methods in Natural Language Processing)是自然语言处理领域的顶级国际会议,由国际语言学会SIGDAT小组在世界范围内每年召开一次。在本次会议中,复旦大学自然语言处理实验室FudanNLP共计14篇长文被录用,其中包括9篇主会文章和5篇Findings文章。2022年冬季,EMNLP 2022将以混合形式在阿联酋阿布扎比(Abu Dhabi)举行,所有参与者都可以在会场现场或虚拟加入。
9篇主会文章简介
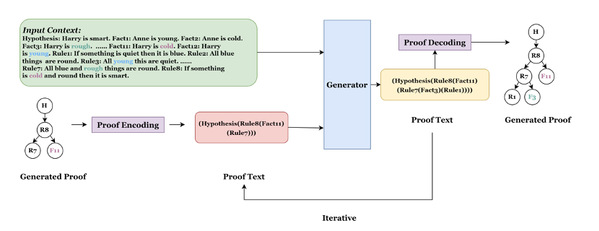
1. ProofInfer: Generating Proof via Iterative Hierarchical Inference
作者:费子楚,张奇,周鑫,桂韬,黄萱菁
文章针对证明树生成任务提出一个通过迭代层次推理生成证明树的模型并采用分治算法,将证明树递归地编码为纯文本,同时预测层中的所有节点且不会丢失结构信息。
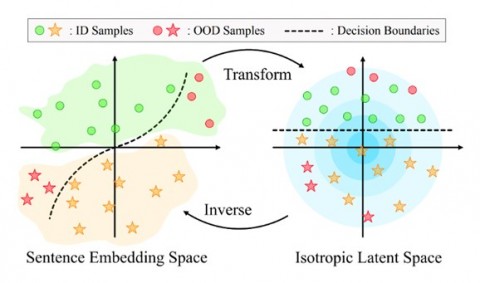
2、Kernel-Whitening: Overcome Dataset Bias with Isotropic Sentence Embedding
作者:高颂杨,窦士涵,张奇,黄萱菁
文章针对数据集偏差问题引入两种去偏差方法。一是表示标准化,消除编码句子的特征之间的相关性,另一个是 ”核白化”方法来实现对非线性虚假相关性更彻底的去偏。实验表明,该方法在时间和效果上都有不错的提升。
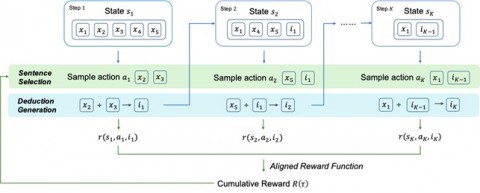
3、ReLET: A Reinforcement Learning Based Approach for Explainable QA with Entailment Trees
作者:刘腾霄,郭琦鹏,胡祥坤,张岳,邱锡鹏,张峥
文章首次将强化学习方法引入蕴涵树生成任务,提出一种基于强化学习的蕴涵树生成框架,利用整个树的累积信号进行训练。它使用句子选择和结论生成两个模块迭代地执行单步推理,使用与评估方法一致的奖励函数进行训练信号的累积。
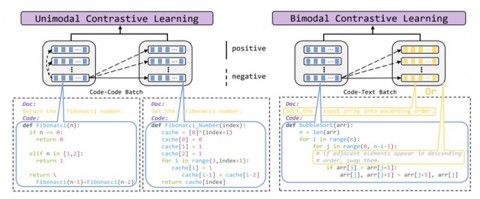
4、CodeRetriever: A Large Scale Contrastive Pre-Training Method for Code Search
作者:李孝男,宫叶云,谌叶龙,邱锡鹏,张航,要博伦,齐炜祯,姜大昕,陈伟柱,段楠
文章针对代码文本对的构建任务提出了单模态和双模态的对比学习策略。对于单模态的对比学习,以无监督的方式根据代码中的自然语言信息,来构建具有相似功能的代码对。对于双模态的对比学习,则利用代码的文档和存在于代码中的零散注释来构建代码文本对。
5、BERTScore is Unfair: On Social Bias in Language Model-Based Metrics for Text Generation
作者:孙天祥*,何俊亮*,邱锡鹏,黄萱菁
文章研究了生成文本质量的自动化评测指标存在的公平性隐患。这种评测的不公平性会在模型选择的过程中鼓励富有偏见的生成系统,进一步加深模型及其生成数据的社会偏见。
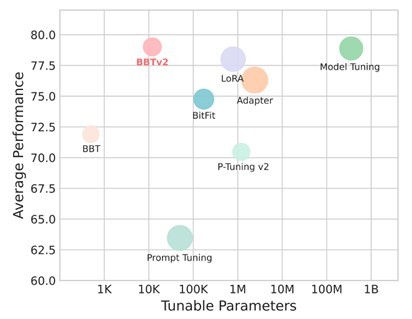
6、BBTv2: Towards a Gradient-Free Future with Large Language Models
作者:孙天祥,贺正夫,钱鸿,周云华,黄萱菁,邱锡鹏
文章在Black-Box Tuning的基础上提出了BBTv2,使用深层prompt代替原有的输入层prompt,并提出一种基于分治的无梯度优化方法对其进行交替优化,在多个少样本学习任务上仅优化千分之三的参数取得了和全参数微调相仿的性能。
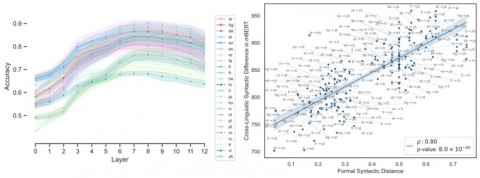
7、Cross-Linguistic Syntactic Difference in Multilingual BERT: How Good is It and How Does It Affect Transfer?
作者:徐凝雨,桂韬,马若恬,张奇,叶婧婷,张梦翰,黄萱菁
文章研究了多语言 BERT的迁移过程,证明了不同语言分布之间的距离与语言间的形式句法差异高度一致。多语言 BERT学习得到的语言间句法结构的差异对零样本迁移效果有着决定性的影响,并可以利用语言间的形态句法属性差异进行预测。
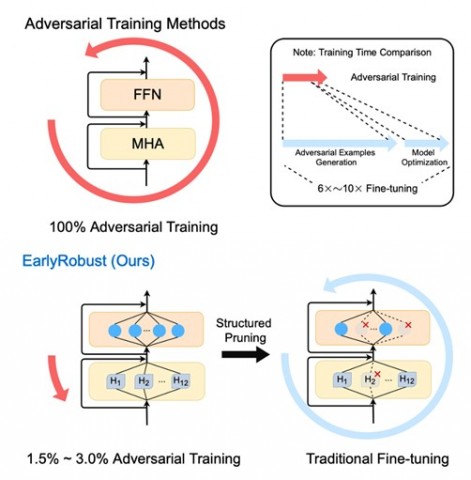
8、Efficient Adversarial Training with Robust Early-Bird Tickets
作者:奚志恒*,郑锐*,桂韬,张奇,黄萱菁
文章提取出结构化稀疏的鲁棒早鸟彩票(即子网络)并设置一个彩票收敛指标来实现一种高效的对抗训练方法,从而提升预训练语言模型鲁棒性。
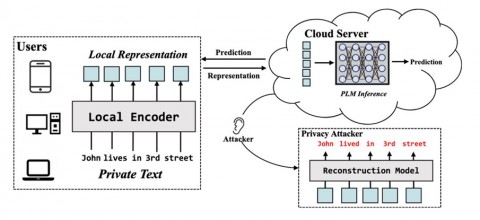
9、TextFusion: Privacy-Preserving Pre-trained Model Inference via Token Fusion
作者:周鑫,陆劲竹,桂韬,马若恬,费子楚,王宇然,丁勇, 张轶博,张奇,黄萱菁
文章提出了一种保存端云协同推理阶段隐私的新方法。它包含一个融合预测器来动态地融合词表示,将多个可能含有隐私的词表示融合为一个难以识别的词表示。此外,文章采用了一种误导性的训练方案来使这些表示进一步被干扰。
5篇Findings文章简介
1、Is MultiWOZ a Solved Task? An Interactive TOD Evaluation Framework with User Simulator
作者:程沁源*,李林阳*,权国风,高峰,牟晓峰,邱锡鹏
文章提出了一个用于TOD的交互式评测框架:首先基于预训练模型构建了一个面向用户目标的用户模拟器,然后使用用户模拟器与对话系统交互以生成对话,并在交互式评测中引入了句子级和会话级分数来衡量对话的流畅度和连贯性。

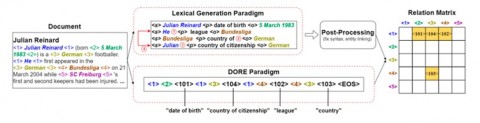
2、DORE: Document Ordered Relation Extraction based on Generative Framework
作者:郭琦鹏*,杨雨晴*,颜航,邱锡鹏,张铮
文章提出了从关系矩阵中生成一个符号化的有序序列的范式,使模型更容易学习。此外,该文章设计了一种平行行生成的方法来处理过长的目标序列,引入了几种负采样策略来利用更平衡的信号提高模型性能。
3、Soft-Labeled Contrastive Pre-Training for Function-Level Code Representation
作者:李孝男*,郭达雅,宫叶云,林云,谌叶龙,邱锡鹏,姜大昕,陈伟柱,段楠
文章提出一种基于软标签训练方式的代码对比预训练框架SCodeR来学习更好的函数级代码表示。此外,该研究团队还提出了一种基于代码上下文和抽象语法树的正样例构造方法ASST,来帮助模型能够更好地捕获代码中的语义特征。

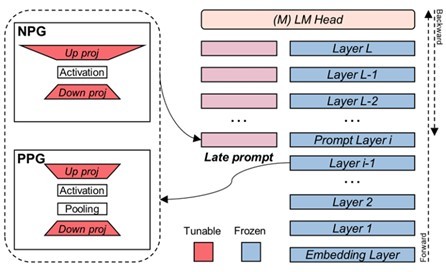
4、Late Prompt Tuning: A Late Prompt Could Be Better Than Many Prompts
作者:刘向阳,孙天祥,黄萱菁,邱锡鹏
文章探索了Prompt Tuning性能较弱的原因,并基于此发现提出了一个更好更高效地驱动预训练模型的方法Late Prompt Tuning(LPT),能够取得很有竞争力的结果,同时具有更快的训练速度和更低的内存成本。
5、Weight Perturbation as Defense against Textual Adversaries
作者:徐健涵,李林阳,张稷平,郑骁庆,Kai-Wei Chang,Cho-Jui Hsieh,黄萱菁
文章探索了通过在参数空间而不是输入特征空间进行扰动来提高NLP模型对抗鲁棒性的可行性。当权重扰动与输入嵌入空间中的扰动相结合时,可以显著提高NLP模型的鲁棒性,从而在不同数据集的原始样本和对抗样本中获得最高预测准确率。
版权声明:除特殊说明外,本站所有文章均为 字节点击 原创内容,采用 BY-NC-SA 知识共享协议。原文链接:https://byteclicks.com/42972.html 转载时请以链接形式标明本文地址。转载本站内容不得用于任何商业目的。本站转载内容版权归原作者所有,文章内容仅代表作者独立观点,不代表字节点击立场。报道中出现的商标、图像版权及专利和其他版权所有的信息属于其合法持有人,只供传递信息之用,非商务用途。如有侵权,请联系 gavin@byteclicks.com。我们将协调给予处理。
赞
