中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
问“ChatGPT,人工智能会如何发展?”
答“人工智能的行业落地将继续加速,今后会更加广泛应用于工业、消费、金融、医疗、交通、教育、政府等多个领域。”
今天,你和ChatGPT聊天了吗?它仅仅开发13天就匆匆上线,却在两个月就获得过亿用户。这一基于AI的产品持续火热出圈,在社会各界引发越来越多的热情。以此为契机,业界对于人工智能技术也展开新讨论,特别是大模型的创建和学习能力成为关注的焦点。
一AI技术变革:算法、算力、数据
目前,预训练技术(Pre-Trained Model)是人工智能研究的重要突破口。传统的研究方法中,标注成本一直是阻碍AI算法推向更大数据集合的障碍;预训练技术不依赖数据标注,就可以训练出一个大规模深度学习模型。全球AI团队选择儿童电视节目《芝麻街》中的木偶人物来命名各种新预训练算法,比如Elmo、Bert、Ernie等。
在对预训练模型的各种不同的技术评测中,算法性能展示了一个规律:数据规模越大、预训练模型参数越多,算法输出精度往往也越高。随着技术的突破,模型规模的不断增长,其展现出的能力潜力和丰富的应用场景激发了更多的企业和研究机构投身其中。超级模型除了可以消化更大规模的数据,也需要消耗更高的算力。
OpenAI公司对人工智能算法训练所消耗的算力做了一个统计,结果发现,从2012年到2020年,人工智能模型训练消耗的算力增长了三十万倍,平均每3.4个月翻一番,这超过了摩尔定律的每18个月翻番的增长速率,人工智能技术成为推动IT技术发展的新的动力引擎。
二全球AI技术发展格局:中美领跑
从2019年开始,AI大模型突然爆发,参数规模以指数级的快速增长。从2014年到2018年,AI模型参数规模还在一亿的数量级上下浮动。
2019年2月,OpenAI的GPT-2达到了15亿参数规模
2020年6月,GPT-3达到了1750亿参数的规模
2021年1月,谷歌大脑推出了1.6万亿参数规模超级模型,再次刷新规模记录
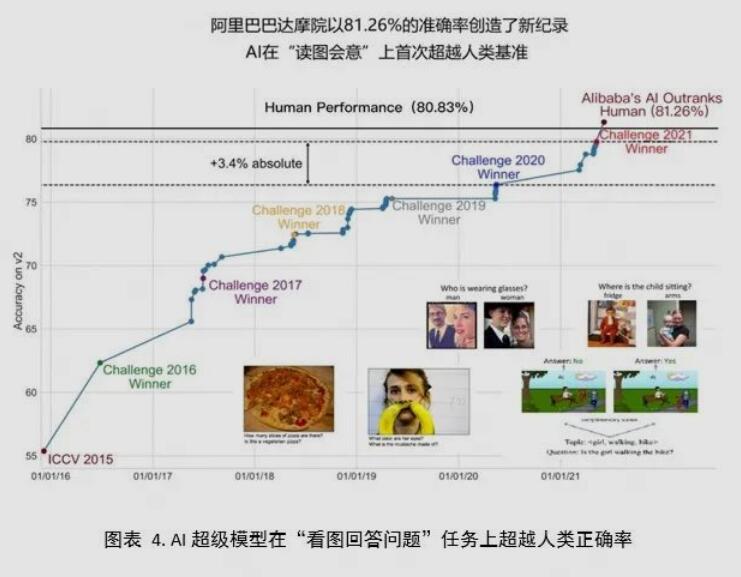
中国本土技术团队也加入到这一场人工智能技术竞赛中。阿里巴巴达摩院在2020年初启动中文多模态预训练模型M6项目,同年6月推出3亿参数的基础模型。2021年1月,模型参数规模到达百亿,已经成为世界上最大的中文多模态模型;2021年5月,具有万亿参数规模的模型正式投入使用,追上了谷歌的发展脚步;2020年10月,M6的参数规模扩展到10万亿,成为当时全球最大的AI预训练模型[1]。
不少中国企业和研究机构也积极研发投入中文预训练大模型项目。在人工智能超级大模型的这条数据、算法和算力三轮同时驱动的技术赛道上,中美两国技术团队已经形成了“两架马车”的发展模式,不断刷新人工智能能力规模上的边界线。
基于AMiner科技情报系统的数据[2],根据AIGC领域知识图谱(AIGC领域知识图谱及关键词参见附件1)进行检索,利用文献计量方法,我们对2012年到2021年期间全球发表的AIGC高质量论文(论文引用量排名前1%)做比较,共计1,646篇论文入选。在AIGC高质量论文领域,中国和美国数量几乎持平,并大幅度领先其他国家。
从发展趋势上看,在AIGC领域,中国有后来者居上、超越美国的趋势。
在更大的数字技术领域,中国在高价值论文部分,同发达国家仍有不小差距[3],未来需要产、学、研一起努力,共同推动中国数字技术向价值链高端跃升。
三AI产业发展:资本与人才
深蓝打败了卡什帕罗夫、AlphaGo战胜了李世石……对于业内人士来说,这些曾经轰动一时的现象级技术进步,仅仅是完成固定任务的弱人工智能。开发具有跨领域学习能力的强人工智能技术才是人类努力的终极目标。常识学习、跨领域模型迁移、小样本和零样本学习……一个个技术的拦路虎挡在通往强人工智能的技术道路上,而人工智能超级模型给这条道路照亮了前方。
OpenAI为训练GPT-3超级模型投入了1200万美元的成本。在人工智能超级模型的赛道上,赛手需要掌握海量的数据、超大规模的人工智能计算平台以及掌握核心技术能力的算法团队,三者缺一不可。这也许侧面解释了在追求人工智能技术最前沿的赛道上,目前只出现了美国和中国技术团队的身影。中美两国在人工智能技术领域形成了激烈的竞争格局。数据、算法和算力是这一轮人工智能技术浪潮的三轮驱动引擎。中国拥有全世界最大的互联网和移动互联网用户规模,在数据领域让我国具有毋庸置疑的领先地位,互联网平台企业也构建出极具竞争力的算力平台和算法团队。
在斯坦福大学HAI研究所发布的2021 全球AI指数报告中[4],2020年全球尽管受新冠疫情拖累,在各方面的经济发展都受到极其负面的影响。人工智能领域的发展却一枝独秀,相关投资仍然在大幅增加,2020年私人资本在人工智能领域的投资比前一年增加了9.3%,远高于疫情前2019年5.7%的增长率。在资金方面,美国仍然是人工智能私人资本的最大目的地,2020年总投资超过230亿美元,是中国相关资金99亿美元的两倍多。
近日发布的《2023全球数字科技发展研究——科技人才储备实力研究报告》[5],对包括AI在内的各国数字科技人才储备情况做了全面比较。结果显示,与美国相比,中国数字科技人才基数大,但存在高层次人才少、净流出数量多以及人才集中在高校而不是企业等问题,中国在巩固数字科技人才方面的工作任重道远。
四ChatGPT的未来:脑力的解放
OpenAI公司应该也没有想到ChatGPT会一夜爆红,这款对话机器人(chatbot)产品不仅开发时间短,模型也没有构建在OpenAI即将发布的最新一代GPT4模型之上,而是采用了上一代的GPT3的增强模型[6]。
不过,从生成式AI技术(Generative AI或AIGC)的发展趋势来看,ChatGPT这一类现象级应用的横空出世与迅速爆红却并不意外。随着AI大模型技术的不断成熟,AIGC技术已经走出实验室,应用场景也已经从初始的文本生成发展到多模态领域:
谷歌旗下的Deepmind公司推出了自主编程应用AlphaCode,在 Codeforces 举办的编程比赛中,超过了 45.7% 的人类参赛者[7]
OpenAI开发的另一款生成应用DALL·E-2,入选了时代杂志评选的2022年度最佳发明[8]
英伟达开发了一款3D模型生成工具Magic3D,用户输入文本描述就可以自动生成结构极其复杂的3D模型[9]
阿里巴巴达摩院多模态大模型M6,利用文本输入可以自动驱动人体3D模型的动作合成[10]
在图文创作、代码生成、3D模型设计、3D动画制作等领域,生成式AI技术展示着深厚的潜力,其应用边界也将随着技术的进步与成本的降低扩展到更多领域。
高科技投机机构方舟投资(ARK Invest)发布的报告[11]预测,以AIGC为代表的新一代人工智能技术将辅助知识工作者(包括教师、律师、医生、财务、程序员等白领职业)提高工作效率。报告预测,到 2030 年,AI 将大幅提高知识工作者的工作效率,平均工作效率增加140%,新一代人工智能技术将有可能大幅度降低脑力劳动者的工作强度。如果这一切成为现实,或将是继人类历史上由于动力革命而摆脱繁重的体力劳动之后,人类社会发生的又一次伟大的技术革命。
