剖析Buddy算法中内存的申请和释放 原创 精选
作者 |?赵青窕
审校 |?孙淑娟
内存的合理利用一直是系统的头等大事。目前系统中,除了采用Buddy和slab管理内存外,还会采用内存水线检测处理,PCP机制,CMA机制等进行内存的优化。在本文中,我们将从Buddy算法中内存的申请和释放,来探索内存的奥秘。
基本概念
zone:有的地方把zone称为管理区,每个node下会划分成不同的zone。有的系统会划分成3个zone区,有的会划分成2个zone区。zone区的个数会因平台,内核,系统的位数等有差异。
free_area:每个zone区根据2的order次方(order的范围从0到MAX_ORDER)进一步划分,划分后的每个小区域通过free_area[order]表示。
如下图红色方框中所示,按照红色方框从左到右分别是node,zone和free_area。

水线:每个zone存在三个水线,若当前zone中空闲页高于WMARK_HIGH,则当前zone区的空闲内存较多;若空闲页低于WMARK_LOW,则交换守护进程开始将内存交换到磁盘上;若空闲页低于WMARK_MIN,则内存回收系统还需要大量回收内存。
order:每个zone区根据order,把内存按照2的order继续划分为不同的area。
PCP链表:该链表中的每一个成员大小均是2的0次方个页面,每次申请和释放1个页面,都会优先考虑PCP。当PCP为空时,会从Buddy中申请;当PCP中页面比较多,超过限制时,会把页面释放到Buddy中。?
内存申请
比较常用的内存申请函数是kmalloc,当申请的内存大于KMALLOC_MAX_CACHE_SIZE时,会通过函数kmalloc_large从Buddy中申请内存,否则从slab中申请内存。本文中暂不分析从slab申请内存的情况。
kmalloc_large函数实现如下,Buddy算法中,内存的分配和释放均离不开order,我们可以看到,在该函数内部通过size来计算出对应的order,就很好地把Buddy和slab连接在一起了。
static __always_inline void *kmalloc_large(size_t size, gfp_t flags)
{
unsigned int order = get_order(size);
return kmalloc_order_trace(size, flags, order);
}
函数kmalloc_order_trace会调用函数alloc_pages,进而调用函数struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask)来实现内存的分配。实际上,Buddy提供的对外申请内存函数是alloc_pages,但其内部实现大部分情况下均是通过__alloc_pages_nodemask来实现。该函数分三步进行处理,分别如下:
- 构建内存分配的上下文结构,内核中采用结构体struct alloc_context来表示
- 快速分配
- 慢速分配
1.内存分配上下文结构
内存分析上下文采用结构体struct alloc_context来表示,其结构体定义如下:
/*
* Structure for holding the mostly immutable allocation parameters passed
* between functions involved in allocations, including the alloc_pages*
* family of functions.
*
* nodemask, migratetype and high_zoneidx are initialized only once in
* __alloc_pages_nodemask() and then never change.
*
* zonelist, preferred_zone and classzone_idx are set first in
* __alloc_pages_nodemask() for the fast path, and might be later changed
* in __alloc_pages_slowpath(). All other functions pass the whole strucure
* by a const pointer.
*/
struct alloc_context {
struct zonelist *zonelist;
nodemask_t *nodemask;
struct zoneref *preferred_zoneref;
int migratetype;
enum zone_type high_zoneidx;
bool spread_dirty_pages;
};
各个成员含义如下:
- zonelist:用于分配内存的zone区列链表。在内存分配时,内核会通过函数numa_node_id()来获取当前CPU的NUMA ID,进而根据这个ID号获取对应的zonelist。内存的分配实际上就是在zonelist找合适的内存进行分配,该成员在后面两步中具有关键作用;
- nodemask:用来指定从哪一个node中进行内存分配。若没有指定,则会在所有节点中尝试分配,通常情况下该值为NULL;
- high_zoneidx:该成员从字面意思看就是最高的zone区id号,其实它表示的是在分配时,所能分配的最高zone区。通常一般是从HIGH区---->NORMAL---->DMA的方式进行分配。内存的需求方在请求进行内存分配时,会通过gfp_mask来对该成员进行设置,Buddy在内存分配及逆行内存分配时需要通过函数gfp_zone(gfp_mask)来提取gfp_mask中对应的high_zoneidx;
- migratetype:该成员指明了需要内存的页面迁移类型。Buddy进行内存分配时需要通过函数gfpflags_to_migratetype(gfp_mask)来获取内存请求方的具体需求;
- preferred_zone:结合成员high_zoneidx和zonelist,计算出首先从那个zone区开始进行内存的分配,即第一个将要被遍历的zone,内核中是通过函数first_zones_zonelist来计算该成员的;
- spread_dirty_pages:当申请内存时,采用了标志__GFP_WRITE,则说明此次申请的物理页面将会生成脏页,内核中就是通过语句ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE)来设置该成员的。
从上面的结构体struct alloc_context的说明可以看出,该结构体具体细化了内存分配的各种需求,其具体实现如下图中红色方框所示:
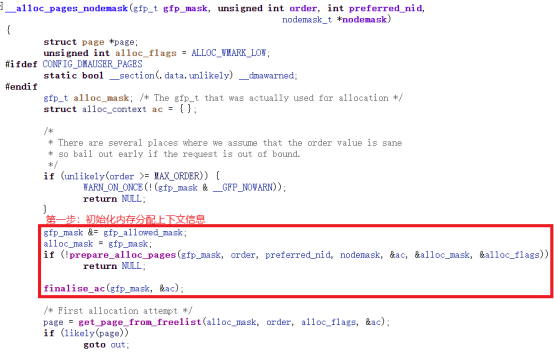
2.快速分配
在完成第一步后,就可以通过函数get_page_from_freelist进行一次快速分配。该函数才是内存分配真正的开始位置,接下来我将详细说明该过程,为了简化描述,同时为了让大家容易理解,暂时不考虑CPUSET的情况。
该函数本质就是从preferred_zone开始,遍历zonelist,其每一次遍历时,处理流程如下:
- 脏页面判断
每个node节点会对脏页数进行限制,当超过限制后,将无法申请具有__GFP_WRITE标志的内存块,需要跳出当前zone区,转而扫描下一个zone区,其内核处理代码如下图所示,图中进行了标注,方便大家理解。

- 水位处理
前面小节中有提到每个zone中存在三个水线,在内存申请时,默认采用WMARK_LOW,使用函数zone_watermark_fast进行水线判断。
假如通过水线检测,发现内存不够,则会判断当前申请内存的请求是否采用ALLOC_NO_WATERMARKS,若采用,则说明当前剩余内存多少与当前申请没有任何关系,会调用rmqueue进行内存分配;若没有ALLOC_NO_WATERMARKS声明,则进行下一步reclaim操作;
假如通过水线检测,发现当前还有足够内存,则调用函数rmqueue进行内存分配。
- reclaim操作
reclaim操作首先是通过函数zone_allows_reclaim来判断当前的node是否支撑reclaim操作,如果不支持,就退出当前循环,执行下一个循环操作;若支持,就调用node_reclaim执行内存回收的工作。
当函数node_reclaim返回值是NODE_RECLAIM_NOSCAN或者NODE_RECLAIM_FULL时,表示当前虽然内存不够,但我无能为力了。这种情况下,只能退出循环,执行下一个操作;当返回值是其余的情况时,就会重新进行水位检测,若此时内存足够,则调用rmqueue进行内存分配,否则退出循环,执行下一个循环操作。
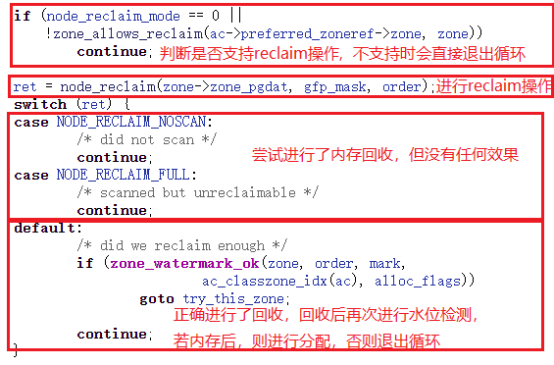
假如当前系统使用的是非NUMA,则不会进行reclaim操作,当水位线检测发现内存不够时,会跳出循环,尝试下一个zone;假如当前系统是NUMA,才会进行上述描述中的判断,来决定是否进行内存回收。
- rmqueue内存分配处理
在内存分配时,分两种情况进行处理,分别是order?= 0及order != 0。
当order = 0时,会首先从PCP链表中进行内存申请,其具体流程如下:
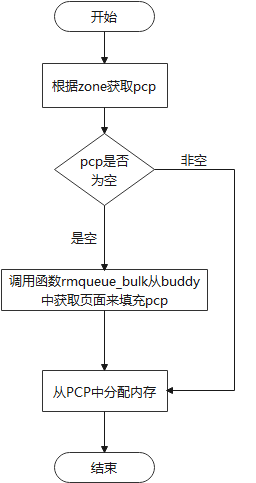
当order != 0,即要申请多页,下面是其处理过程,根据实际情况调用__rmqueue_smallest,__rmqueue_cma或者__rmqueue进行内存的分配。

对于设置了ALLOC_HARDER的情况,先尝试通过函数__rmqueue_smallest来分配MIGRATE_HIGHATOMIC类型的内存块,具体实现就是从zone->free_area[order]中根据需要的内存类型进行分配。该函数实现比较简单,就是遍历free_area以便找到合适的内存块,下图是__rmqueue_smallest的实现,增加了注释方便大家理解。
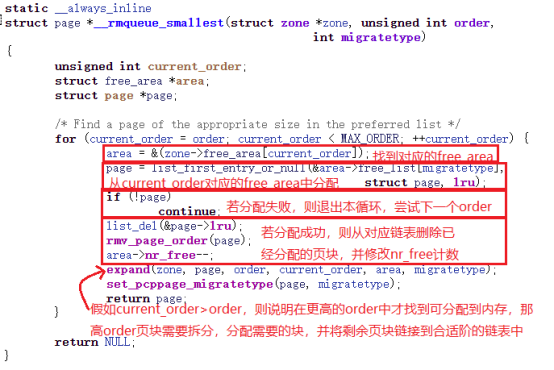
假如通过上面的__rmqueue_smallest没有找到合适的内存块,在申请内存时,使用标志__GFP_CMA申请的MIGRATE_MOVABLE,则再次使用函数__rmqueue_cma申请内存,实际上__rmqueue_cma内部是调用__rmqueue_smallest(zone, order, MIGRATE_CMA)实现的。
若上面的两步__rmqueue_smallest,__rmqueue_cma均失败,则会调用__rmqueue。该函数内部实际上也是通过__rmqueue_smallest实现的,当__rmqueue_smallest只会从指定的migtatetype中进行分配,当分配失败后,会通过函数__rmqueue_fallback从后备fallbacks中找到一个迁移类型页块,将其迁移到目标迁移类型中后重新进行分配。

至此快速分配结束,若已经分配到内存,则会退出分配流程,否则进行下一步操作:慢速分配。
3.慢速分配
慢速分配是通过函数__alloc_pages_slowpath来实现的。从快速分配发现无法分配到需要的内存,紧接着内核通过慢速分配对内存进行整理,尝试找到合适的内存。其整理过程包含:
- 重新计算内存分配上下文;
- 如果设置了__GFP_KSWAPD_RECLAIM,则会调用函数wake_all_kswapds来唤醒负责换出内存页的守护进程kswapds;
- 因更新了内存分配上下文,因此再次使用快速分配尝试内存分配。若分配成功,则退出本次分配;否则继续进行下一步操作;
- 若申请内存时,设置了__GFP_DIRECT_RECLAIM,且非pfmemalloc情况下,会通过函数__alloc_pages_direct_compact进行内存压缩后,再次尝试分配页面。若分配成功则退出;否则进入下一步;
- 接下来的操作代码中采用了retry代码标签,这个过程比较繁琐,其本质就是采用各种内存优化手段尽量促使本次分配成功,优化手段主要有以下四种:
- 通过函数__alloc_pages_direct_reclaim尝试进行内存回收后,再分配内存;
- 通过函数__alloc_pages_direct_compact尝试进行内存整合后,再分配内存;
- 通过函数__alloc_pages_may_oom尝试杀掉一些优先级不高的进程后,再分配内存;
- 在retry过程中,仍会调用wake_all_kswapds来唤醒kswapds,防止意外休眠。
这四种方式都会伴随着调用函数get_page_from_freelist来进行内存分配。
至此内存分配函数就完成了。从上面的描述可以看出,当内存足够时,通常情况下快速分配就足够了。只有在内存不够时,会进行慢速分配,慢速分配里面进行内存回收,整理等操作后再进行分配。若此时还没有足够的内存可以分配,说明内存耗尽,可能是因为内存泄漏导致内存不足,这个时候就需要去定位内存泄漏问题了。
内存释放
Buddy中内存释放入口函数是free_pages。该函数的实现如下,从下面的函数中可以看出最后是通过free_unref_page或者__free_pages_ok来实现的,其余的部分均合法性判断。
void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
VM_BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page))
free_the_page(page, order);
}
static inline void free_the_page(struct page *page, unsigned int order)
{
if (order == 0) /* Via pcp? */
free_unref_page(page);
else
__free_pages_ok(page, order);
}
函数free_pages 接受两个参数,分别是虚拟地址和需要释放的页面数,该函数内部利用virt_to_page把虚拟地址转化成Buddy算法需要的struct page结构体。
__free_pages函数先将对应的struct page->_refcount?减去1,之后检测_refcount是否为0,若为0,继续进行释放操作,否则不进行内存释放操作。通过该函数__free_pages可以看到,不管是否进行了内存释放操作,该函数都可以正常退出且没有返回值。假如内存释放操作异常,就会引发内存泄漏问题,且代码中没有任何日志和错误码,这种泄漏通常很难排查。
free_the_page是真正的内存释放函数,该函数根据order的不同,分别进行两种不同的处理:
- order为0的情况
- order不为0的情况
接下来我们分别来了解这两种情况的处理方式。
1.order为0的情况
函数内存会根据order是否为0来进行相应的操作,对于order = 0的情况,此处是调用函数free_unref_page。有些内核中会调用函数free_hot_cold_page(page, false)来实现,但不管调用哪一个函数,其内部均是进行相应的判断后,通过把page插入PCP链表相应位置处实现。实际上内核在把内存释放到PCP链表时,会进行PCP链表成员个数pcp->count的判断,当pcp->count >= pcp->high时,会调用函数free_pcppages_bulk释放一部分PCP中的页面到 Buddy 子系统中。
此处我们需要注意,并不是所有order = 0的内存全部释放到PCP链表中,在结构体struct page中有个成员index,该成员指明了该部分内存的类型,若类型为MIGRATE_ISOLATE,则其内存(实际上是一个页面)会释放到Buddy中,若类型对应的数据大于或等于MIGRATE_PCPTYPES,则释放到类型为MIGRATE_MOVABLE的PCP链表中,其余的释放到对应类型的PCP链表中。下图是order?= 0时的核心处理代码,图中已经标注了各个关键地方,供大家参考。

2.order不为0的情况
当order不为0时,会通过函数__free_pages_ok调用free_one_page来实现。其核心代码如下图所示,图中对代码进行了标注,从其代码我们可以发现其实现是通过while循环来查找可以合并的页块,查找的方式就是按照order的次序挨个查找,其整个流程就是查找--->确认--->删除--->合并。
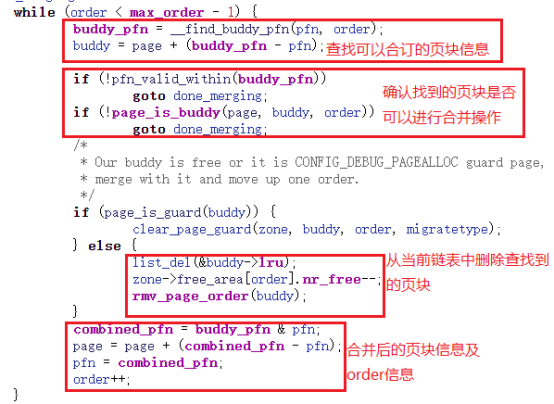
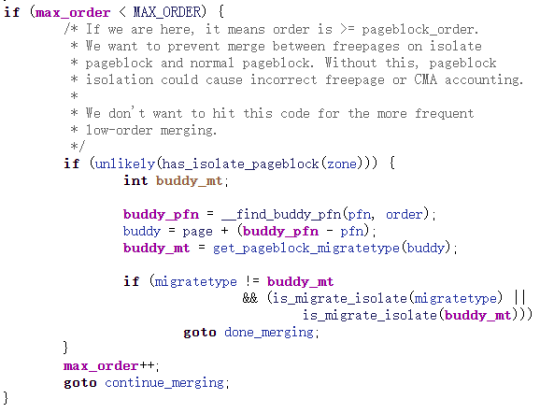
此时,我们来思考一个问题,有些特殊内存区是无法进行合并的,在内核代码中特别表明了如下注释:
/* If we are here, it means order is >= pageblock_order.
* We want to prevent merge between freepages on isolate
* pageblock and normal pageblock. Without this, pageblock
* isolation could cause incorrect freepage or CMA accounting.
*
* We don't want to hit this code for the more frequent
* low-order merging.
*/
其对应的代码处理如下图所示,其代码主要目的有两点,其一是保证可以充分地进行页块的合并,从而尽量减少内存碎片化;其二是保证特殊用途的内存块不受影响。
最后根据实际情况,通过函数list_add(&page->lru, &zone->free_area[order].free_list[migratetype])或者函数list_add_tail(&page->lru,&zone->free_area[order].free_list[migratetype])把合并后的page添加到对应的链表中。
总结
不同平台,不同内核版本的系统,在内存处理上或许会存在或多或少的差异,但其核心思想是相同的。通过本文,我们可以详细地了解Buddy中内存申请和释放的处理方式,以及当内存不足时,Buddy是如何处理的。
作者介绍
赵青窕,51CTO社区编辑,从事多年驱动开发。研究兴趣包含安全OS和网络安全领域,发表过网络相关专利。
