超异构计算时代的操作系统架构综述
经常有软件的同学会问到一个尖锐的问题:在超异构软硬件融合的时代,操作系统等软件是不是需要重构,是不是要打破现有的整个软件体系。我赶紧解释:“超异构软硬件融合不改变现有的软件体系,所有的软件该是什么样还是什么样。”
当然了,上层不改变,不意味着底层不调整。虽然可以“躺平”,在超异构计算平台直接复制现有的软件架构;但要想发挥超异构计算平台的强大性能,底层软件做一些调整也是必然的(当然,这些调整最好是润物细无声的渐进式迭代)。
底层软件最核心的是操作系统。因此,引出了我们今天要讨论的话题:在超异构计算时代,操作系统架构会有哪些改变?
本文来自个人的一些思考以及和周围朋友们的一些探讨,我不是操作系统专业出身,班门弄斧,抛砖引玉,希望得到各位专业人士的指正。
01经典操作系统综述
1.1 操作系统的作用
操作系统是管理计算机硬件、软件资源,并为应用程序提供公共服务的系统软件,是计算机系统的内核与基石。操作系统需要:管理与配置内存、决定系统资源供需的优先次序、控制I/O设备、操作网络,以及管理文件系统等基本事务,也需要提供一个让用户与系统交互的操作界面。
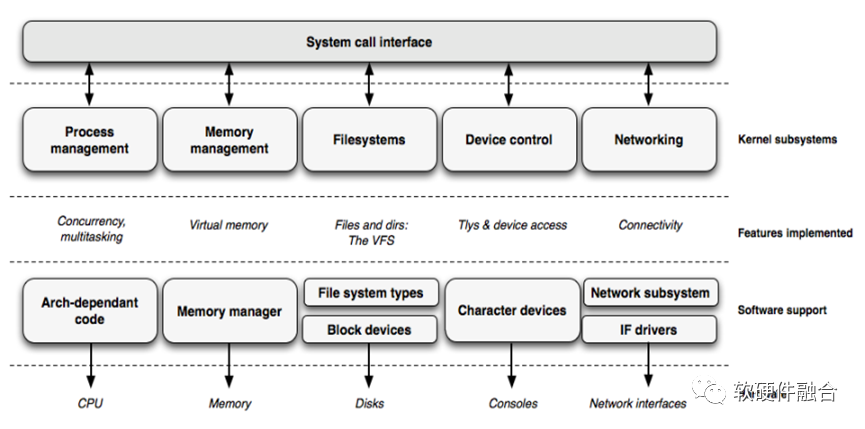
一个标准的操作系统通常提供以下功能:进程管理(Processing management)、内存管理(Memory management)、文件系统(File system)、网络通信(Networking)、安全机制(Security)、用户界面(User interface)和驱动程序(Device drivers)等。
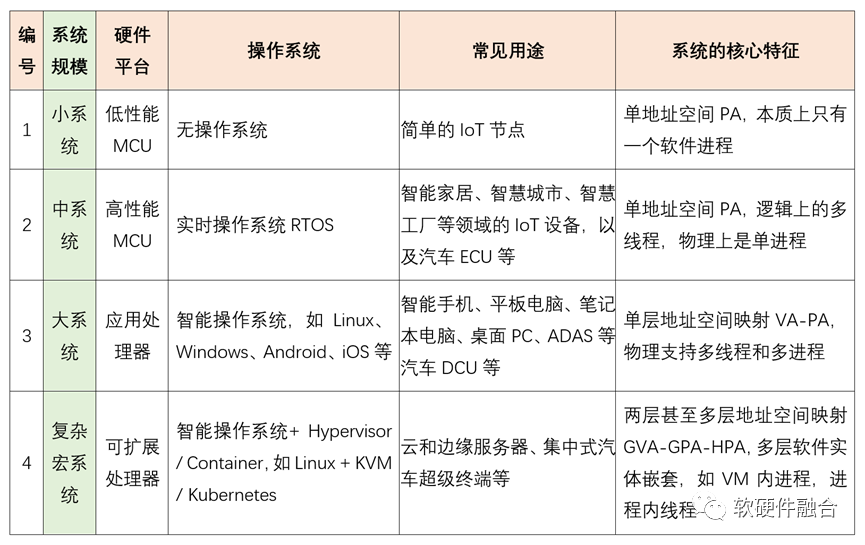
1.2 按照系统规模的操作系统分类
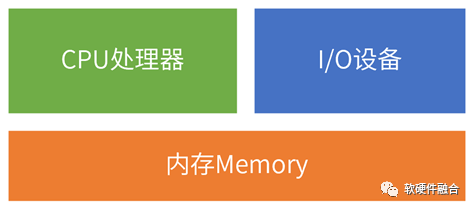
1.3 经典计算机的功能模块
经典的冯诺依曼架构告诉我们,计算机是由五部分组成的:控制器、运算器、存储器、输入设备和输出设备。我们可以把这个模型的组成部分再简化一下,计算机是由三大部分组成的:
处理器:控制器和运算器组成处理器,用于数据的计算;
I/O设备:也就是输入设备和输出设备的整合,单个设备完成数据的输入和输出;
内存:数据存储的地方,用于输入数据的缓冲、中间结果的暂存以及输出数据的缓冲。
所有的软件都是在CPU处理器上运行的。
软件在CPU的运行,主要有两种作用,一种是硬件的管理(控制面),一种是硬件的使用(计算/数据面):
操作系统软件主要是负责硬件的管理,包括CPU运行软件的调度、I/O设备的驱动以及内存管理等。
而在硬件上(绝大部分时间)运行的是用户的应用软件,主要以进程和线程的方式运行。这里包括从I/O设备和内存的数据交互(也是驱动程序功能的一部分),CPU从内存的数据读写(包含在具体的应用程序里),以及CPU上运行的进行数据计算/处理的用户程序进程/线程本身。
1.4 经典操作系统的任务调度
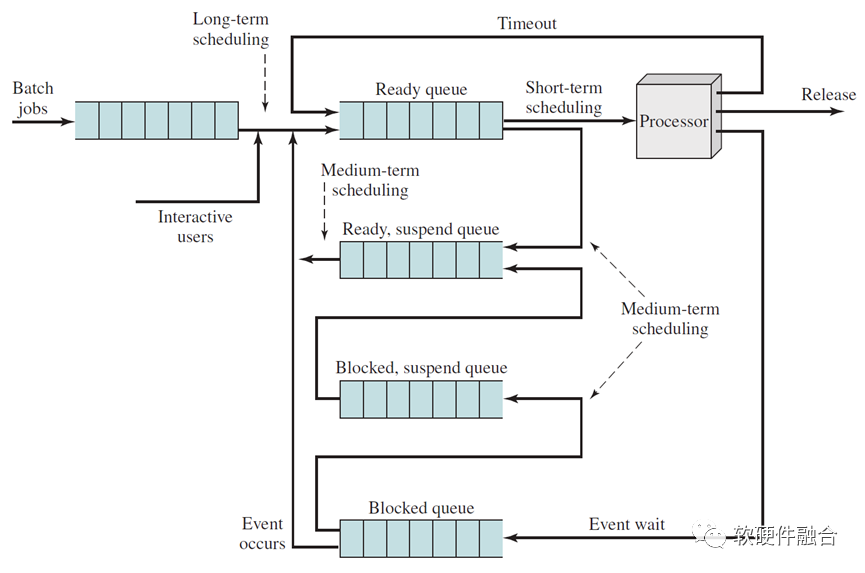
图 单核系统的用于调度的队列框图
多进程宏观并行、微观分时调度是现代操作系统最显著的特征。同一时刻,在内存中有多个进程/线程程序,它们分别处于运行态(在CPU中运行)、就绪态(在内存等待)、阻塞态(在内存挂起)。根据事件触发以及进程/线程的状态,也根据调度算法来选择要进入执行状态(送到处理器运行)的进程/线程,也决定了每个进程的状态更新。
在现代操作系统里,每个进程会包含一个或多个线程,进程作为资源分配的最小单位,线程作为任务调度的最小单位。
多核任务调度,最简单的是复用单处理器调度的基本架构,将所有的工作任务放入一个单独的队列。但这种方式扩展性不好,多核调度的时候需要频繁地给队列加锁。锁会带来巨大的性能损失,并且随着CPU核的数量增加而调度的性能指数级下降。还有一个问题,是调度可能会引起线程在不同的处理器运行,这会导致在CPU缓存中的程序现场需要跨CPU访问,从而导致性能的下降。
于是,有了多队列任务调度,比如给每个CPU核创建独立的任务队列,分别调度。每个CPU调度之间相互独立,就避免了单队列方式中由于数据共享及同步带来的问题。多队列任务调度,具有更好的扩展性,随CPU核的数量增加,锁和缓存跨CPU访问的问题不会扩大。但多队列也会有新问题,即负载可能会不够均衡。所以,就需要任务在不同的队列迁移,从而确保所有的CPU负载足够均衡。
02操作系统视角看超异构计算架构
2.1 超异构计算简介
从单核串行到(同构)多核并行,再从同构的多核并行到异构的多核并行。而典型的异构多核也有CPU+GPU以及CPU+DSA两大类模式。
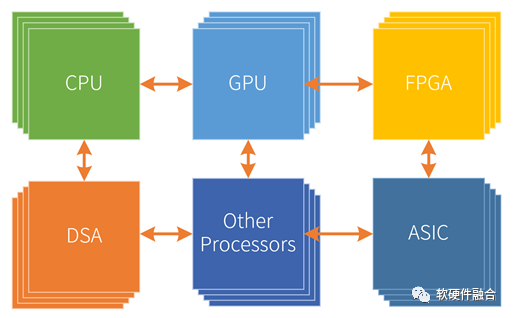
超异构计算指的是多种异构计算的融合,最终形成CPU+GPU+多个不同类型DSA以及其他各种可能的处理器类型的模式。
因此,我们可以把计算架构的发展分为如下几个阶段:
第一阶段,单核CPU串行计算;
第二阶段,多核CPU同构并行计算;
第三阶段,CPUs+GPUs的异构并行计算;
第四阶段,CPUs+DSAs的异构并行阶段(n,单个领域的多个同构DSA);
第五阶段,CPUs+GPUs+DSAs的超异构并行阶段(m*n,多个领域DSA,每个DSA还有多个)。
2.2 超异构计算机的功能模块分类
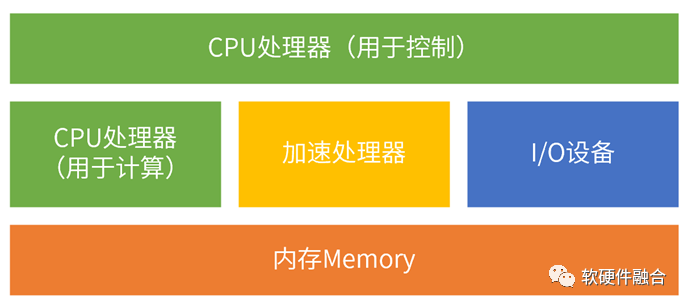
在经典计算机架构下,我们划分了三个模块:CPU处理器、I/O设备和内存。在超异构架构下,我们做一些调整:
内存和I/O设备保持不变,跟经典计算机的作用一致。
把CPU按照功能分为两类,一类是用于控制类任务的CPU,一类是用于计算类任务的CPU。计算类CPU则和加速处理器组成对等架构下的计算处理器节点。需要注意的是,这里的CPU划分是逻辑上的,物理上可能还会是同一个CPU,控制CPU和计算CPU分时共享同一个物理CPU。
跟异构计算一样,增加了加速处理器类别。但和异构的单个加速处理器相比,超异构情况下的加速处理器可以有很多类型,每种类型还可以有很多处理核。在以CPU为中心架构下,加速处理器是跟I/O类似的外围设备;在超异构计算以数据为中心架构下,加速处理器是和CPU功能类似的对等的计算处理器。
2.3 超异构操作系统的任务调度
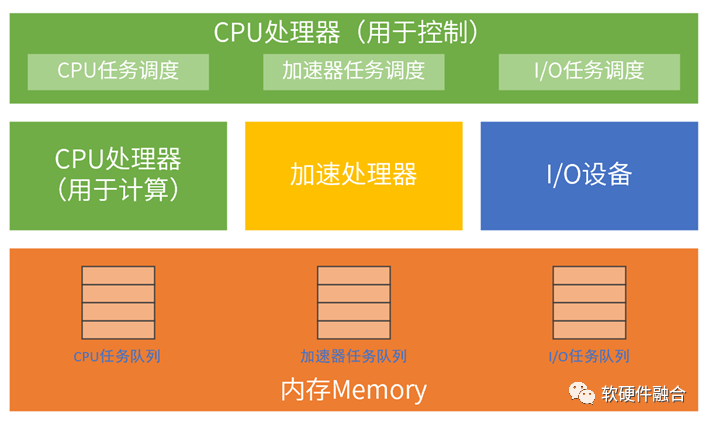
我们在上一节的超异构计算机的功能模块图基础上,加入任务调度的示意信息,超异构操作系统的任务调度包含三部分:
CPU任务调度和经典CPU计算机一致,负责CPU任务的调度,最终把任务送到CPU去执行;任务的执行会包含任务的程序(片段)输入、数据的输入以及计算结果的输出。
I/O任务调度和经典CPU计算机一致,这里的任务调度,是通过驱动来完成的;任务的执行主要是外部数据的输入输出,比如网络、存储等数据。
增加的加速处理器调度部分,也是复用现有的各种加速器的框架及Runtime等相关的加速处理器软件堆栈。任务的执行,跟CPU类似,有程序(片段)、数据输入和结果输出。
2.4 超异构操作系统分层架构

根据1.1节的经典操作系统分层架构,我们可以给出一个典型的超异构操作系统的分层架构图。除了经典计算机的各种功能组件之外,还需要加入GPU、各类DSA的相关软件栈。
以硬件资源为单位的独立的软件堆栈和经典计算机操作系统以及添加了异构计算软件框架的内容是基本一致的。如果不考虑性能优化的话,可以复用现有的技术栈。但这样能提升的性能非常有限,这跟SOC中的多异构软件级协同没有本质区别。
随着性能要求越来越高,也随着硬件资源类型和数量越来越多,不同硬件资源之间的交互问题会凸显。需要考虑基于硬件所形成的垂直软件栈之间的协同,才能最大限度地释放超异构平台的性能优势。
03超异构平台软件架构
需要解决的若干技术挑战
3.1 处理器架构标准化问题

加速处理器的运行,必然是需要有Host CPU的上层软件的控制和协作;加速处理器要想更加高效的运行,把性能优势发挥出来,并且让软件人员更容易使用,就需要有功能强大的软件框架,也需要形成相应的生态。例如,强大的NVIDIA GPU,离不开CUDA软件框架和生态。理想化的,这个框架需要足够开放标准,并且最好能集成进主流的操作系统,比如Linux。
框架承上启下:从框架往下,硬件设计者需要自己的硬件支持主流开发框架,才能使得自己的产品在客户的业务场景低门槛的使用起来;从框架往上,软件开发者不需要关注硬件细节,只需要关注自己的业务创新,把精力投入到更高价值的工作。
传统的开发思路是“从下而上,硬件定义软件”:比如x86做得足够的好,所以才有了基于x86平台的工具链以及成熟的商业应用软件等强大的软件生态;再比如NVIDIA的GPU和CUDA,基于自己的GPGPU,构建了足够好的CUDA框架。上层的软件开发者都是基于这些硬件平台来构建自己的软件。
随着行业的发展,现在逐渐地过渡到了“自上而下,软件定义硬件”的阶段:通常是,用户的业务已经在x86 CPU平台完成了开发,并且整个业务系统已经得到了充分的验证,业务逻辑也是相当的确定。用户希望自己掌控系统的一切,硬件只是整个系统的运行平台而已。客户面临性能和成本的压力,于是希望从x86迁移到ARM或RSIC-v,或者通过硬件进行性能加速——但绝对不希望改变自己已有的软件业务逻辑!
最终,扮演关键角色的会是框架:
框架可能是芯片巨头提供的封闭或开放框架(对自己的芯片更加友好);
也可能是某些大客户自有的框架(需要芯片公司去适配);
还可能是全行业形成广泛共识的框架(软件基于公有框架开发,不绑定硬件;硬件基于框架设计,不需要太多差异化定制,芯片可以起量,降低单位芯片成本)。
在框架的约束下,各类加速处理器的架构需要逐步收敛,走向标准化。
这里再强调一下“架构”的概念:架构指的是硬件呈现给软件的接口,也即软件视角看到的硬件;而硬件实现的架构通常称为微架构。
3.2 内存旁路实现高性能数据交互
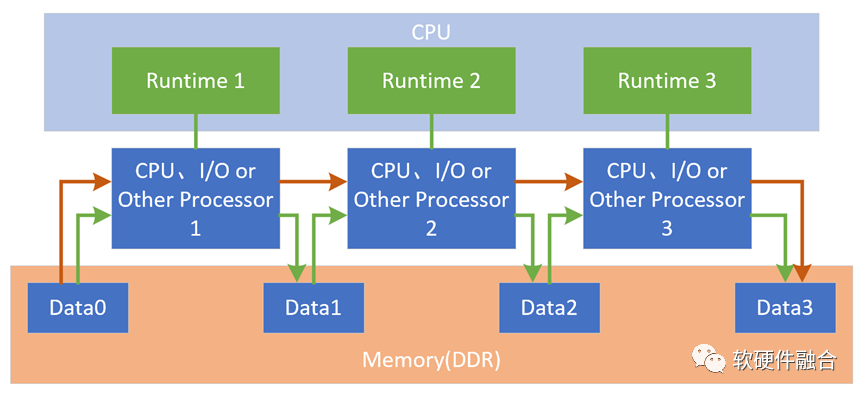
在SOC平台上,所有的硬件加速器是通过软件联系到一起的,如上图的绿色连线部分。这样的方式有如下一些问题:
所有的数据交互需要CPU软件参与,然后数据共享是通过内存。但是,随着大通量数据处理越来越多,而CPU已经性能瓶颈,CPU越来越成为整个系统的性能瓶颈。
因为要频繁的访问主存,对存储的带宽要求很高;并且从整个处理数据通路比较长,也会显著的增加处理延迟。
随着硬件的处理器资源越来越多,处理器交互的流量会指数级激增,也对现有的软件实现的交互架构提出了更多的挑战。
需要构建一套快速的内存旁路机制,让加速处理器的处理结果不需要回到内存,而是直接的发送给下一个处理器,如图中橙色连线部分。
当然,这里只是对这个问题的简单示意,实际的问题远比这个示意情况复杂的多。
3.3 应用跨不同类型处理器的问题
当处理器的类型越来越多,应用也需要有一定的适应性:
不但可以跨不同的同类型处理器运行;
还需要能跨CPU、GPU和DSA运行;
并且这种跨越可以是静态的也可以是动态的。
应用跨处理器类型的价值体现在:
最大化的利用硬件提供的更高层次的能力。性能能力DSA>>GPU>>CPU,而不同平台的处理器资源不尽相同,可以让应用尽可能选择性能更好的处理器。
同时,也提高了整个软件系统的的自适应能力。使得整个软件系统可以在,由不同资源组合而成的,异质的超异构平台上运行。
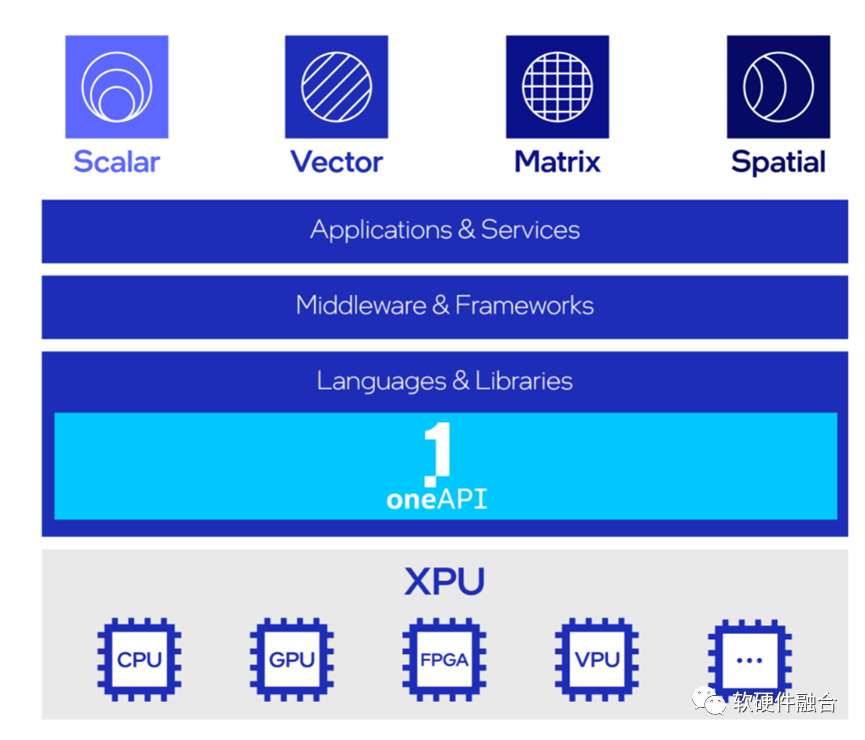
要实现应用跨不同类型处理器运行,需要在框架层面做很多工作。这块的技术和知识,可以参考Intel的oneAPI。
oneAPI是开源的跨平台编程框架,底层是不同的XPU处理器,通过oneAPI提供一致性编程接口,使得应用跨平台复用。
3.4 分布式扩展的问题

在数据中心,大家进行资源和算力扩展的时候通常有两种方式,一种是提升单位设备的能力(Scale up),一种是提高设备的数量(Scale out)。
在之前文章中讲到算力提升的时候,我们也给出了一个公式:“实际总算力=(单处理器芯片)性能x处理器芯片数量x利用率”:
一方面,我们需要通过超异构来实现单芯片的性能飞速提升(Scale up);
另一方面,还需要考虑芯片的高可扩展性,这样就可以通过扩展芯片和设备数量的方式快速的提升整体算力(Scale out);
此外,还需要有强大的分布式操作系统的支持,把更多的跨芯片、跨服务器、跨数据中心、跨云网边端的宏观数以亿计的各种资源整合成一个资源和算力整体,这样就可以非常方便的、随时随地的为千千万的用户提供无穷无尽的算力,从而支持用户数以万亿计的各类应用和服务。
审核编辑:刘清
