使用迁移学习技术训练定制深度学习模型 译文
?译者 | 朱先忠
审校 | 孙淑娟
迁移学习是机器学习的一种类型,它是一种应用于已经训练或预训练的神经网络的方法,而且这些预训练的神经元网络是使用数百万个数据点训练出来的。
该技术目前最著名的用法是用来训练深度神经网络,因为这种方法在使用较少的数据训练深度神经网络时表现出良好的性能。实际上,这种技术在数据科学领域也是很有用的,因为大多数真实世界的数据通常没有数百万个数据点来训练出稳固的深度学习模型。
目前,已经存在许多使用数百万个数据点训练出来的模型,并且这些模型可以用于以最大精度来训练复杂的深度学习神经网络。
在本教程中,您将学习到如何使用迁移学习技术来训练一个深度神经网络的完整过程。
使用Keras程序实现迁移学习
在构建或训练深度神经网络之前,您必须搞清楚有哪些选择方案可用于迁移学习,以及必须使用哪个方案来为项目训练复杂的深度神经网络。
Keras应用程序是一种高级的深度学习模型,它提供了可用于预测、特征提取和微调的预训练权重。Keras库中内置提供了许多现成可用的模型,其中一些流行的模型包括:
- Xception
- VGG16 and VGG19
- ResNet Series
- MobileNet
【补充】Keras应用程序提供了一组深度学习模型,它们可与预先训练的权重一起使用。有关这些模型的更具体的内容,请参考??Keras官网内容??。
在本文中,您将学习??MobileNet模型??在迁移学习中的应用。
训练一个深度学习模型
在本节中,您将学习如何在短短的几个步骤内为图像识别构建一个自定义深度学习模型,而无需编写任何一系列卷积神经网络(CNN),您只需对预训练的模型加以微调,即可使得您的模型在训练数据集上进行训练。
在本文中,我们构建的深度学习模型将能够识别手势语言数字的图像。接下来,让我们开始着手构建这个自定义深度学习模型。
获取数据集
要开始构建一个深度学习模型的过程,您首先需要准备好数据,您可以通过访问一个名为Kaggle的网站,从数百万个数据集中轻松选择合适的数据集。当然,也存在不少其他网站为构建深度学习或机器学习模型提供可用的数据集。
但本文将使用的数据集取自Kaggle网站提供的??美国手语数字数据集??。
数据预处理
在下载数据集并将其保存到本地存储之后,现在是时候对数据集执行一些预处理了,比如准备数据、将数据拆分为train目录、valid目录和test目录、定义它们的路径以及为训练目的创建批处理,等等。
准备数据
下载数据集时,它包含从0到9数据的目录,其中有三个子文件夹分别对应输入图像、输出图像以及一个名称为CSV的文件夹。
接着,从每个目录中删除输出图像和CSV文件夹,将输入图像文件夹下的内容移动到主目录下,然后删除输入图像文件夹。
数据集的每个主目录现在都拥有500幅图像,您可以选择保留所有图像。但出于演示目的,本文中每个目录中只使用其中的200幅图像。
最终,数据集的结构将如下图所示:
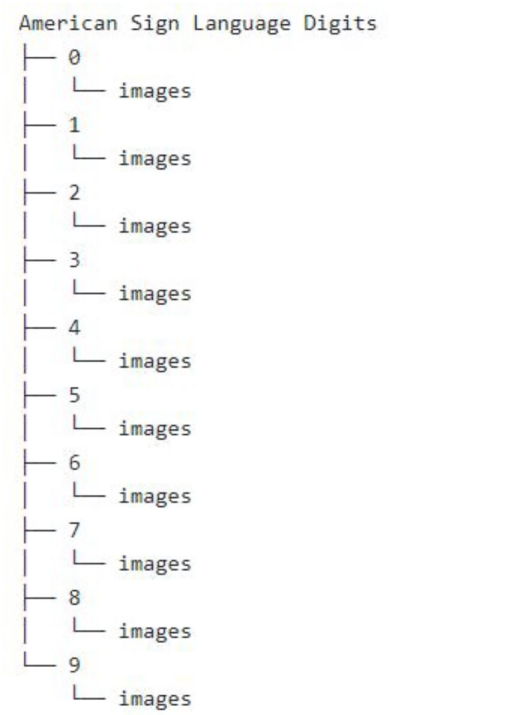
数据集的文件夹结构
分割数据集
现在,让我们从将数据集拆分为train、valid和test三个子目录开始。
- train目录将包含训练数据,这些数据将作为我们输入模型的输入数据,用于学习模式和不规则性。
- valid目录将包含将被输入到模型中的验证数据,并且将是模型所看到的第一个未看到的数据,这将有助于获得最大的准确性。
- test目录将包含用于测试模型的测试数据。
首先,我们来导入将在代码中进一步使用的库。
# 导入需要的库
import os
import shutil
import random
下面是生成所需目录并将数据移动到特定目录的代码。
#创建三个子目录:train、valid和test,并把数据组织到其下
os.chdir('D:\SACHIN\Jupyter\Hand Sign Language\Hand_Sign_Language_DL_Project\American-Sign-Language-Digits-Dataset')
#如果目录不存在则创建相应的子目录
if os.path.isdir('train/0/') is False:
os.mkdir('train')
os.mkdir('valid')
os.mkdir('test')
for i in range(0, 10):
#把0-9子目录移动到train子目录下
shutil.move(f'{i}', 'train')
os.mkdir(f'valid/{i}')
os.mkdir(f'test/{i}')
#从valid子目录下取90个样本图像
valid_samples = random.sample(os.listdir(f'train/{i}'), 90)
for j in valid_samples:
#把样本图像从子目录train移动到valid子目录
shutil.move(f'train/{i}/{j}', f'valid/{i}')
#从test子目录下取90个样本图像
test_samples = random.sample(os.listdir(f'train/{i}'), 10)
for k in test_samples:
#把样本图像从子目录train移动到test子目录
shutil.move(f'train/{i}/{k}', f'test/{i}')
os.chdir('../..')
在上面的代码中,我们首先更改了数据集在本地存储中对应的目录,然后检查是否已经存在train/0目录;如果没有,我们将分别创建train、valid和test子目录。
然后,我们创建子目录0到9,并将所有数据移动到train目录中,同时创建了valid和test这两个子目录下各自的子目录0至9。
然后,我们在train目录内的子目录0到9上进行迭代,并从每个子目录中随机获取90个图像数据,并将它们移动到valid目录内的相应子目录。
对于测试目录test也是如此。
【补充】在Python中执行高级文件操作的shutil模块(手动将文件或文件夹从一个目录复制或移动到另一个目录可能是一件非常痛苦的事情。有关详细技巧,请参考文章https://medium.com/@geekpython/perform-high-level-file-operations-in-python-shutil-module-dfd71b149d32)。
定义到各目录的路径
创建所需的目录后,现在需要定义train、valid和test这三个子目录的路径。
#为三个子目录train、valid和test分别指定路径
train_path = 'D:/SACHIN/Jupyter/Hand Sign Language/Hand_Sign_Language_DL_Project/American-Sign-Language-Digits-Dataset/train'
valid_path = 'D:/SACHIN/Jupyter/Hand Sign Language/Hand_Sign_Language_DL_Project/American-Sign-Language-Digits-Dataset/valid'
test_path = 'D:/SACHIN/Jupyter/Hand Sign Language/Hand_Sign_Language_DL_Project/American-Sign-Language-Digits-Dataset/test'
进行预处理
预训练的深度学习模型需要一些预处理的数据,这些数据非常适合训练。因此,数据需要采用预训练模型所需的格式。
在应用任何预处理之前,让我们导入TensorFlow及其实用程序,这些实用程序将在代码中进一步使用。
#导入TensorFlow及其实用程序
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import categorical_crossentropy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
from tensorflow.keras.models import load_model
#创建训练、校验和测试图像的批次,并使用Mobilenet的预处理模型进行预处理
train_batches = ImageDataGenerator(preprocessing_function=tf.keras.applications.mobilenet.preprocess_input).flow_from_directory(
directory=train_path, target_size=(224,224), batch_size=10, shuffle=True)
valid_batches = ImageDataGenerator(preprocessing_function=tf.keras.applications.mobilenet.preprocess_input).flow_from_directory(
directory=valid_path, target_size=(224,224), batch_size=10, shuffle=True)
test_batches = ImageDataGenerator(preprocessing_function=tf.keras.applications.mobilenet.preprocess_input).flow_from_directory(
directory=test_path, target_size=(224,224), batch_size=10, shuffle=False)
我们使用了ImageDatagenerator,它采用了一个参数preprocessing_function,在该函数参数中,我们对MobileNet模型提供的图像进行了预处理。
接下来,调用flow_from_directory函数,其中我们提供了要训练图像的目录和维度的路径,因为MobileNet模型是为具有224x224维度的图像训练使用的。
再接下来,定义了批量大小——定义一次迭代中可以处理多少图像,然后我们对图像处理顺序进行随机打乱。在此,我们没有针对测试数据的图像进行随机乱序,因为测试数据不会用于训练。
在Jupyter笔记本或Google Colab中运行上述代码片断后,您将看到如下结果。

上述代码的输出结果
ImageDataGenerator的一般应用场景是用于增广数据,以下是使用Keras框架中ImageDataGenerator执行数据增广的??指南??。
创建模型
在将训练和验证数据拟合到模型中之前,深度学习模型MobileNet需要通过添加输出层、删除不必要的层以及使某些层不可训练,从而获得更好的准确性来进行微调。
以下代码将从Keras下载MobileNet模型并将其存储在mobile变量中。您需要在第一次运行以下代码片断时连接到因特网。
mobile = tf.keras.applications.mobilenet.MobileNet()
如果您运行以下代码,那么您将看到模型的摘要信息,在其中你可以看到一系列神经网络层的输出信息。
mobile.summary()
现在,我们将在模型中添加以10为单位的全连接输出层(也称“稠密层”)——因为从0到9将有10个输出。此外,我们从MobileNet模型中删除了最后六个层。
# 删除最后6层并添加一个输出层
x = mobile.layers[-6].output
output = Dense(units=10, activation='softmax')(x)
然后,我们将所有输入和输出层添加到模型中。
model = Model(inputs=mobile.input, outputs=output)
现在,我们将最后23层设置成不可训练的——其实这是一个相对随意的数字。一般来说,这一具体数字是通过多次试验和错误获得的。该代码的唯一目的是通过使某些层不可训练来提高精度。
#我们不会训练最后23层——这里的23是一个相对随意的数字
for layer in mobile.layers[:-23]:
layer.trainable=False
如果您看到了微调模型的摘要输出,那么您将注意到与前面看到的原始摘要相比,不可训练参数和层的数量存在一些差异。
model.summary()
接下来,我们要编译名为Adam的优化器,选择学习率为0.0001,以及损失函数,还有衡量模型的准确性的度量参数。
model.compile(optimizer=Adam(learning_rate=0.0001), loss='categorical_crossentropy', metrics=['accuracy'])
现在是准备好模型并根据训练和验证数据来开始训练的时候了。在下面的代码中,我们提供了训练和验证数据以及训练的总体轮回数。详细信息只是为了显示准确性进度,在这里您可以指定一个数字参数值为0、1或者2。
# 运行共10个轮回(epochs)
model.fit(x=train_batches, validation_data=valid_batches, epochs=10, verbose=2)
如果您运行上面的代码片断,那么您将看到训练数据丢失和准确性的轮回的每一步的输出内容。对于验证数据,您也能够看到这样的输出结果。

显示有精度值的训练轮回步数
存储模型
该模型现在已准备就绪,准确度得分为99%。现在请记住一件事:这个模型可能存在过度拟合,因此有可能对于给定数据集图像以外的图像表现不佳。
#检查模型是否存在;否则,保存模型
if os.path.isfile("D:/SACHIN/Models/Hand-Sign-Digit-Language/digit_model.h5") is False:
model.save("D:/SACHIN/Models/Hand-Sign-Digit-Language/digit_model.h5")
上面的代码将检查是否已经有模型的副本。如果没有,则通过调用save函数在指定的路径中保存模型。
测试模型
至此,模型已经经过训练,可以用于识别图像了。本节将介绍加载模型和编写准备图像、预测结果以及显示和打印预测结果的函数。
在编写任何代码之前,需要导入一些将在代码中进一步使用的必要的库。
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
加载定制的模型
对图像的预测将使用上面使用迁移学习技术创建的模型进行。因此,我们首先需要加载该模型,以供后面使用。
my_model = load_model("D:/SACHIN/Models/Hand-Sign-Digit-Language/digit_model.h5")在此,我们通过使用load_model函数,实现从指定路径加载模型,并将其存储在my_model变量中,以便在后面代码中进一步使用。
准备输入图像
在向模型提供任何用于预测或识别的图像之前,我们需要提供模型所需的格式。
def preprocess_img(img_path):
open_img = image.load_img(img_path, target_size=(224, 224))
img_arr = image.img_to_array(open_img)/255.0
img_reshape = img_arr.reshape(1, 224,224,3)
return img_reshape
首先,我们要定义一个获取图像路径的函数preprocess_img,然后使用image实用程序中的load_img函数加载该图像,并将目标大小设置为224x224。然后将该图像转换成一个数组,并将该数组除以255.0,这样就将图像的像素值转换为0和1,然后将图像数组重新调整为形状(224,224,3),最后返回转换形状后的图像。
编写预测函数
def predict_result(predict):
pred = my_model.predict(predict)
return np.argmax(pred[0], axis=-1)
这里,我们定义了一个函数predict_result,它接受predict参数,此参数基本上是一个预处理的图像。然后,我们调用模型的predict函数来预测结果。最后,从预测结果中返回最大值。
显示与预测图像
首先,我们将创建一个函数,它负责获取图像的路径,然后显示图像和预测结果。
#显示和预测图像的函数
def display_and_predict(img_path_input):
display_img = Image.open(img_path_input)
plt.imshow(display_img)
plt.show()
img = preprocess_img(img_path_input)
pred = predict_result(img)
print("Prediction: ", pred)
上面这个函数display_and_predict首先获取图像的路径并使用PIL库中的Image.open函数打开该图像,然后使用matplotlib库来显示图像,然后将图像传递给preprep_img函数以便输出预测结果,最后使用predict_result函数获得结果并最终打印。
img_input = input("Enter the path of an image: ")
display_and_predict(img_input)如果您运行上面的程序片断并输入数据集中图像的路径,那么您将得到所期望的输出。

预测结果示意图
请注意,到目前为止该模型是使用迁移学习技术成功创建的,而无需编写任何一系列神经网络层相关代码。
现在,这个模型可以用于开发能够进行图像识别的Web应用程序了。文章的最后所附链接处提供了如何将该模型应用到Flask应用程序中的完整实现源码。
结论
本文中我们介绍了使用预先训练的模型或迁移学习技术来制作一个定制的深度学习模型的过程。
到目前为止,您已经了解了创建一个完整的深度学习模型所涉及的每一步。归纳起来看,所使用的总体步骤包括:
- 准备数据集
- 预处理数据
- 创建模型
- 保存自定义模型
- 测试自定义模型
最后,您可以从??GitHub??上获取本文示例项目完整的源代码。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:??Trained A Custom Deep Learning Model Using A Transfer Learning Technique???,作者:Sachin Pal?
