揭开云原生数据管理的神秘面纱:操作层级 译文 精选
作者 | Gaurav Rishi
译者 | 张锋
审校 | Noe
随着应用容器化的速度加快,Day2服务已经成为一个迫在眉睫的问题。这些Day2服务包括数据管理功能,如备份和灾难恢复以及应用程序迁移。在这个云原生应用容器化的新世界中,微服务通常部署在多个位置(区域、云、本地),同时使用多种数据服务(MongoDB、Redis、Kafka等)和存储技术来存储这些应用状态。
在这种环境中,传统基础设施或基于虚拟机管理程序的解决方案将很难发挥作用,那么为云原生应用设计和实施这些数据管理功能的正确架构是什么呢?你应该如何分析存储供应商、数据服务供应商和云供应商提供的各种数据管理选项来确定适合你环境和需求的正确方法呢?本文深入探讨了各种数据管理方法在一致性、存储要求和性能等多个属性上的优缺点。
定义一个词汇
首先,我们将解构和简化技术栈以显示数据可能在云原生应用中的位置。
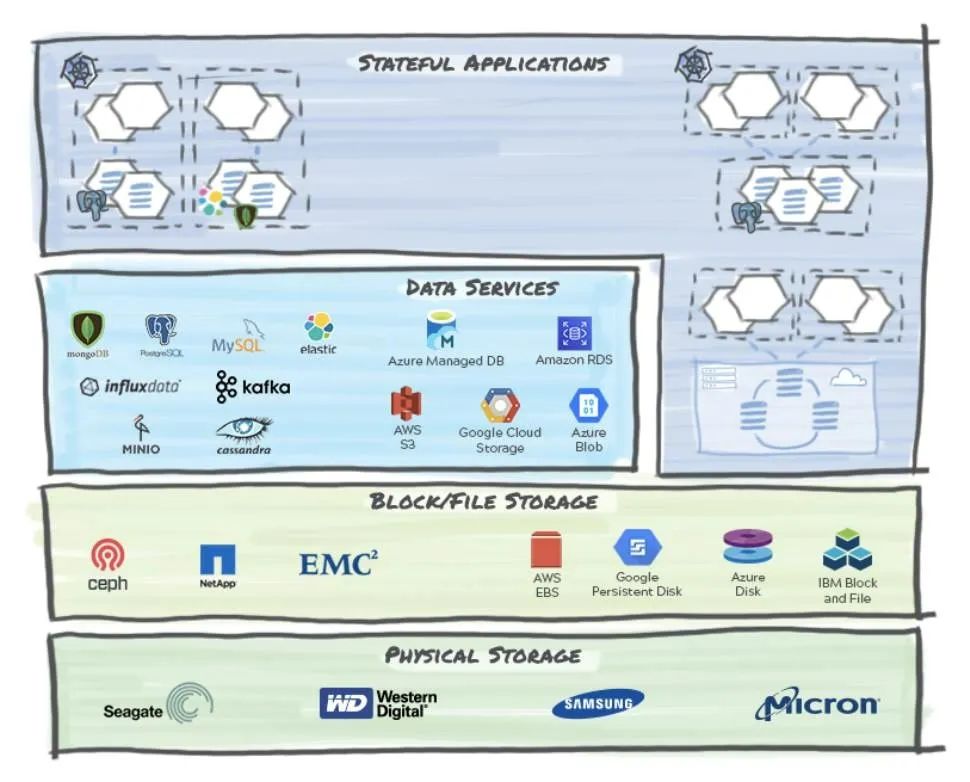
在考虑数据管理时,我们可以在上图中显示的一个(或多个)层上进行操作。让我们列举这些层:
1、物理存储
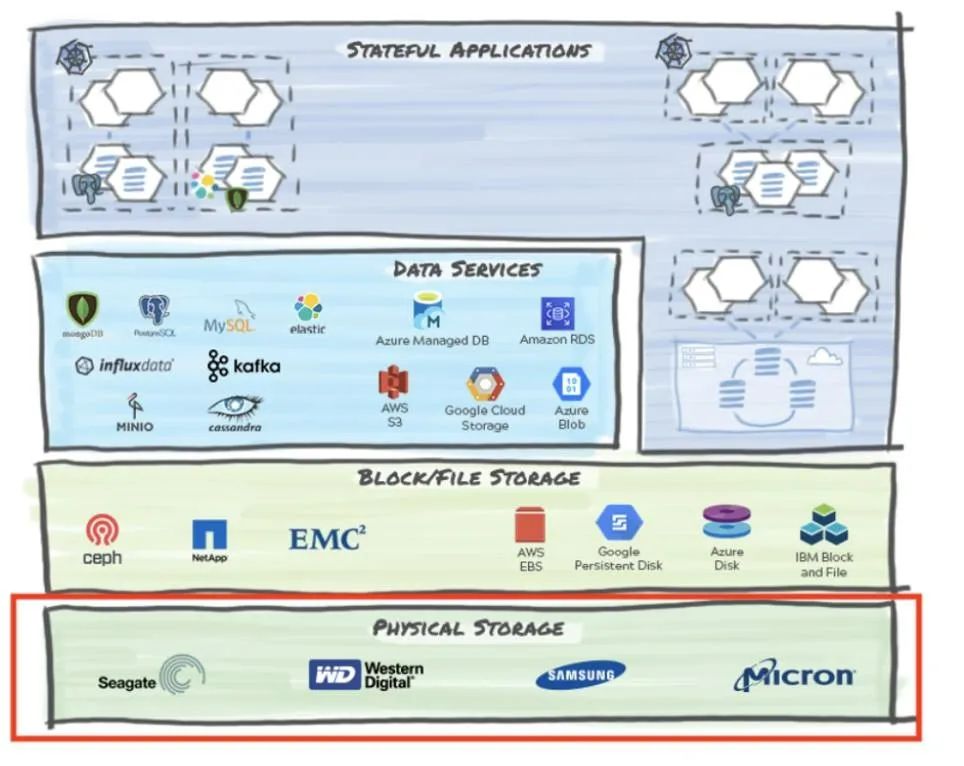
该层包括各种存储硬件选型,可以将状态存储在非易失性存储器中,并可选择从NVMe和SSD设备到旋转型磁盘甚至磁带的物理介质。它们有不同的外形尺寸,包括阵列和独立机架服务器。
物理存储可以位于:
- 在本地,你可能会遇到来自希捷、西部数据和美光等供应商的存储硬件。
- 在托管云提供商的数据中心中。虽然你可能永远不会接触物理设备,但你知道它是云的基础架构一部分。
2、文件和块存储
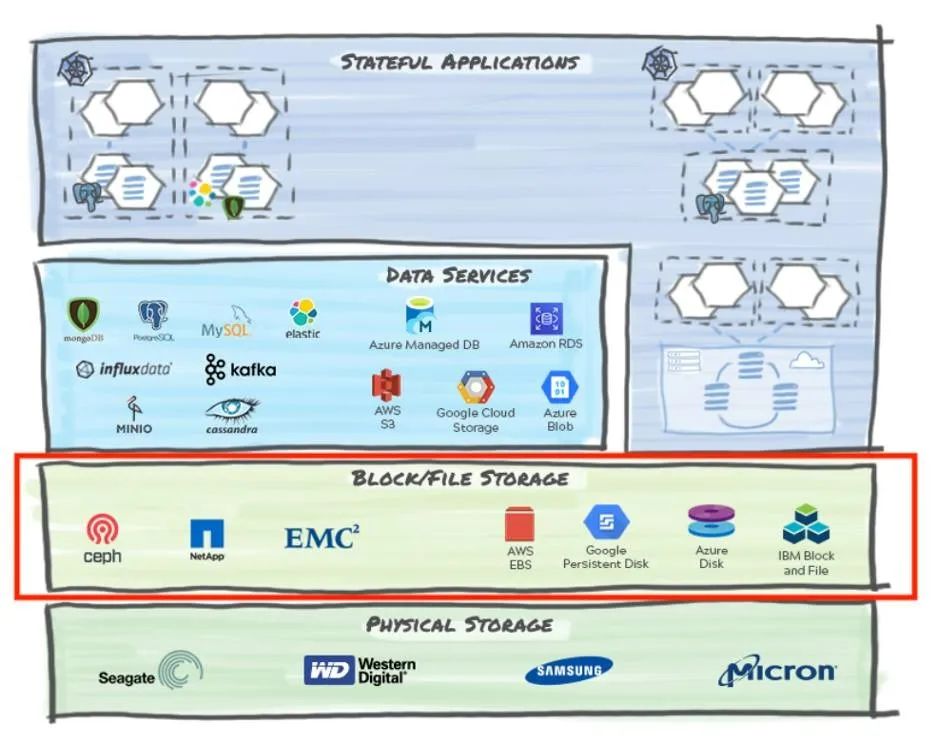
? ? ? ?该软件层提供文件或块级结构,以实现从底层物理存储进行高效的读写操作。在文件和块这两种情况下,底层存储可以是独立的(本地磁盘)或共享的网络资源(NAS 或 SAN)。
- ? ? ? ?块存储允许你从本地或远程磁盘创建具有低延迟并可通过iSCSI和FiberChannel等协议访问的原始存储卷。云供应商上的块存储实现包括Amazon EBS和GCE 持久性磁盘。
- ? ? ? ?文件存储使用NFS和SMB等协议为文件语义和操作提供共享存储。本地常见的文件存储实现包括来自NetApp和Dell EMC的产品。云供应商上的文件存储实现包括 Amazon EFS、Google Cloud Filestore和Azure Files。
? ? ? ?这一层通常提供快照功能,按照时间点创建卷的副本来进行保护。此外,在 Kubernetes 环境中,该层提供容器存储接口 (CSI) 驱动程序来规范化API,让上层可以使用这些API来调用快照功能。请注意,就所支持的功能而言,并非所有CSI实现都是相同的。
3、数据服务
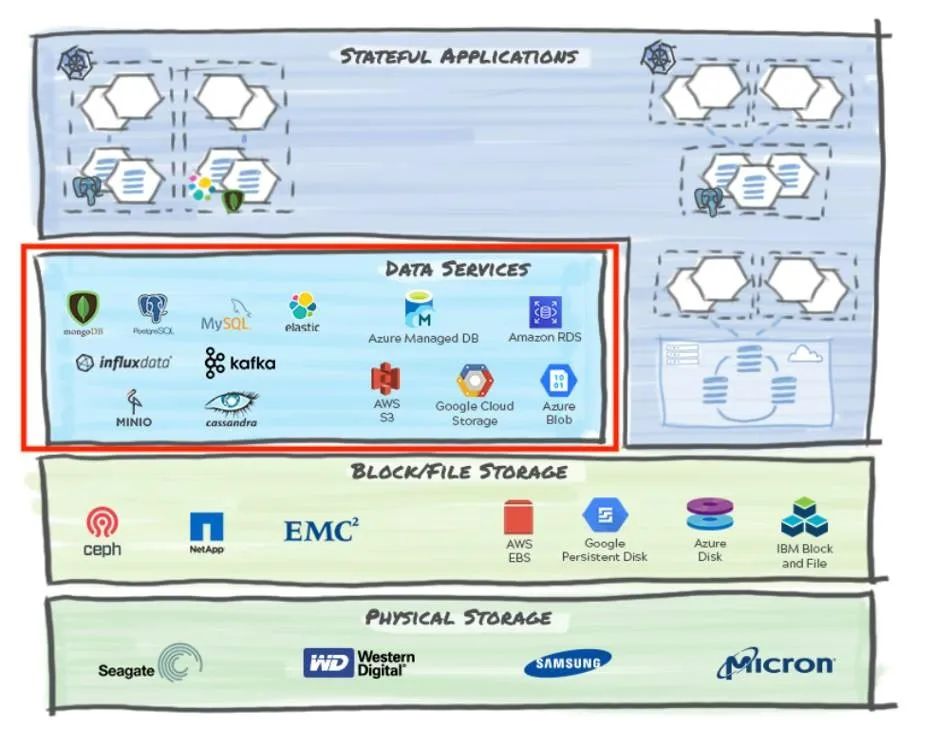
? ? ? ?这一层位于文件/块存储实现之上。它提供了各种数据库实现以及日益流行的存储类型,即对象(又名 blob)存储。该层通常与应用程序进行交互,底层数据库实现基于工作负载和业务逻辑来选择。对于基于微服务的应用程序,多语言持久性是一种规范,因为每个微服务都会为当前的工作选择最合适的数据服务。
一些数据库类型和示例实现的子集包括:
- SQL数据库:MySQL、PostgreSQL、SQL Server
- NoSQL数据库:
- 键值存储:Redis、BerkeleyDB
- 时间序列数据库:InfluxDB 、Prometheus
- 图数据库:Neo4j、 GraphDB
- 宽列存储:Cassandra、Azure Cosmos
- 文档存储:MongoDB、CouchDB
- 消息队列:Kafka、RabbitMQ、Amazon SQS
- 对象存储1:Amazon S3、Google Cloud Storage、Minio
? ? ? ?这些数据库还有几个托管实例,称为数据库即服务 (DBaaS) 系统。这些通常包括上面列出的数据库类别之一,有时可以提供自动扩展,同时满足即服务 ( -aaS ) 业务的消费经济。DBaaS系统的示例包括 Amazon RDS、MongoDB Atlas和Azure SQL。
? ? ? ?从数据保护的角度来看,每个数据库实现都提供了一组特定的实用程序( PostgreSQL的pg_dump或WAL-E,MongoDB的mongodump等)来备份和恢复数据。值得注意的是,在一致性、恢复颗粒度和速度方面,许多实用程序具有不同的功能。无论它们是作为独立实用程序提供还是作为即服务产品的一部分提供,通常仅限于特定的数据库实现,或者至多是一种数据库类型。
4、有状态应用
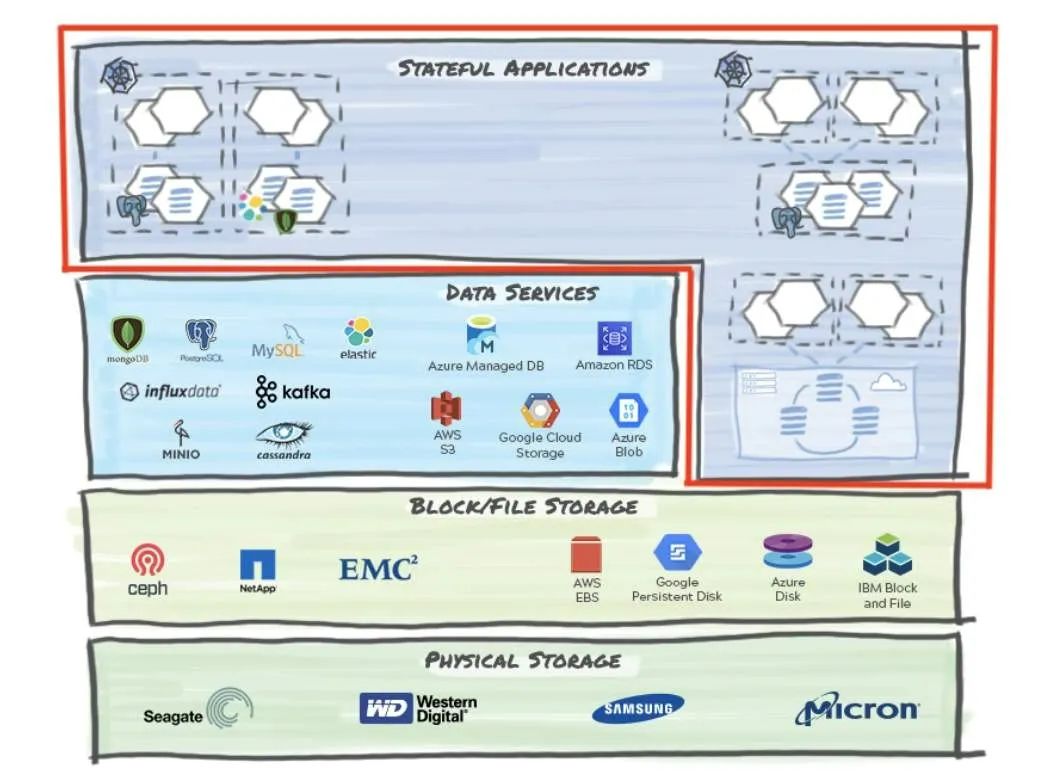
? ? ? ?应用程序层是业务逻辑所在的地方,在云原生世界中,应用程序通常基于现代敏捷开发并作为分布式微服务实现。几乎所有应用程序都有一个需要持久化的状态。虽然有多种存储应用程序状态的模式,但我们需要在有状态的 Kubernetes 应用程序的上下文中将以下信息作为一个原子单元来持久化和保护:
- 应用程序数据:跨各种数据服务、块和文件存储实现分布在多个容器上。
- 应用程序定义和配置:应用程序镜像和相关的环境配置分布在各种 Kubernetes 对象中,包括ConfigMaps、Secrets等。
- 其他配置状态:包括CI/CD流水线状态、发布信息和关联的Helm部署元数据。
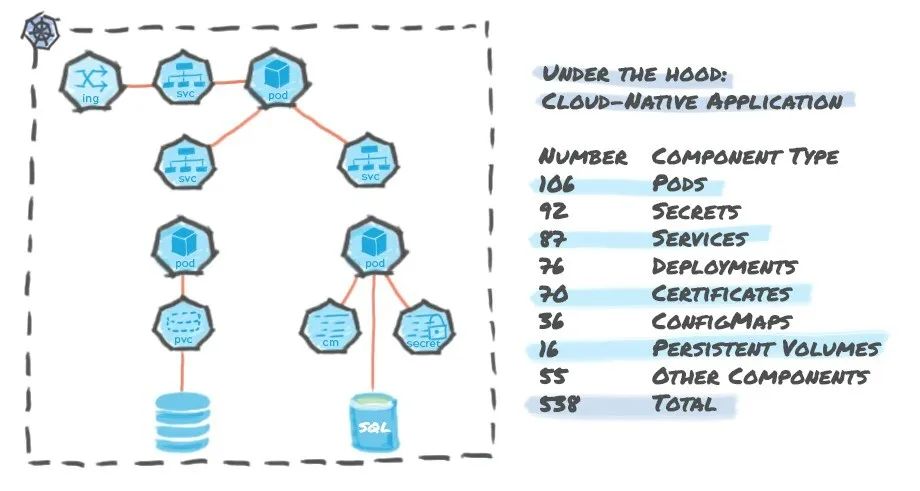
上图为一个有状态应用程序的示例,它突出显示了一些需要保护的组件和相关状态。需要注意的是,对于实际部署,应用程序由数百个这样的底层组件组成。此外,在云原生架构中,保护的原子性单元需要是应用程序与底层数据服务或存储基础设施层。如前所述,这是因为应用程序的状态包括分布在多个物理或虚拟节点和数据服务中的应用程序数据、定义和配置。
结论
从备份/恢复和应用程序可移植性的角度来看,一个好的数据管理解决方案需要将整个应用程序视为原子性单元,这使得传统以管理程序为中心的解决方案不再适用。我们还展示了一个简单的技术栈图,从各种数据服务、块和文件存储以及跨本地和云实现物理存储的角度显示应用程序状态实际所在的位置。这定义了一个基本范畴,使我们能够深入了解云数据管理的操作层级。
附注
有些人可能争辩认为对象存储应该与文件/块属于同一层。在本文中,对象存储将被视为另一种具有键值接口的数据服务,如果需要,可以在Kubernetes中运行。
原文链接:https://dzone.com/articles/demystifying-cloud-native-data-management-layers-of-operation
译者介绍
张锋,51CTO社区编辑,长期从事技术顾问工作,专注于运维/云原生领域,精通网络疑难故障分析,有很丰富的大型银行运维工具建设实践经验。
