监督学习有哪些常见算法?都是如何应用的 译文
?什么是监督学习?
监督学习是机器学习的子集,监督学习会对机器学习模型的输入数据进行标记,并对其进行练习。因此,监督模型能最大限度地预测模型的输出结果。
监督学习背后的概念也可以从现实生活中找到影子,例如老师给孩子做辅导。假设老师要教孩子认识猫、狗的图像。她/他将通过不断地向孩子展示猫或狗的图像来辅导孩子,同时告知孩子图像是狗还是猫。
展示和告知图像的过程可以被认为是标记数据,机器学习模型训练过程中,会被告知哪些数据属于哪个类别。
监督学习有什么用?监督学习可用于回归和分类问题。分类模型允许算法确定给定数据属于哪个组别。示例可能包括 True/False、Dog/Cat 等。
由于回归模型能够根据历史数据预测将来的数值,因此它会被用于预测员工的工资或房地产的售价。
在本文中,我们将列出一些用于监督学习的常见算法,以及关于此类算法的实用教程。
线性回归
线性回归是一种监督学习算法,它根据给定的输入值预测输出值。当目标(输出)变量返回一个连续值时,使用线性回归。
线性算法主要有两种类型,简单线性回归和多元线性回归。
简单线性回归仅使用一个独立(输入)变量。一个例子是通过给定的身高来预测孩子的年龄。
另一方面,多元线性回归可以使用多个自变量来预测其最终结果。一个例子是根据它的位置、大小、需求等来预测给定房产的价格。
以下是线性回归公式
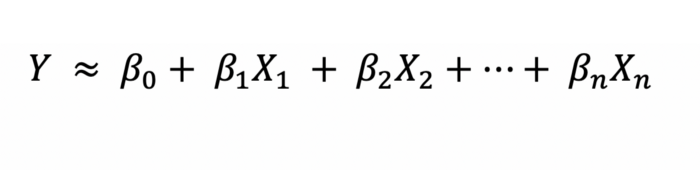
对于 Python的示例,我们将使用线性回归来预测相对于给定 x 值的 y 值。
我们给定的数据集仅包含两列:x 和 y。请注意,y 结果将返回连续值。
下面是给定数据集的截图:

使用 Python 的线性回归模型示例
1.导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns from sklearn
import linear_model from sklearn.model_selection
import train_test_split import os
2. 读取和采样我们的数据集
为了简化数据集,我们抽取了 50 个数据行的样本,并将数据值四舍五入为 2 个有效数字。
请注意,您应该在完成此步骤之前导入给定的数据集。
df = pd.read_csv("../input/random-linear-regression/train.csv")
df=df.sample(50) df=round(df,2)3. 过滤?Null 和 Infinite 值
如果数据集包含空值和无限值,则可能会出现错误。因此,我们将使用 clean_dataset 函数来清理这些值的数据集。
def clean_dataset(df):
assert isinstance(df, pd.DataFrame), "df needs to be a pd.DataFrame"
df.dropna(inplace=True)
indices_to_keep = ~df.isin([np.nan, np.inf, -np.inf]).any(1)
return df[indices_to_keep].astype(np.float64)
df=clean_dataset(df)
4. 选择我们依赖和独立的价值观
请注意,我们将数据转换为???DataFrame 格式。??dataframe 数据类型是一种二维结构,可将我们的数据对齐到行和列中。
5. 拆分数据集
我们将数据集划分为训练和测试部分。选择测试数据集大小为总数据集的 20%。
请注意,通过设置 random_state=1,每次模型运行时,都会发生相同的数据拆分,从而产生完全相同的训练和测试数据集。
这在您想进一步调整模型的情况下很有用。
x_train, ?x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=1)
6.建立线性回归模型
使用导入的线性回归模型,我们可以在模型中自由使用线性回归算法,绕过我们为给定模型获得的 x 和 y 训练变量。
lm=linear_model.LinearRegression() lm.fit(x_train,y_train)
7. 以分散的方式绘制我们的数据
df.plot(kind="scatter", x="x", y="y")
8. 绘制我们的线性回归线
plt.plot(X,lm.predict(X), color="red")
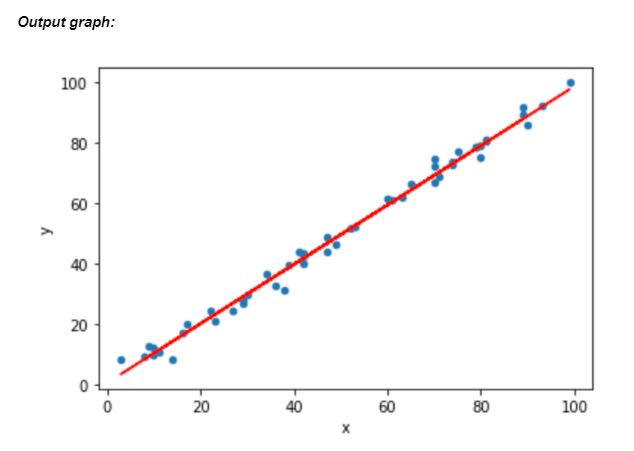
蓝点表示数据点,而红线是模型绘制的最佳拟合线性回归线。线性模型算法总是会尝试绘制最佳拟合线以尽可能准确地预测结果。
逻辑回归
与线性回归类似,??逻辑回归??根据输入变量预测输出值,两种算法的主要区别在于逻辑回归算法的输出是分类(离散)变量。
对于?Python的示例,会使用逻辑回归将“花”分成两个不同的类别/种类。在给定的数据集中会包括不同花的多个特征。
模型的目的是将给花识别为Iris-setosa、Iris-versicolor或?Iris-virginica 几个种类。
下面是给定数据集的截图:
使用 Python 的逻辑回归模型示例
1.导入必要的库
import numpy as np
import pandas as pd from sklearn.model_selection
import train_test_split import warnings warnings.filterwarnings('ignore')
2. 导入数据集
data = pd.read_csv('../input/iris-dataset-logistic-regression/iris.csv')3. 选择我们依赖和独立的价值观
对于独立 value(x) ,将包括除类型列之外的所有可用列。至于我们的可靠值(y),将只包括类型列。
X = data[['x0','x1','x2','x3','x4']]
y = data[['type']]
4. 拆分数据集
将数据集分成两部分,80% 用于训练数据集,20% 用于测试数据集。
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=0.2, random_state=1)
5. 运行逻辑回归模型
从 linear_model 库中导入整个逻辑回归算法。然后我们可以将 X 和 y 训练数据拟合到逻辑模型中。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state = 0)
model.fit(X_train, y_train)
6. 评估我们模型的性能
print(lm.score(x_test, y_test))
返回值为0.9845128775509371,这表明我们模型的高性能。
请注意,随着测试分数的增加,模型的性能也会增加。
7. 绘制图表
import matplotlib.pyplot as plt %matplotlib inline
plt.plot(range(len(X_test)), pred,'o',c='r')
输出图:
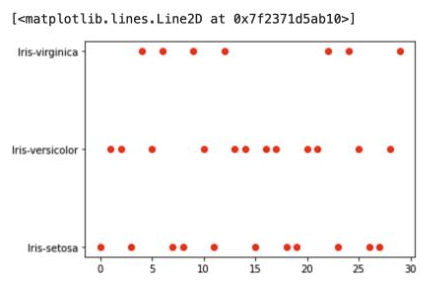
在逻辑图中,红点表示给定的数据点。这些点清楚地分为 3 类,Virginica、versicolor 和 setosa 花种。
使用这种技术,逻辑回归模型可以根据花在图表上的位置轻松对花类型进行分类。
支持向量机
??支持向量机??(?SVM) 算法是另一个著名的监督机器学习模型,由 Vladimir Vapnik 创建,它能够解决分类和回归问题。实际上它更多地被用到解决分类问题。
SVM 算法能够将给定的数据点分成不同的组。算法在绘制出数据之后,可以绘制最合适的线将数据分成多个类别,从而分析数据之间的关系。
如下图所示,绘制的线将数据集完美地分成 2 个不同的组,蓝色和绿色。
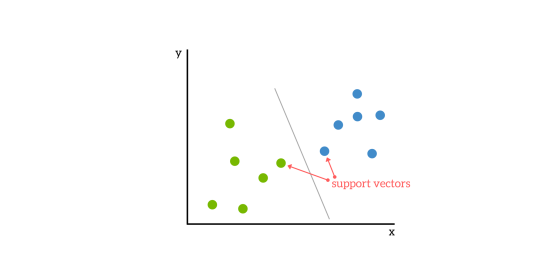
SVM 模型可以根据图形的维度绘制直线或超平面。行只能用于二维数据集,这意味着只有 2 列的数据集。
如果是多个特征来预测数据集,就需要更高的维度。在数据集超过 2 维的情况下,支持向量机模型将绘制超平面。
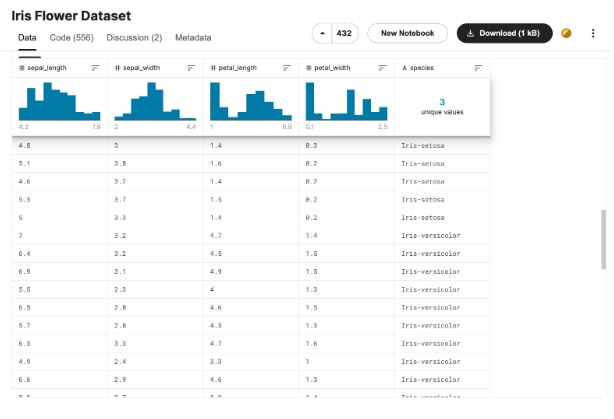
在支持向量机 Python 的示例中,将对 3 种不同的花卉类型进行物种分类。我们的自变量包括花的所有特征,而因变量是花所属物种。
花卉品种包括Iris-setosa、?Iris-versicolor和Iris-virginica。
下面是数据集的截图:
使用 Python 的支持向量机模型示例
1.导入必要的库
import numpy as np
import pandas as pd from sklearn.model_selection
import train_test_split from sklearn.datasets
import load_iris
2. 读取给定的数据集
请注意,在执行此步骤之前,应该导入数据集。
data = pd.read_csv(‘../input/iris-flower-dataset/IRIS.csv’)
3. 将数据列拆分为因变量和自变量
将 X 值作为自变量,其中包含除物种列之外的所有列。
因变量y仅包含模型预测的物种列。
X = data.drop(‘species’, axis=1) y = data[‘species’]
4. 将数据集拆分为训练和测试数据集
将数据集分为两部分,其中我们将 80% 的数据放入训练数据集中,将 20% 放入测试数据集中。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
5.导入SVM并运行模型
导入了支持向量机算法。然后,使用上面步骤中收到的 X 和 y 训练数据集运行它。
from sklearn.svm import SVC
model = SVC( )
model.fit(X_train, y_train)
6. 测试模型的性能
model.score(X_test, y_test)
为了评估模型的性能,将使用 score 函数。在第四步中创建的 X 和 y 测试值输入到 score 方法中。
返回值为0.9666666666667,这表明模型的高性能。
请注意,随着测试分数的增加,模型的性能也会增加。
其他流行的监督机器学习算法
虽然线性、逻辑和 SVM 算法非常可靠,但还会提到一些有监督的机器学习算法。
1. 决策树
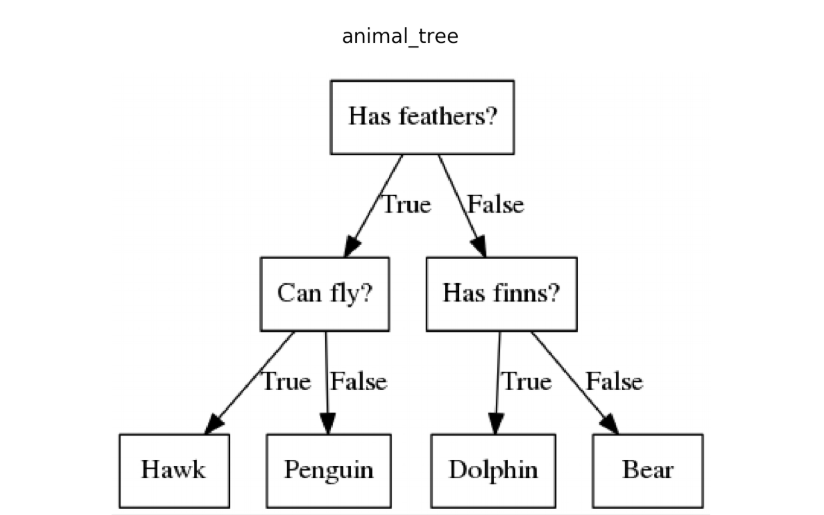
??决策树算法??是一种有监督的机器学习模型,它利用树状结构进行决策。决策树通常用于分类问题,其中模型可以决定数据集中给定项目所属的组。
请注意,使用的树格式是倒置树的格式。
2. 随机森林
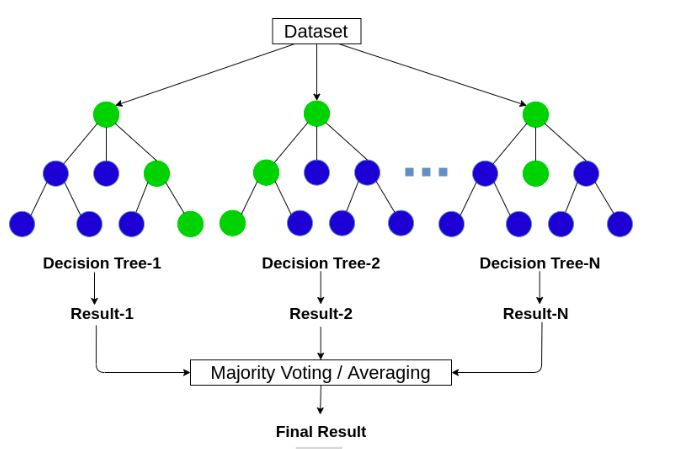
被认为是一种更复杂的算法,???随机森林算法??通过构建大量决策树来实现其最终目标。
意味着同时构建多个决策树,每个决策树都返回自己的结果,然后将其组合以获得更好的结果。
对于分类问题,随机森林模型将生成多个决策树,并根据大多数树预测的分类组对给定对象进行分类。
模型可以修复由单个树引起的过拟合问题。同时,随机森林算法也可用于回归,尽管可能导致不良结果。
3. k-最近邻
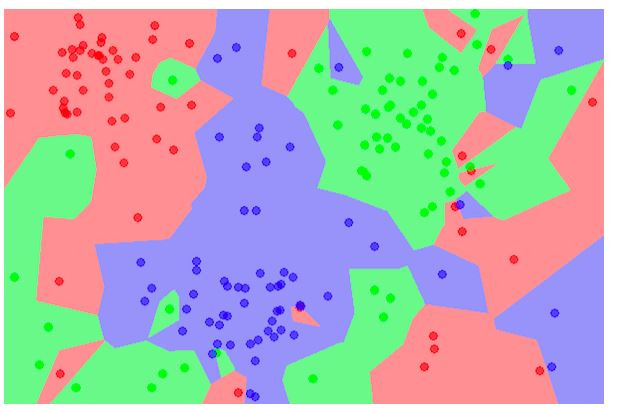
k最近??邻??(KNN) 算法是一种监督机器学习方法,它将所有给定数据分组到单独的组中。
这种分组基于不同个体之间的共同特征。KNN 算法可用于分类和回归问题。
KNN 的经典示例就是将动物图像分类到不同的组集中。
总结
本文介绍了监督机器学习及其可以解决的两类问题,并解释了分类和回归问题,给出了每个输出数据类型的一些示例。
详细解释了线性回归是什么以及它是如何工作的,并提供了一个 Python 中的具体示例,它会根据独立的 X 变量预测 Y 值。
随后又介绍了逻辑回归模型,并给出了分类模型示例,该示例将给定的图像分类为具体花的种类。
对于支持向量机算法,可以用它来预测 3 种不同花种的给定花种。最后列出了其他著名的监督机器学习算法,例如决策树、随机森林和 K 近邻算法。
无论您是为了学习、工作还是娱乐阅读本文,我们认为了解这些算法是开始进入机器学习领域的一个开端。
如果您有兴趣并想了解更多关于机器学习领域的信息,我们建议您深入研究此类算法的工作原理以及如何调整此类模型以进一步提高其性能。
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。曾任惠普技术专家。乐于分享,撰写了很多热门技术文章,阅读量超过60万。??《分布式架构原理与实践》??作者。
原文标题:?Primary Supervised Learning Algorithms Used in Machine Learning?,作者:Kevin Vu
?
?
