提升深度学习模型预测质量的秘密武器——上下文感知数据 译文 精选
译者 | 朱先忠
审校 | 孙淑娟
在本文中,我想和大家分享我优化深度学习模型输入数据的方法。作为一名数据科学家和数据工程师,我已经成功地将这一技巧应用于自己的工作中。您将通过一些具体的实际开发案例来学习如何使用上下文信息来丰富模型输入数据。这将有助于您能够设计出更为稳健和更准确的深度学习模型。

深度学习模型非常强大,因为它们非常善于整合上下文信息。我们可以通过向原始数据的维度添加几个上下文来提高神经网络的性能。我们可以通过一些巧妙的数据工程化来实现这种目标。
当你开发一个新的预测性深度学习算法时,你可能会选择一个完全适合你特定使用场景的模型架构。根据输入数据和实际的预测任务,你可能已经想到了很多方法:如果是打算对图像进行分类的话,那么你很可能会选择卷积神经网络;如果是预测时间序列或者是分析文本,那么LSTM网络可能是一个很有前途的选择方案。通常,关于正确的模型架构的决策主要由流入模型的数据类型决定。
如此一来,找到正确的输入数据结构(即定义模型的输入层)就成为模型设计中最关键的步骤之一。我通常将更多的开发时间投入到输入数据的形状设计上,而不是其他任何事情上。需要明确的是,我们不必处理给定的原始数据结构,只需找到合适的模型即可。神经网络在其内部处理特征工程化和特征选择(“端到端建模”)的能力并不能使我们免于优化输入数据的结构。我们应该以这样一种方式为数据服务,即模型可以从中获得最佳意义,并做出最明智的决策(即最准确的预测)。这里的“秘密”因素正是上下文信息。也就是说,我们应该用尽可能多的上下文来丰富原始数据。
什么是上下文?
那么,上面我具体说的“上下文”是什么意思呢?不妨让我们来举个例子。玛丽是一名数据科学家,她正在开展一项新的工作,为一家饮料零售公司开发销售预测系统。简而言之,她的任务是:给定一家特定的商店和一种特定的产品(柠檬水、橙汁、啤酒……),她的模型应该能够预测该产品在特定商店的未来销量。预测将应用于数百家不同商店提供的数千种不同产品。到目前为止,系统一直都还运行得不错。玛丽的第一天是去了销售部,那里的预测工作已经完成了,尽管是由经验丰富的销售会计彼得斯手动完成的。她的目标是了解这位领域专家基于什么样的基础决定未来某一特定产品的需求量。作为一名优秀的数据科学家,玛丽预计彼得斯多年的经验将非常有助于定义哪些数据可能对模型更有价值。为了找到答案,玛丽问了彼得斯两个问题。
第一个问题:“你是通过分析什么数据来计算下个月我们将在柏林的商店里销售多少瓶特定品牌的柠檬水?你是如何解释这些数据的?”
彼得斯回答道:“随着时间的推移,我们在柏林的柠檬水销售上迈出了第一步”。随后,他绘制了以下图表来说明他的策略:
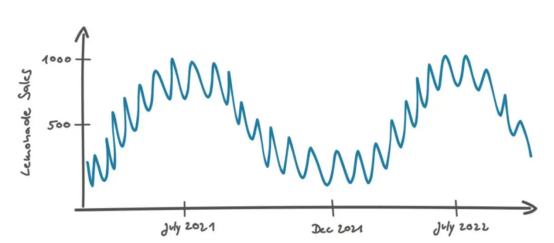
在上图中,我们看到有一条连续的曲线,在7月/8月(柏林夏季时间)出现高峰。夏季气温较高,人们更喜欢吃点心,所以产品的销量会增加,这一点很直观。在较小的时间尺度上(大约一个月),我们看到销售额在大约10件商品的范围内波动,这可能是由于不可预测的事件(随机噪声)导致的。
彼得斯继续说道:“当我看到夏季销售额增加而冬季销售额减少的重复模式时,我认为这也极有可能在未来发生,因此就根据这种可能性来估计销售额。”这听起来很有道理。
彼得斯是在时间上下文中解释销售数据的,其中两个数据点的距离由它们的时间差定义。如果数据不按时间顺序排列,那么很难解释。例如,如果我们只查看直方图中的销售分布,则时间上下文将丢失,我们的最佳未来销售估计值将是一些合计值,例如所有值的中值。
当数据以某种方式排序时,上下文就会出现。
不用说,您应该在正确的时间顺序为您的销售预测模型提供历史销售数据,以保存来自数据库的“免费”上下文。深度学习模型非常强大,因为它们非常善于整合上下文信息,类似于我们的大脑(当然,在本例中是彼得斯的大脑)。
你有没有想过:为什么深度学习对于图像分类和图像对象检测如此有效?因为普通的图像中已经存在很多的“自然”上下文:图像基本上是光强度的数据点,按两个背景维度排列,即x方向的空间距离和y方向的空间间距。而作为动画形式的电影(图像时间序列),它又添加了时间作为第三个上下文维度。
因为上下文对预测非常有利,所以我们可以通过添加更多的上下文维度来提高模型性能——尽管这些维度已经包含在原始数据中。我们通过一些巧妙的数据工程化方法实现了这一点,如接下来所要介绍的那样。
我们应该以这样一种方式来服务数据,即模型可以从中获得最佳意义,并做出最明智的决策。我通常将更多的开发时间投入到输入数据的形状设计上,而不是其他任何事情上。
设计上下文丰富的数据
让我们再回到玛丽和彼得斯的讨论问题上。玛丽知道,在大多数情况下,真实数据看起来并不像上面的图表那么好,所以她稍微修改了一下图表,如下所示:
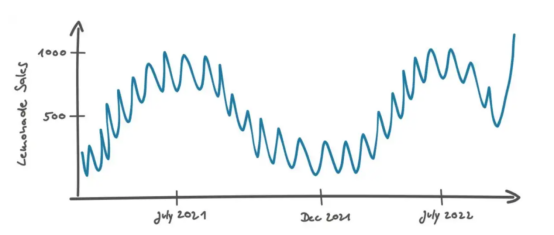
玛丽问的第二个问题是:“如果最后一个销售数据点高于通常的噪音水平怎么办?这可能是一种真实的情形。也许该产品正在进行一场成功的营销活动。也许配方已经改变,现在味道更好了。在这些情况下,效果是持久的,并且未来的销售将保持在相同的高水平。或者可能只是由于随机事件而出现的异常。例如,一个参观柏林的学校班级学生碰巧走进商店,所有的孩子都买了一瓶这种柠檬水品牌。在这种情况下,销售增长额并不稳定,只能算是噪音数据。在这种情况下,你如何决定这是否会是真正的销售效果呢?”
你可以看到彼得斯在回答之前不断地挠头:“在这种情况下,我关注的是与柏林类似的商店的销售情况。例如我们在汉堡和慕尼黑的商店。这些商店具有可比性,因为它们也位于德国主要城市。我不会考虑在农村的商店,因为我期望那里有不同口味和偏好的不同顾客。”
他将其他商店的销售曲线与两种可能的场景相加。“如果我看到柏林的销量增长,我认为这是噪音。但是,如果我看到汉堡和慕尼黑的柠檬水销量也在增长,我希望这会是一个稳定的效果。”

因此,在一些颇为困难的情况下,彼得斯会考虑更多的数据,以便做出更明智的决策。他在不同商店的上下文中添加了一个新的数据维度。如上所述,当数据以某种方式排序时,上下文就会出现。要创建一个商店上下文,我们首先必须定义一个距离度量值,以便相应地从不同的商店订购数据。例如,彼得斯根据商店所在城市的大小来区分商店。
通过运用一些SQL和Numpy编程技巧,我们就可以为我们的模型提供类似的上下文。首先,我们要了解我们公司商店所在城市的人口规模;然后,我们根据人口差异来衡量所有商店之间的距离;最后,我们将所有的销售数据组合在一个2D矩阵中,其中第一个维度是时间,第二个维度是我们的商店距离指标。
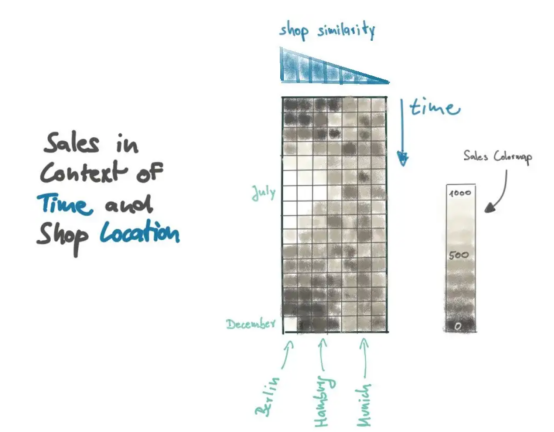
图中的销售矩阵提供了最近柠檬水销售的良好概括,由此产生的模式也可以直观地得到解释。看看销售矩阵左下角的数据点:这是柏林最近的销售数据。注意,那个亮点很可能是一个例外,因为类似的商店(例如汉堡)不会重现销售额的急剧增长。相比之下,7月份的销售高峰是由类似的商店再现的。
因此,我们总是需要添加一个距离指标来创建上下文。
现在,我们将彼得斯的说法转化为数学术语,可以根据产品所在城市的人口规模来建模。在添加新的上下文维度时,我们必须非常仔细地考虑正确的距离指标。这取决于我们想要预测的实体受到影响的因素。影响因素完全取决于产品,必须相应地调整距离指标。例如,如果你看看德国的啤酒销售,你会发现消费者很可能会从当地的啤酒厂购买产品(你可以在全国各地找到大约1300家不同的啤酒厂)。
来自科隆的人通常喝库尔施啤酒,但当你驱车半小时向北前往杜塞尔多夫地区时,人们会避开库尔施,转而喝更黑、麦芽味更浓的阿尔特啤酒。因此,在德国啤酒销售的情况下,通过地理距离来模拟商店距离可能是一个合理的选择。然而,其他产品类别(柠檬水、橙汁、运动饮料……)的情况并非如此。
因为我们添加了一个额外的上下文维度,我们创建了一个上下文丰富的数据集,在该数据集中,潜在的预测模型可以获得不同时间和不同商店的柠檬水销售概况。这使得模型可以通过查看最近的销售历史并左右查看其他地点的类似商店,对柏林商店的未来销售做出明智的决定。
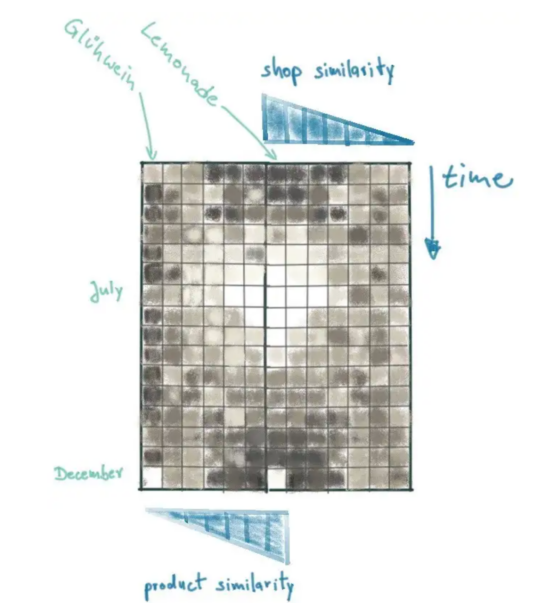
从这里开始,我们可以进一步添加产品类型作为附加的上下文维度。因此,我们用其他产品的数据来丰富销售矩阵,这些数据根据它们与柠檬水的相似性进行排序(我们的预测目标)。同样,我们需要找到一个好的相似性指标。可乐比橙汁更像柠檬水吗?我们可以根据什么数据定义相似性排名?
在商店的情况下,我们有一个连续的衡量标准,那就是城市的人口。现在我们正在处理商品类别。我们真正想找到的是与柠檬水具有类似销售行为的产品。与柠檬水相比,我们可以对所有产品的时间分辨销售数据进行互相关分析。通过这种方式,我们获得了每个产品的皮尔逊相关系数,它告诉我们销售模式有多相似。可乐等软饮料的销售模式可能与柠檬水相似,夏季销量会增加。其他产品的行为将完全不同。例如Gühwein,这是一种在圣诞市场上供应的温暖甜美的葡萄酒,在12月可能会有强劲的销售高峰,而在今年余下的时间里几乎没有销售。
【译者注】时间分辨(time-resolved):物理学或统计学名称。与之相关的另一些常用词是时间分辨诊断测量(time-resolved diagnosis)、时间分辨光谱(time-resolvedspectrum)等。

交叉相关分析将显示Glühwein葡萄酒的皮尔逊系数较低(实际上是负的),而可乐的皮尔森系数较高。
尽管在销售矩阵中添加了第三个维度,但我们可以通过将第二个维度以相反的方向连接起来来包含产品上下文。这样就将最重要的销售数据(柏林柠檬水销量)放在了中心位置:
添加更多特征
虽然我们现在有一个信息非常丰富的数据结构,但到目前为止,我们只有一个特征:在特定的时间特定的商店中为特定产品销售的产品数量。这可能已经足以进行稳健和精确的预测,但是我们还可以从其他数据源添加额外的有用信息。
例如,饮料购买行为很可能取决于天气。例如,在非常炎热的夏天,对柠檬水的需求可能会增加。我们可以提供天气数据(如气温)作为矩阵的第二层。天气数据将在与销售数据相同的上下文(商店位置和产品)中订购。对于不同的产品,我们将获得相同的空气温度数据。但是,对于不同的时间和商店位置,我们将看到还是存在差异的,这可能会为数据提供有用的信息。

如此一来,我们就拥有了一个进一步包含销售额和温度数据的三维矩阵。需要注意的是,我们没有通过包括温度数据来添加额外的上下文维度。正如我之前指出的,当数据以某种方式排序时,上下文就会出现。对于我们建立的数据上下文,我们根据时间、产品相似性和商店相似性对数据进行排序。然而,特征的顺序(在我们的例子中,是指沿着矩阵的第三维度)是不相关的。其实,我们的数据结构与RGB彩色图像相当。在RGB图像中,我们有两个上下文维度(空间维度x和y)和三个颜色层(红、绿、蓝)。为了正确解释图像,颜色通道的顺序是任意的。一旦你定义了它,你就必须保持它的顺序。但是对于在特定上下文中组织的数据,我们没有距离指标。
总之,输入数据的结构不是预先能够确定的。因此,我们应该充分发挥自己的创造力和直觉来挖掘新的可行性指标了。
总结
通过向时间分辨的销售数据添加两个附加上下文和一个附加的特征层,我们获得了具有两个“通道”(销售和温度)的二维“图片”。该数据结构提供了特定商店最近柠檬水销售的综合视图,以及来自类似商店和类似产品的销售和天气信息。到目前为止,我们创建的数据结构非常适合由深度神经网络进行解释——例如,包含多个卷积层和LSTM单元。但是限于篇幅,我不打算讨论如何以此为基础开始设计一个合适的神经网络。这可能是我的后续文章的主题了。
我希望你能够拥有自己的想法,虽然你的输入数据的结构可能不是预先确定的,但你可以(应该)发挥你所有的创造力和直觉来扩展它。
一般来说,上下文丰富的数据结构可不是免费提供的。为了预测公司所有门店的各种产品,我们需要生成数千个上下文丰富的销售概况信息(每个门店产品组合一个矩阵)。您必须投入大量的额外工作来设计有效的处理和缓冲措施,以使数据成为您需要的形式,并为后续的神经网络快速训练和预测周期提供需要的数据。当然,这样一来,你会得到一个期望的深度学习模型,它可以做出准确的预测,即使在高噪声数据下也能表现得非常稳健,因为它可以看起来能够“打破常规”,并做出非常明智的决定。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:??Context-Enriched Data: The Secret Superpower for Your Deep Learning Model??,作者:Christoph M?hl
