视网膜图像分类的深度集成学习算法 译文 精选
译者?| 朱先忠
审校 | 孙淑娟

图1:原作者自己设计的Iluminado项目的封面
2019年世界卫生组织估计,全球共有约22亿视力障碍者,其中至少有10亿人本可以预防或仍在治疗。就眼部护理领域而言,全世界面临许多挑战,包括预防、治疗和康复服务的覆盖面和质量不平等。缺乏训练有素的眼部护理人员,眼部护理服务与主要卫生系统的整合也很差。我的目标是激发人们的行动来共同应对这些挑战。本文中展示的项目是我目前正在进行的数据科学顶峰项目Iluminado的一部分。
Capstone项目的设计目标
我创建本文项目的目的是想训练一个深度学习集成模型,最终实现该模型对于低收入家庭来说非常容易获得,并且可以以低成本执行初始疾病风险诊断。通过使用我的模型程序,眼科医生就可以根据视网膜眼底摄影确定是否需要立即进行干预。
项目数据集来源
OphthAI提供了一个名为视网膜眼底多疾病图像数据集(Retinal Fundus Multi-Disease Image Dataset,简称“RFMiD”)的公共可用图像数据集,该数据集包含3200张眼底图像,这些图像由三台不同的眼底相机拍摄,并由两名资深视网膜专家根据已裁决的共识进行注释。
这些图像是从2009-2010年期间进行的数千次检查中提取的,既选择了一些高质量的图像也包含不少低质量的图像,从而使数据集更具挑战性。
数据集共分为三个部分,包括训练集(60%或1920张图像)、评估集(20%或640张图像)和测试集(20%和640张)。平均而言,训练集、评估集和测试集中的患有疾病的占比分别为60±7%、20±7%和20±5%。该数据集的基本目的是解决日常临床实践中出现的各种眼部疾病,共确定了45类疾病/病理。这些标签可以分别在三个CSV文件中找到,它们是RFMiD_Training_Labels.CSV、RFMiD_Validation_Labels.SSV和RFMiD_Testing_Labels.CSV。
图像来源
下面这张图是用一种被称为眼底照相机的工具拍摄的。眼底照相机是一种专门的低倍显微镜,连接在一台闪光照相机上,用来拍摄眼底,即眼睛后部的视网膜层。
现在,大多数眼底照相机都是手持式的,因此患者只需直视镜头。其中,明亮的闪光部分表示已拍摄眼底图。
手持摄像机是有其优点的,因为它们可以被携带到不同的位置,并且可以容纳有特殊需求的患者,例如轮椅使用者。此外,任何接受过所需培训的员工都可以操作摄像头,从而能够使服务水平低下的的糖尿病患者可以快速、安全、高效地进行年度检查。
眼底视网膜成像系统拍照情况:
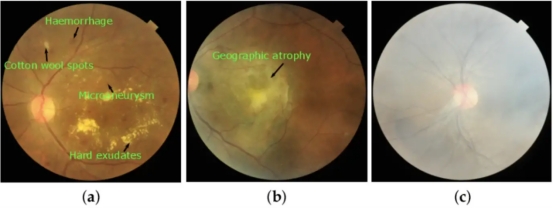
图2:基于各自视觉特征拍摄的图像:(a)糖尿病视网膜病变(DR)、(b)老年性黄斑变性(ARMD)和(c)中度霾(MH)。
最终诊断在哪里进行?
最初的筛查过程可以通过深度学习来辅助,但最终诊断由眼科医生使用裂隙灯检查进行。
这一过程也被称为生物显微镜诊断,它涉及对活细胞的检查。医生可以进行显微镜检查,以确定病人的眼睛是否出现任何异常。
图3:裂隙灯检查图示
深度学习在视网膜图像分类中的应用
与传统的机器学习算法不同,深度卷积神经网络(CNN)可以使用多层模型的办法实现从原始数据中自动提取和分类特征。
最近,学术界发表了大量文章,都是有关使用卷积神经网络(CNN)来识别各种眼部疾病的,如糖尿病视网膜病变和结果异常(AUROC>0.9)的青光眼等。
数据指标
AUROC分数将ROC曲线汇总为一个数字,该数字描述了模型在同时处理多个阈值时的性能。值得注意的是,AUROC分数为1代表是一个完美的分数,而AUROC得分为0.5对应于随机猜测。
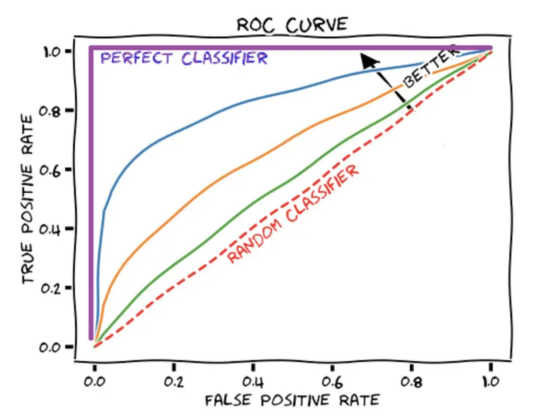
图4:ROC曲线示意图展示
所用方法——交叉熵损失函数
交叉熵通常在机器学习中用作损失函数。交叉熵是信息理论领域的一种度量,它建立在熵定义的基础上,通常用于计算两个概率分布之间的差异,而交叉熵可以被认为是计算两个分布之间的总熵。
交叉熵也与逻辑损失有关,称为对数损失。尽管这两种度量方法来自不同的来源,但当用作分类模型的损失函数时,这两种办法计算的数量相同,可以互换使用。
(有关具体详情,请参考:https://machinelearningmastery.com/logistic-regression-with-maximum-likelihood-estimation/)
什么是交叉熵?
交叉熵是给定随机变量或事件集的两个概率分布之间差异的度量。您可能还记得,信息量化了编码和传输事件所需的位数。低概率事件往往包含更多的信息,而高概率事件则包含较少的信息。
在信息论中,我们喜欢描述事件的“惊讶”。事件发生的可能性越小,就越令人惊讶,这意味着它包含了更多的信息。
- 低概率事件(令人惊讶):更多信息。
- 高概率事件(不足为奇):信息较少。
在给定事件P(x)的概率的情况下,就可以为事件x计算信息h(x),如下所示:
h(x) = -log(P(x))
图4:完美的插图(图片来源:Vlastimil Martinek)
熵是从概率分布中传输随机选择的事件所需的比特数。偏态分布具有较低的熵,而事件具有相等概率的分布一般具有较大的熵。
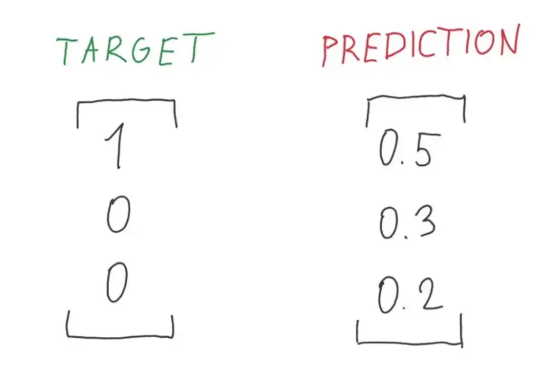
图5:目标与预测概率之比的完美说明(图片来源:Vlastimil Martinek)
偏态概率分布具有较少的“意外”,反过来也具有较低的熵,因为可能的事件占主导地位。相对来说,平衡分布更令人惊讶,而且熵更高,因为事件发生的可能性相同。
- 偏态概率分布(不足为奇):低熵。
- 平衡概率分布(令人惊讶):高熵。
熵H(x)可以针对具有x个离散状态中的一组x的随机变量及其概率P(x)计算,如下图所示:
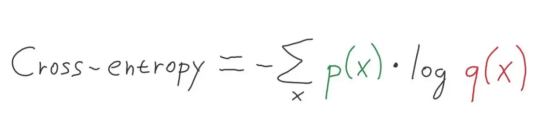
图6:多级交叉熵公式(图片来源:Vlastimil Martinek)
多类别分类——我们使用多分类交叉熵——属于交叉熵的一种具体应用情形,其中的目标采用的是单热编码向量方案。(有兴趣的读者可参考Vlastimil Martinek的文章)

图7:熊猫和猫损失计算的完美分解图(图片来源:Vlastimil Martinek)
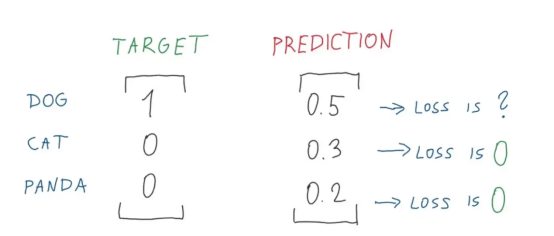
图8:损失值的完美分解图1(图片来源:Vlastimil Martinek)
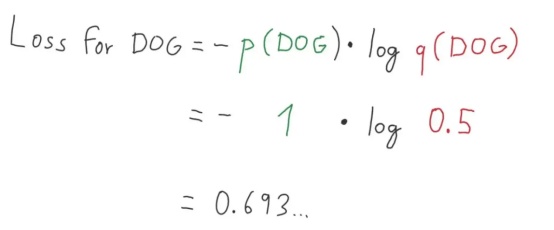
图9:损失值的完美分解图2(图片来源:Vlastimil Martinek)
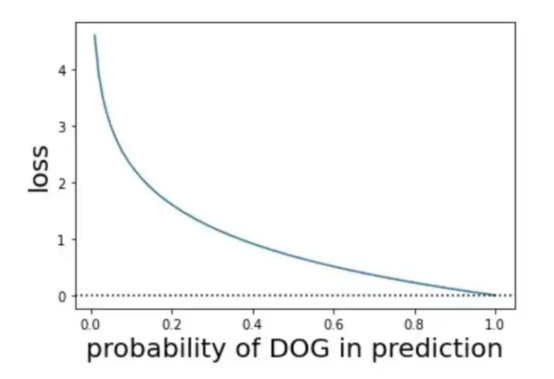
图9:关于概率和损失的可视化展示(图片来源:Vlastimil Martinek)
二元交叉熵怎么样?

图10:分类交叉熵公式图解(图片来源:Vlastimil Martinek)
在我们的项目中选择使用了二元分类——二元交叉熵方案,即目标为0或1的交叉熵方案。如果我们将目标分别转换为[0,1]或[1,0]的热编码向量方式并进行预测,那么我们就可以使用交叉熵公式来进行计算。

图11:二元交叉熵计算公式图解(图片来源:Vlastimil Martinek)
使用非对称损失算法处理不平衡数据
在一个典型的多标签模型环境中,数据集的特征可能存在不成比例数量的正标签和负标签的情况。此时,数据集倾向于负标签的这种趋势对于优化过程具有主导性影响,并最终导致正标签的梯度强调不足,从而降低预测结果的准确性。
这也正是我当前选用的数据集所面临的情况。
本文项目中采用了BenBaruch等人开发的非对称损失算法(参考图12),这是一种解决多标签分类的方法,不过其中的类别也存在严重不平衡分布情形。
我想到的办法是:通过不对称地修改交叉熵中的正负分量,从而减少负标签部分的权重,最终实现突出上述处理起来较为困难的正标签部分的权重。
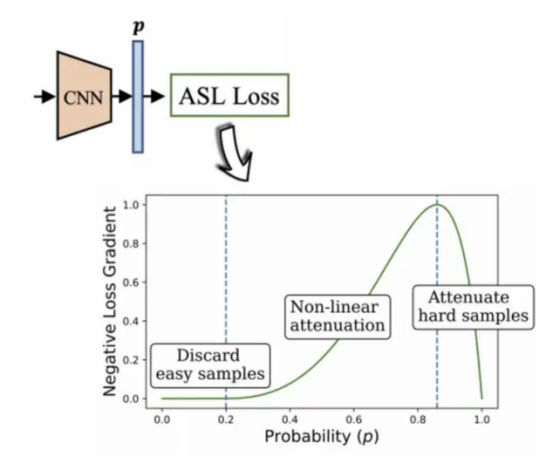
图12:非对称多标签分类算法(2020,作者:Ben-Baruch等)
待测试的体系架构
总体归纳一下,本文项目使用了如图所示的体系架构:
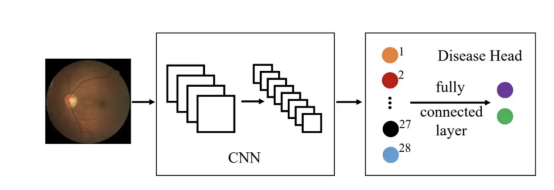
图13(图片来源:Sixu)
上述架构所采用的关键算法主要包括:
- DenseNet-121
- InceptionV3
- Xception
- MobileNetV2
- VGG16
另外,上述有关算法有关内容一定会在我完成本文Capstone项目后加以更新!有兴趣的读者敬请期待!
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:??Deep Ensemble Learning for Retinal Image Classification (CNN)??,作者:Cathy Kam
