数据库行业的 “叛逆者”:大数据已“死”,MotherDuck 当立

图片来源@视觉中国
文 | 牛透社,作者 | 郑博
数据库行业发展至今,在数据层面有很多的加速和变革,尤其是过去几年的云数仓爆炸式增长,带来了行业的很多变化。毫无疑问,云数据仓库已成为企业数据堆栈的基石,各种规模的公司和组织习惯使用数据仓库来分析业务数据。Snowflake 的迅速崛起就是这一趋势的典型代表。
但如果我们把大数据的变量拆成速度、数量和多样性三个维度,我们发现大家最关注的维度仍然是速度。当我们重新审视对“大数据”的定义,并且结合数据资产的要素,我们最重要的需求是从 OLTP [1] 数据库处理的数据资产上的微服务对低延迟消耗的要求。
与此同时,很多大数据部门购买了所有新工具并从遗留系统迁移之后,他们发现仍然无法去理解这些数据,也许数据大小根本不是问题所在。世界的数据量变大了,但硬件也以更快的速度变大了,供应商仍在推动硬件的能力扩展。今天我们就来聊一家有点“不一样”思路的数据库创业公司——MortherDuck,看看他们的产品 DuckDB 是如何来理解这个世界的。
历史沿革:欧美合作的商业化产物
说起 MortherDuck 的前世今生,首先还是要从产品 DuckDB 讲起。DuckDB 是一个专门构建的进程内在线分析处理数据库管理系统,其旨在实现高效数据分析。从 2019 年 DuckDB 第一个开源版本发布,到 2021 年,短短两年间,DuckDB 的周下载量增长迅速。此时,这个原本由荷兰数学和计算机科学研究学会 (CWI) 创立的项目被分拆出来独立运作,项目研究人员 Hannes Mühleisen 和 Mark Raasveldt 成立了 DuckDB Labs。
故事至此,为什么 MortherDuck 还未出现呢?别急,我们还缺少另一位主角——谷歌 Big Query 的创始工程师 Jordan Tigani,他也关注着 DuckDB,并一直寻求为市场提供轻型数据库产品。在和 DuckDB Labs 的联合创始人 Mühleisen 沟通并获得支持后,Tigani 开始尝试将开源的 DuckDB 商业化。新公司 MortherDuck 就此诞生,并获得了由红点资本 (美国) 领投的 1250 万美元天使轮融资和 A16Z 领投 3500 万美元 A 轮融资,公司估值 1.75 亿美元。
回头来看,作为一家起步时间不长的初创公司,获得这样的资本认可不可谓不成功。由于 DuckDB 并非 MortherDuck 的原创开源产品,因此,想要未来长久且稳定地基于开源产品构建服务,得到项目创始团队的支持至关重要。
在双方的合作中 DuckDB 团队一定程度上参与了 MotherDuck,而 MotherDuck 又是 DuckDB 基金会的成员,该非营利组织拥有 DuckDB 的大部分知识产权。DuckDB 自己的商业部门 DuckDB Labs 是 MotherDuck 的股东。不得不说 Tigani 与 DuckDB Labs 合作是聪明之举,通过此举,双方利益得以绑定。
定位:OLAP 领域的 SQLite
要聊 DuckDB,我们先来看看 SQLite,其可以称得上世界上使用最多的关系型数据库系统,我们几乎在每台手机、每个浏览器和操作系统上都能找到它的身影,它甚至也在飞机上运行。
由于 SQLite 是嵌入式的,因此其不需要外部服务器管理。同时,他几乎绑定了每种语言,也正是基于这些特点,让其更容易使用,我们必须承认 SQLite 的伟大。但与此同时,其问题也突出。SQLite 是为 OLTP 而设计的,采用行存储,不能利用内存来加快计算速度,查询优化器非常有限,所以对于分析来说非常不友好。
正是基于此,DuckDB 看到了机会。简单来讲,它是用于分析 (OLAP 领域 [2] ) 的 SQLite,作为一个进程内数据库,它使开发人员、数据科学家、数据工程师和数据分析师能够使用纯 SQL 以极快的分析能力为它的代码提供支持。此外,它有能力在可能存在的地方分析数据,例如在笔记本电脑或云端。
DuckDB 使用了一个列式矢量化查询引擎,该引擎仍会解释查询,但会在一次操作中处理大量向量,由此减少传统系统 (如 PostgreSQL、MySQL 或 SQLite) 中按顺序处理每一行的开销,提升查询性能。
SQLite 是小型的关系型数据库,可用于进程内的部署。
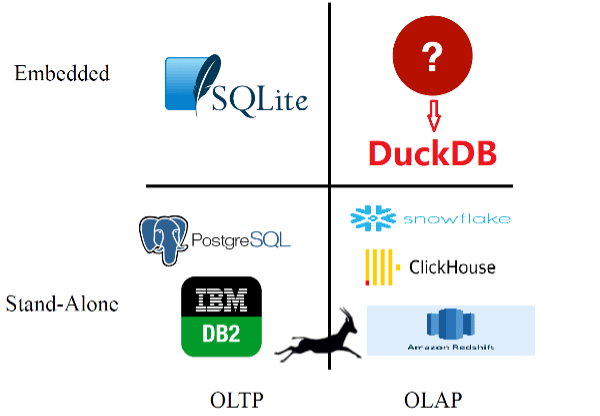
DuckDB 所处象限
认知:数据库行业的“非共识”
与行业大部分公司不同,MortherDuck 拥有不一样的行业信仰。
首先,Tigani 认为大多数客户和组织的数据存储适中,并不大。同时,客户数据大小服从幂律分布。最大客户的存储量是第二大客户的两倍,第三大客户的存储量是第二大客户的一半,依此类推。因此,虽然有客户拥有数百 PB 的数据,但大小很快就会下降。
其次,存算分离中存在存储偏差,数据大小增速快于计算。假如业务是静态的,既不增长也不收缩,数据随时间线性增长,但计算需求不会改变太多,因为大多数分析都是针对近期数据进行的。这种存算偏差,让我们可能根本不需要进行分布式处理。而且,很多用户希望他们的问题得到简单快速的答案 —— 他们不想等待云。
最后,大多数数据很少被查询。得到处理的数据中,有很大一部分不到 24 小时。到数据保存一周时,查询的可能性或许比最近一天低 20 倍。历史数据往往很少被查询,这也就意味着数据工作集大小比我们预期的易于管理。如果有一个包含 10 年数据的 PB 表,这些数据最后可能被压缩至不到 50 GB。所以,很多云厂商专注于 100TB 的查询性能,这可能不仅与大多用户无关,且会分散他们提供出色用户体验的能力。
因此,MortherDuck 提出了自己的观点,大数据是真实存在的,但大多数人可能不需要担心。“大数据”已死——现今我们最重要的事情不是担心数据大小,而是专注于我们将如何使用它来做出更好的决策。我们也会时常问自己,组织真的会生成大量数据吗?如果生成了,真的需要一次使用大量数据吗?如果需要,数据真的太大而无法放在一台机器上吗?也许不同的组织会给出不同的答案。
未来:没有“银弹”,没有万能的选择
我们目前所处的时代高速变化,产生了很多数据库管理系统。正如我们看到的情况,目前这个世界还没有万能的数据库管理系统。大家都会采取不同的权衡取舍,以更好地适应特定的用例,DuckDB 也是如此。有时我们需要侧重考虑为多个并发用户提供服务,有时我们也需要一个对单用户工作负载非常快的嵌入式数据库。
DuckDB 会成功吗?答案也许并不确定。不过我们确实看到了一个充满活力的开源社区正在形成,虽然还未有任何商业化的信息披露,但我们应有耐心给予这个 A 轮公司,毕竟故事才刚刚开始。
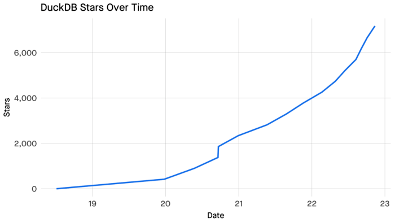
DuckDB 在 Github 的 star 数量变化
注释:
[1] OLTP:On-Line Transaction Processing 联机事务处理过程,也称为面向交易的处理过程。
[2] OLAP:Online Analytical Processing 联机分析处理。联机分析处理 OLAP 是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。
