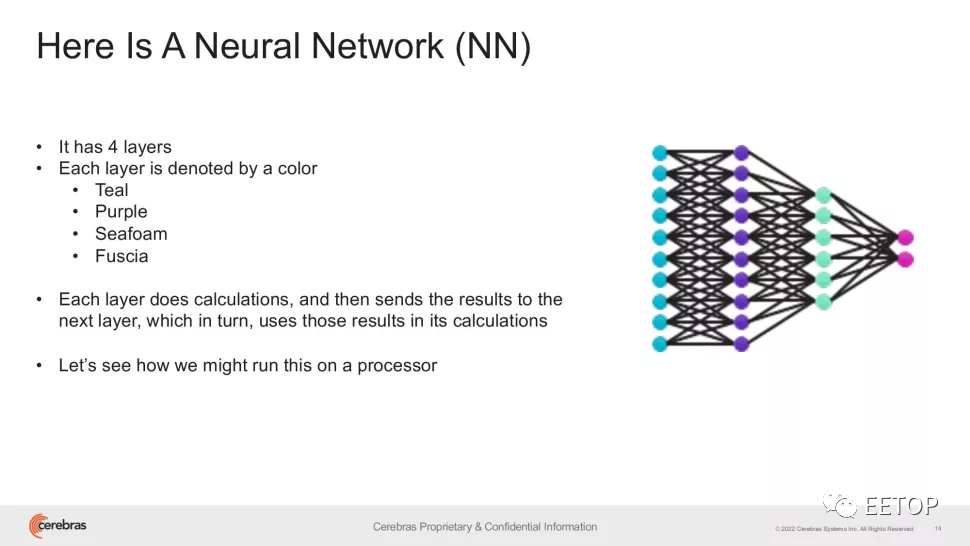
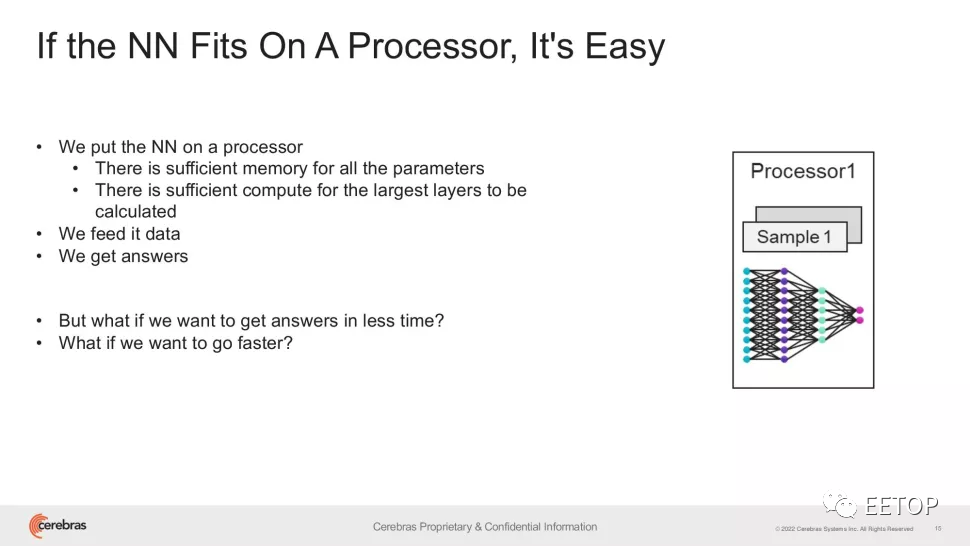
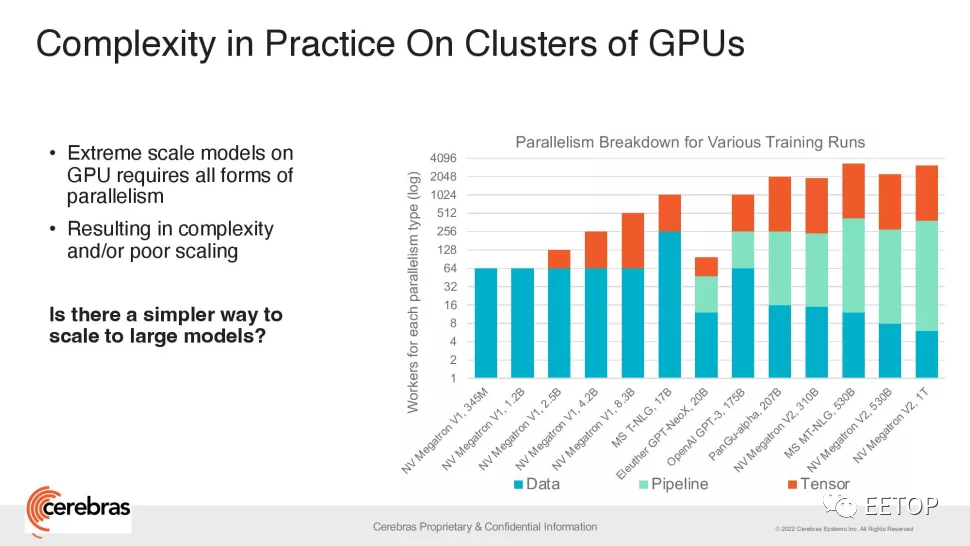
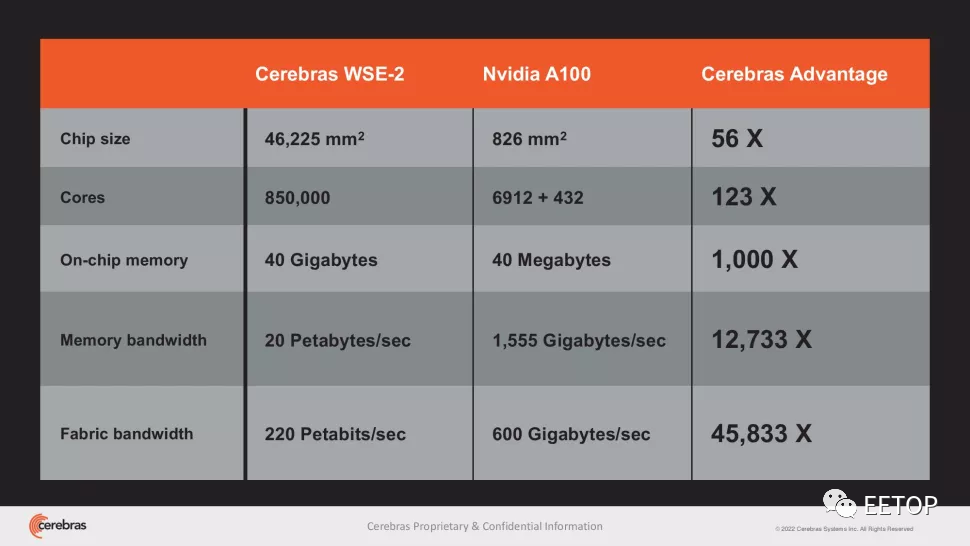
"杀死"GPU!集成2.6万亿晶体管、世界最大芯片再破纪录:前所未有的200亿个参数,最大自然语言处理模型诞生!


 RFCSch9ic9C7ZONdOwmPXibUVZPgaZk6gV4Q/640?wx_fmt=png" data-type="png" data-w="970" _width="677px" src="https://www.eetop.cn/uploadfile/2022/0623/20220623010339361.jpg" crossorigin="anonymous" alt="图片" data-fail="0" style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important; vertical-align: bottom; height: auto !important; width: 677px !important; visibility: visible !important;"/>
RFCSch9ic9C7ZONdOwmPXibUVZPgaZk6gV4Q/640?wx_fmt=png" data-type="png" data-w="970" _width="677px" src="https://www.eetop.cn/uploadfile/2022/0623/20220623010339361.jpg" crossorigin="anonymous" alt="图片" data-fail="0" style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important; vertical-align: bottom; height: auto !important; width: 677px !important; visibility: visible !important;"/>