NVIDIA前资深架构师解读:如今人工智能处于什么阶段?
我在NVIDIA研究深度学习已达四年之久,作为一名解决方案架构师,专门研究深度学习相关技术,为客户提供可能的解决方案,并加以实施。
在我加入NVIDIA时,人工智能已经成为一个非常普遍的应用术语,但经常被模棱两可的使用,甚至错误的被描述为深度学习和机器学习。我想从一些简单的定义出发,去一步步深入解读其中含义,不足之处,以及采用新构架创建更完整能力“AI”的一些步骤。
机器学习——将函数与数据进行拟合,并使用这些函数对数据进行分组或对未来数据进行预测。(抱歉,我大大简化了概念。)
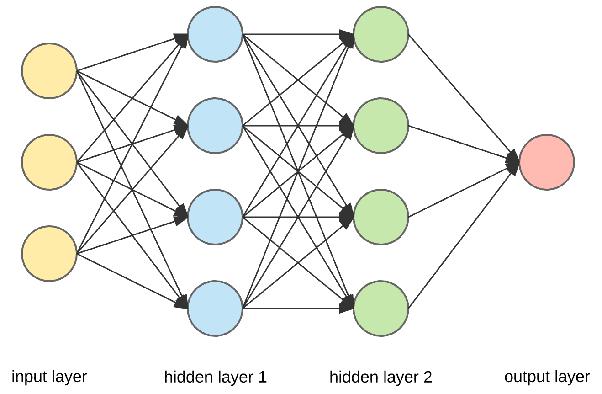
深度学习——将函数与数据进行拟合,如下图所示,函数就是节点层,用于和前后节点相连,其中拟合的参数是这些连接节点的权重。
深度学习就是如今经常被成为AI的概念,但实际上只是非常精细的模式识别和统计建模。最常见的技术/算法是卷积神经网络(CNNs)、递归神经网络(RNNs)和强化学习(RL)。
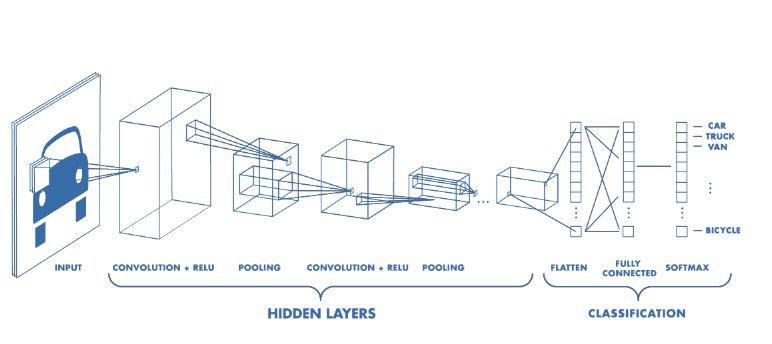
卷积神经网络(CNNs)具有分层结构,通过(训练过的)卷积滤波器将图像采样到一个低分辨率的映射中,该映射表示每个点上卷积运算的值。从图像中来看,它是从高分辨像素到特征(边缘、圆形、……),再到粗糙特征(脸上的鼻子、眼睛、嘴唇……),然后再到能够识别图像内容的完整连接层。CNNs很酷的一点是,其卷积滤波器是随机初始化的,当你训练网络时,你实际是在训练卷积滤波器。几十年来,计算机视觉研究人员一直在手工制作类似的滤波器,但无法像CNNs那样的精准结果。此外,CNN的输出可以是2D图而不是单个值,从而为我们提供图像分割。CNNs还可以用于许多其他类型的1D、2D甚至3D数据。
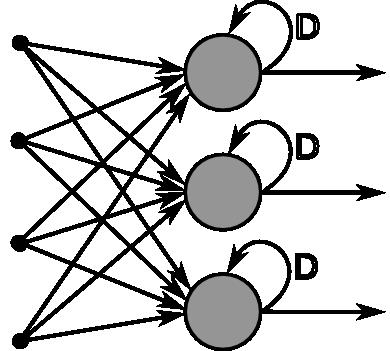
递归神经网络(RNN)适用于顺序或时间序列数据。基本上,RNN中的每个“神经”节点都是存储门,通常是LSTM(长短期记忆)或者长短期的存储单元。当他们被连接到层神经网络时,RNN将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。比如:语言处理或者翻译,以及信号处理,文本到语音,语音到文本……
强化学习是第三种主要的深度学习(DL)方法,强调如何基于环境而行动,以取得最大化的预期利益。一个例子就是迷宫,其中每个单元都存在各自的“状态”,拥有四个移动的方向,在每个单元格某方向的移动的概率来形成策略。
通过反复运行状态和可能的操作,并奖励产生良好结果的操作序列(通过增加策略中这些操作的概率),惩罚产生负面结果的操作(降低概率)。随着时间的推移,你会得到一个最优的策略,它有最高的可能性来取得一个成功的结果。通常在训练的时候,你会对更早的行为的惩罚/奖励打折扣。
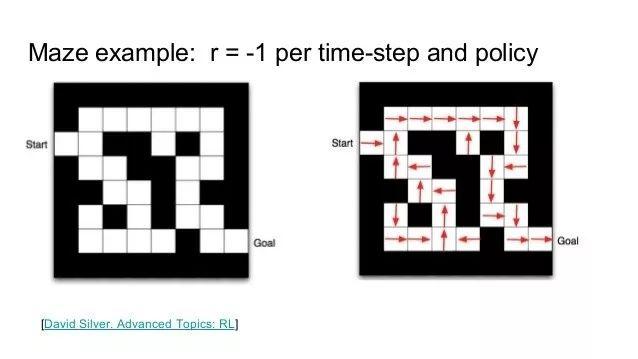
在我们的迷宫事例中,先允许代理穿过迷宫,选择一个方向,使用已有的概率策略,当它达到死胡同时,惩罚它选择的路径(降低每个单元移动该方向的概率)。如果找到了出口,我们则增加每个单元移动方向的概率作为奖励。随着时间的推移,代理通过学习,找到了最快方式。强化学习的这种变化就是AlphaGo AI和Atari电子游戏AI的核心。
最后值得关注的是GANs(生成对抗网络),它更多的是一门技术而不是架构。目前它与CNNs一起用于制作图像鉴别器和发生器。鉴别器是经过训练以识别图像的CNN,生成器是一个反向网络,它采用随机种子生成图像。鉴别器评估发生器的输出并向发生器发送关于如何改进的信号,发生器依次向鉴别器发送信号以提高其准确性,在零和博弈游戏(zero-sum game)中反复往返,直到两者收敛到最佳质量。这是一种向神经系统提供自我强化反馈的方法。
当然,所有这些方法以及其他方法都有丰富的变化和组合,但是一旦你尝试将它们用于特定问题之外的问题时,这些技术有时不会有效。对于实际问题,即使你可以扩展和重新设计网络拓扑并对其进行调整,它们有时也表现不加。往往我们只是没有足够的数据来训练它们,以使得它们在部署中更加精准。
同样,许多应用需要将多种DL技术结合在一起并找到融合它们的方法。一个简单的例子就是视频标记——你通过CNN传送视频帧,在顶部有一个RNN来捕捉这些视频中的那些随着和时间有关的行为。曾经我帮助研究人员使用这种技术来识别四肢瘫痪者的面部表情,向他们轮椅和机器假肢发出命令,每个指令对应不同的面部表情/手势。这起到了一定的效果,但当你扩大规模时,开发和训练它可能会花费更多时间,且变得非常棘手。因为你现在必须调整交织在一起的两种不同类型的DL网络,有时很难知道这些调整会产生什么影响。
现在想象一下,你有多个CNN/RNN网络提供输出,一个深度强化学习引擎对输入状态做出决策,然后驱动生成网络产生输出。其实是很多特定的DL技术组合在一起来完成一组任务。你可以说这是“魔鬼式”的疯狂调参。它会奏效吗?我不知道,如此一来,它将耗费大量资金和时间才开始工作,并且不确定它是否能够很好的训练,甚至在现实条件下进行训练。
我个人观点是,我们目前的DL技术各自代表一个子集,用来简化大脑网络和神经系统的工作。虽然我们称之为“神经”,但实际上并不是,它们都是专门用于特定的任务。
事实上,大多训练DL或者人工智能的人都没有意识到,如今深度学习中的“神经网络”和“神经元”只是更大、更丰富的合成神经元、神经网络和方法。我们今天在DL中使用的大多数人分层我网络和CNN属于前馈神经网络的较小一部分,只是简单地对每个节点处进行加权输入求和,应用简单的传递函数,将结果传递给下一层。
这并不是大脑处理工作的方式,甚至RNN和强化学习也没有给我们真正的人工智能,只是将非常大和复杂函数的参数拟合到大量数据,并使用统计数据找到模式并做出决定。
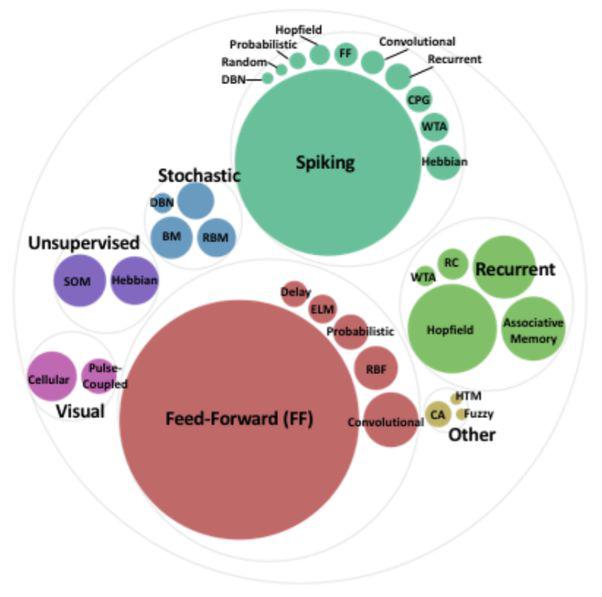
上图顶部和左侧的方法,特别是SNNs(Spiking Neural Networks),给出了一个更准确的模型,来运行真正的神经元工作方式。就像“数积分-火-模型”、Izhikevich脉冲神经元模型那样高效。像“Hodgkin-Huxley”一样接近模拟生物神经元的行为。
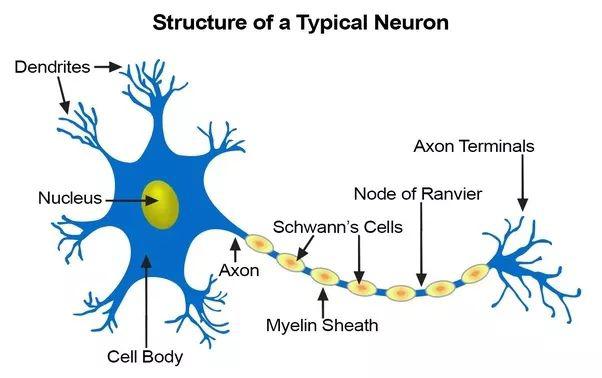
在真实的神经元中,时域信号脉冲沿着树突传播,然后独立到达神经元体,并在其内部的时间和空间中被整合(一些激发、一些抑制)。当神经元体被触发时,它就会在轴突上产生一系列依赖时间的脉冲,这些脉冲在分支时分裂,并需要时间到达突触。当化学神经递质信号经过突触并最终触发突触后树突中的信号时,突触本身就表现出非线性、延迟、依赖时间依赖的整合。在这一过程中,如果两边的神经元在一定的时间间隔内一起点燃,也就是学习过程中的突触即学习,即学习,就会得到加强。我们可能永远无法在硬件或软件中完全复制真实生物神经元的所有电化学过程,但是我们可以寻找足够复杂的模型来代表我们的尖峰人工神经网络中需要的许多有用行为。
这将让我们更像人工智能,因为真正的大脑从信号通过神经元、轴突、突触和树突的传递,获得了更多的计算、感官处理和身体控制能力,从而在复杂的依赖时间的电路中穿行,这种复杂的电路甚至可以有反馈回路,以制造定时器或振荡器等电路,类似于可重复的级联模式激活的神经回路,向肌肉/致动信号的群体发送特定的依赖模式。这些网络也是通过直接加强神经元之间的联系来学习的,这些被称为Hebbian学习。为了进行更复杂的人工智能和决策,它们比我们在上面的例子中使用的CNNs、静态的RNN甚至是深度强化学习都要强大得多。
但是有一个巨大的缺点——目前还没有一种方法可以把这类网络安装到数据上来“训练”它们。没有反向传播,也没有调整神经元之间突触权重的梯度下降操作。突触只是增强或减弱,因此尖峰神经网络在运作的过程中学习,使用Hebbian学习来进行操作,这在实践上可能有效训练我们的合成网络,因为他们首先必须结构正确,以达到一个有用的解决方案。这是一个正在进行的研究领域,在这一领域的突破可能是非常重要的。
我认为,如果我们可以开始解决这些问题,走向更加功能性更强的神经结构,更加充分地展示大脑、神经系统和真正的神经元的工作和学习方式,我们就可以开始将今天使用的那种单一的、更灵活的深度学习方法整合到这些功能更强大和灵活的架构中,这些架构以更优雅的设计来处理多种功能。而且通过这些模型,我们将开启新的神经计算形式,我们将能够将它们应用到计算机视觉、机器人运动控制、听觉、言语,甚至是更像人脑的认知等任务中去。
简单总结一句话:“我们还没有达到人类层面的认知。”
更多信息可以来这里获取==>>电子技术应用-AET<<

