基于卷积神经网络的图像分类算法 译文
译者 | 朱先忠
审校 | 孙淑娟
1.什么是卷积神经网络(CNN)?
概括来讲,卷积神经网络是一类特殊的神经网络,具有从图像数据中提取独特的图像特征的能力。例如,目前卷积神经网络已经被广泛应用于人脸检测和识别,因为它们非常有助于识别图像数据中的复杂特征。
2.卷积神经网络是如何工作的?
与其他类型的神经网络一样,CNN也使用数字数据。因此,馈送到这些网络的图像必须先转换为数字表示。因为图像是由像素组成的,所以它们被转换成数字形式后再传递给CNN。
正如我们将在下一节中讨论的,整个数字表示层并没有传递到网络中。为了理解这是如何工作的,让我们看看训练CNN的一些步骤。
卷积
通过卷积运算减小发送给CNN的数字表示的大小。这一过程至关重要,因此只有对图像分类重要的特征才会被发送到神经网络。除了提高网络的准确性外,这还可以确保在训练网络时使用最少的计算资源。
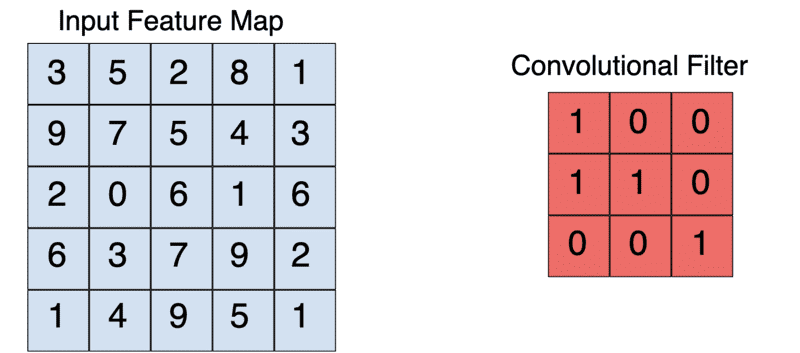
卷积运算的结果称为特征映射、卷积特征或激活映射。应用特征检测器可以生成特征映射。特征检测器也被称为内核或过滤器等其他名称。
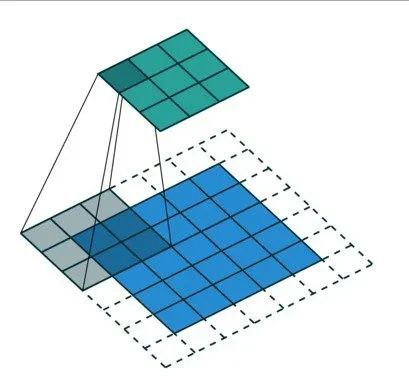
内核通常是一个3X3的矩阵。将内核与输入图像按元素相乘并求和,输出特征映射。这是通过在输入图像上滑动内核来实现的。这种滑动以步长的形式发生。当然,创建CNN时,可以手动设置内核的步长和大小。
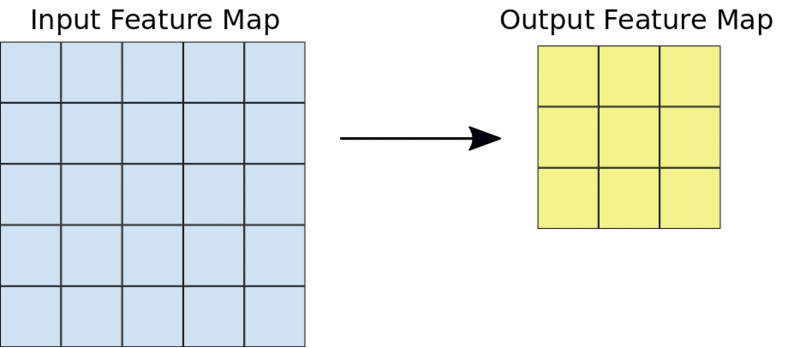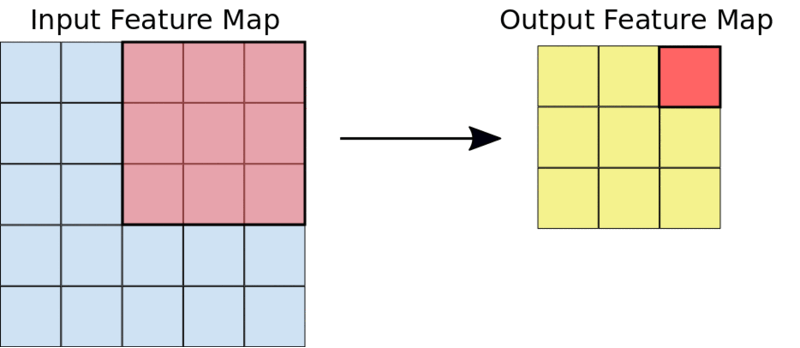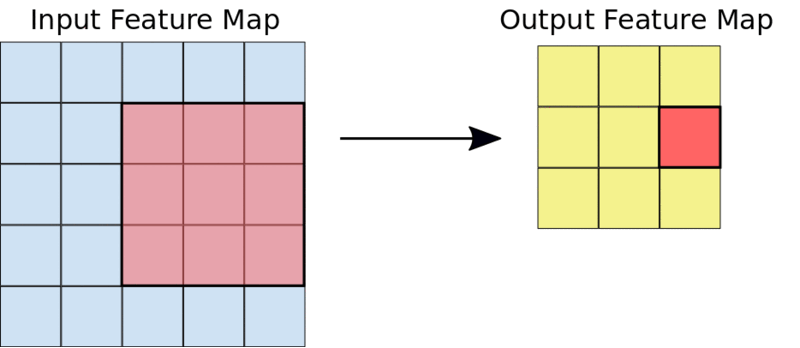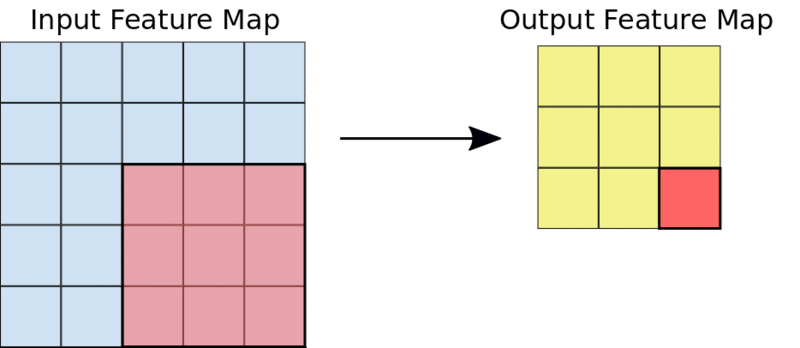
一个典型的3X3的卷积操作
例如,给定一个5X5的输入,一个3X3的内核将输出一个3X3的输出特征映射。
填充(Padding)
在上述操作中,我们看到,作为应用卷积操作的一部分,特征映射的大小减小了。那么,如果希望特征映射的大小与输入图像的大小相同,该怎么办?这是通过填充实现的。
填充操作是指通过用零“填充”图像来增加输入图像的大小。因此,对图像应用这种过滤器会产生与输入图像大小相同的特征映射。
未着色的区域代表填充区域
填充操作不仅减少了卷积运算中丢失的信息量,而且还能够确保在卷积运算中更频繁地划分图像的边缘。
在构建CNN时,您可以选择定义所需的填充类型或完全不填充。这里的常见选项包括:有效(valid)或相同(same)。其中,valid表示不应用填充处理;而same表示应用填充处理,以便特征映射的大小与输入图像的大小相同。
3×3内核将5×5的输入减少为3×3的输出
下图给出的是上面描述的特征映射和过滤器的元素相乘的样子。
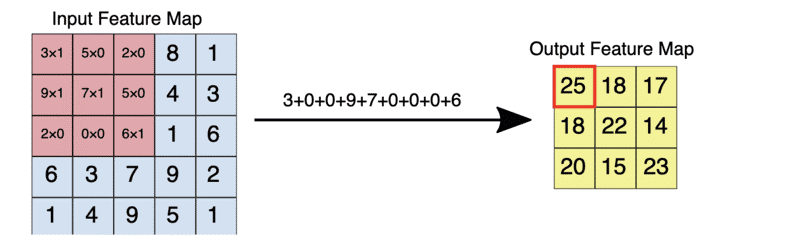
激活函数
在每次卷积运算后应用线性整流函数(ReLU)变换以确保非线性。ReLU是当前最流行的激活函数,但是也有其他一些激活函数可供选择。
转换后,所有低于零的值都返回为零,而其他值则保持不变。

ReLu函数图
池化
在池化操作中,特征映射的大小进一步减小。当前,可以使用各种池化方法。
一种常见的方法是最大池化法。池过滤器的大小通常是一个2×2矩阵。在最大池化法中,2×2过滤器在功能映射上滑动,并在给定范围的矩形框中选取最大值。此操作将生成池化的特征映射。
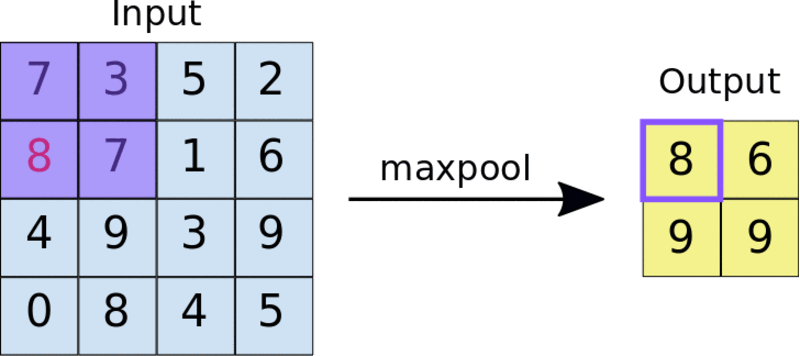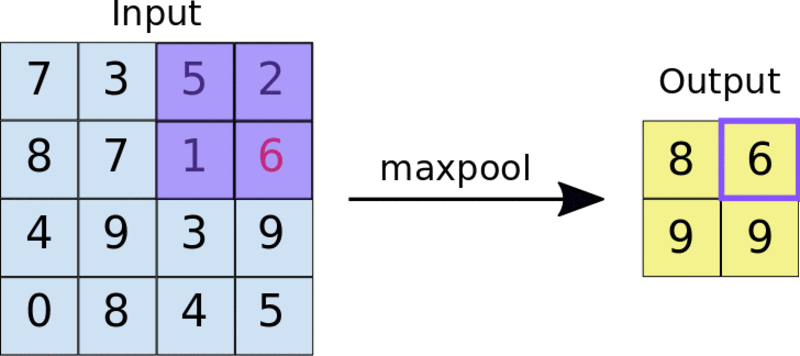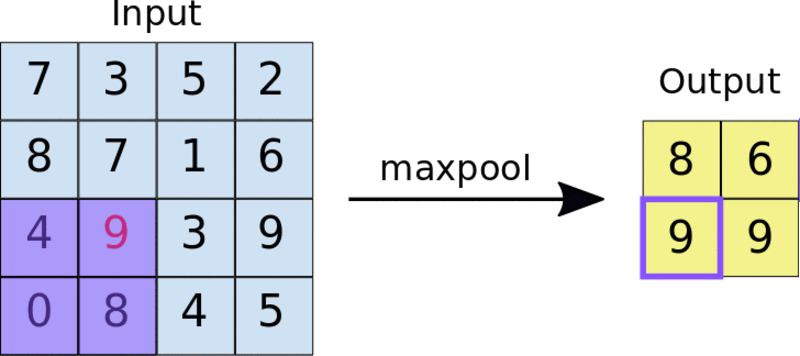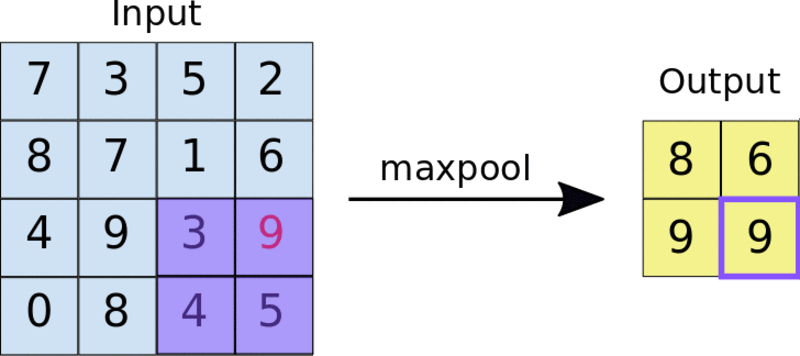
把2×2池过滤器应用于4×4特征映射
池化迫使神经网络识别图像中的关键特征,而不必考虑这些关键特征数据的位置。此外,缩小的图像大小也有助于网络训练速度更快一些。
Dropout正则化
应用Dropout正则化是CNN的常见做法。这涉及到在一些特定网络层中随机删除一些节点,以便在反向传播期间不会更新它们。这样可以防止过度拟合。
扁平化
扁平化的主要任务是将池化后的特征映射转换为一个单列,并传递给完全连接层。这是从卷积层过渡到完全连接层期间的常见做法。
完全连接层
接下来,扁平化后的特征映射被传递到完全连接层。根据特定的问题和网络类型,可能存在好几个完全连接层。其中,最后一个完全连接层负责输出预测结果。
根据问题的类型,在最后一层中使用激活函数。其中,sigmoid激活函数主要用于二值分类的情形,而softmax激活函数通常用于多类别图像分类。

全连接卷积神经网络
3.为什么卷积神经网络优于常规型前馈神经网络?
了解了CNN之后,你可能想知道为什么我们不能用普通的神经网络来解决图像问题,主要原因在于,常规的神经网络无法像CNN那样从图像中提取复杂的特征。
CNN通过应用过滤器从图像中提取额外特征的能力使其更适合处理图像问题。此外,将图像直接输入前馈神经网络的计算成本也会很高。
4.卷积神经网络架构
你可以选择从头开始设计你的CNN,也可以利用公开开发和发布的众多CNN体系结构。值得注意的是,其中一些CNN网络还带有预先训练的模型,你可以轻松地根据自己的使用需求进行调整。下面是一些可供你选择的流行的CNN架构:
- ResNet50
- VGG19
- Xception
- Inception
您可以通过Keras应用程序开始使用这些架构。例如,下面的代码展示了如何使用VGG19框架进行开发的框架示例:
from tensorflow.keras.applications.vgg19 import VGG19
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input
import numpy as np
model = VGG19(weights='imagenet', include_top=False)
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x)
5.卷积神经网络(CNN)在TensorFlow中的应用
现在,让我们使用食物数据集构建一个食物分类CNN。该数据集包含101个类别的10多万张图像。
加载图像
第一步是下载并提取数据。
!wget --no-check-certificate \
http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz \
-O food.tar.gz
!tar xzvf food.tar.gz
让我们看一下数据集中的一幅图像。
plt.imshow(Image.open("food-101/images/beignets/2802124.jpg"))
plt.axis('off')
plt.show()
生成一个tf.data.Dataset
接下来,将图像加载到TensorFlow数据集中。我们将使用20%的数据进行测试,其余数据用于训练。因此,我们必须为训练和测试集创建一个图像数据集合(通过调用训练集生成器函数ImageDataGenerator实现)。
在训练集生成器函数中还需要指定几种图像增强技术,例如缩放和翻转图像等。需要说明一点,增强功能有助于防止网络中出现过度拟合。
base_dir = 'food-101/images'
train_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
validation_split=0.2
)
validation_gen = ImageDataGenerator(rescale=1./255,validation_split=0.2)
创建图像集生成器后,下一步的任务就是使用它们从基目录位置加载食物图像。加载图像时,我们需要指定图像的目标大小。所有图像都将调整为可指定大小。
image_size = (200, 200)
training_set = train_datagen.flow_from_directory(base_dir,
seed=101,
target_size=image_size,
batch_size=32,
subset = "training",
class_mode='categorical')
注意到,在加载图像时我们还需要指定:
- 加载图像的目录位置。
- 批量大小,在本例中为32,这意味着图像将以32个批次加载。
- 子集;无论是训练还是验证时都需要指定。
- 由于我们有多个类型的图像,因此类型模式为多分类模式。对于两个类别的情形,这个参数可以使用二进制数来指定。
validation_set = validation_gen.flow_from_directory(base_dir,
target_size=image_size,
batch_size=32,
subset = "validation",
class_mode='categorical')
模型定义
下一步是定义CNN模型。神经网络的架构方案将与我们前面在“卷积神经网络是如何工作的?”一节中讨论的步骤类似。我们将使用Keras网络框架中的Sequential API来定义网络。其中,CNN部分是使用Conv2D层定义的。
model = Sequential([
Conv2D(filters=32,kernel_size=(3,3), input_shape = (200, 200, 3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Conv2D(filters=32,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Conv2D(filters=64,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.25),
Dense(101, activation='softmax')
])
该Conv2D层有如下期望:
- 在本例中,使用的过滤器数量为32。
- 在本例中,使用的内核的大小数量为3X3。
- 输入图像的大小。200X200是图像的大小,3指定这是一种彩色图像。
- 激活函数,通常使用的就是ReLu函数。
在上述网络中,我们使用2X2的过滤器进行池化,并应用一个Dropout层以防止过度拟合。最后一层有101个单元,因为有101个食物类别。激活函数使用的是softmax函数,因为我们解决的是一个多类别图像分类问题。
编译CNN模型
接下来,我们使用分类损失算法和精确算法对网络进行编译,因为它涉及多个类。
model.compile(optimizer='adam',
loss=keras.losses.CategoricalCrossentropy(),
metrics=[keras.metrics.CategoricalAccuracy()])
训练CNN模型
接下来,我们开始训练CNN模型。
现在让我们开始训练CNN模型。在训练过程中,我们要应用EarlyStopping回调函数;这样做的目的是,如果模型在多次迭代后没有得到改善,训练就会停止。在本例情况下,共使用了三个训练周期(epochs)。
callback = EarlyStopping(monitor='loss', patience=3)
history = model.fit(training_set,validation_data=validation_set, epochs=100,callbacks=[callback])
本例中,由于我们正在处理的图像数据集相当大,所以我们需要使用GPU来训练这个模型。让我们利用Layer网站(【译者注】遗憾的是无法打开此网站,读者知道这种思路即可,其实当前市面上已经有多种免费在线GPU服务可供AI学习之用)提供的免费GPU来训练模型。为此,我们需要将上面开发的所有代码“捆绑”到一个函数中。此函数应返回一个模型。在本例情况下,返回的是一个TensorFlow模型。
要使用GPU训练模型,只需使用GPU环境参数装饰一下函数,这是使用fabric装饰器(https://docs.app.layer.ai/docs/reference/fabrics)指定的。
#pip install layer-sdk -qqq
import layer
from layer.decorators import model, fabric,pip_requirements
#验证层帐户
#经过训练的模型将保存在此。
layer.login()
#初始化一个项目,经过训练的模型将保存在此项目下。
layer.init("image-classification")
@pip_requirements(packages=["wget","tensorflow","keras"])
@fabric("f-gpu-small")
@model(name="food-vision")
def train():
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense,Conv2D,MaxPooling2D,Flatten,Dropout
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import EarlyStopping
import os
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import pandas as pd
import tarfile
import wget
wget.download("http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz")
food_tar = tarfile.open('food-101.tar.gz')
food_tar.extractall('.')
food_tar.close()
plt.imshow(Image.open("food-101/images/beignets/2802124.jpg"))
plt.axis('off')
layer.log({"Sample image":plt.gcf()})
base_dir = 'food-101/images'
class_names = os.listdir(base_dir)
train_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
validation_split=0.2
)
validation_gen = ImageDataGenerator(rescale=1./255,validation_split=0.2)
image_size = (200, 200)
training_set = train_datagen.flow_from_directory(base_dir,
seed=101,
target_size=image_size,
batch_size=32,
subset = "training",
class_mode='categorical')
validation_set = validation_gen.flow_from_directory(base_dir,
target_size=image_size,
batch_size=32,
subset = "validation",
class_mode='categorical')
model = Sequential([
Conv2D(filters=32,kernel_size=(3,3), input_shape = (200, 200, 3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Conv2D(filters=32,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Conv2D(filters=64,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.25),
Dense(101, activation='softmax')])
model.compile(optimizer='adam',
loss=keras.losses.CategoricalCrossentropy(),
metrics=[keras.metrics.CategoricalAccuracy()])
callback = EarlyStopping(monitor='loss', patience=3)
epochs=20
history = model.fit(training_set,validation_data=validation_set, epochs=epochs,callbacks=[callback])
metrics_df = pd.DataFrame(history.history)
layer.log({"Metrics":metrics_df})
loss, accuracy = model.evaluate(validation_set)
layer.log({"Accuracy on test dataset":accuracy})
metrics_df[["loss","val_loss"]].plot()
layer.log({"Loss plot":plt.gcf()})
metrics_df[["categorical_accuracy","val_categorical_accuracy"]].plot()
layer.log({"Accuracy plot":plt.gcf()})
return model
训练模型的任务是通过将训练函数传递给“layer.run”函数来完成的。如果希望在本地基础设施上训练模型,则可以通过调用“train()”函数来实现。
layer.run([train])

预测
模型准备好后,我们可以对新图像进行预测,这可以通过以下步骤完成:
- 从前面提及的在线GPU服务网站获取经过训练的模型。
- 加载与训练图像中使用的图像大小相同的图像。
- 将图像转换为数组。
- 将数组中的数字除以255,使其介于0和1之间。切记:所有参与训练图像的形式都必须是相同的。
- 扩展图像的尺寸——增加1个batch_size大小,因为我们正在对单个图像进行预测。
from keras.preprocessing import image
import numpy as np
image_model = layer.get_model('layer/image-classification/models/food-vision').get_train()
!wget --no-check-certificate \
https://upload.wikimedia.org/wikipedia/commons/b/b1/Buttermilk_Beignets_%284515741642%29.jpg \
-O /tmp/Buttermilk_Beignets_.jpg
test_image = image.load_img('/tmp/Buttermilk_Beignets_.jpg', target_size=(200, 200))
test_image = image.img_to_array(test_image)
test_image = test_image / 255.0
test_image = np.expand_dims(test_image, axis=0)
prediction = image_model.predict(test_image)
prediction[0][0]
由于这是一个多类别网络,我们将使用softmax函数来解释结果。该函数将logit转换为每个类别的概率。
class_names = os.listdir(base_dir)
scores = tf.nn.softmax(prediction[0])
scores = scores.numpy()
f"{class_names[np.argmax(scores)]} with a { (100 * np.max(scores)).round(2) } percent confidence."
6.小结? ??
在本文中,我们详细介绍了卷积神经网络有关知识。具体来说,文章中涵盖了如下内容:
- 什么是CNN?
- CNN如何工作
- CNN架构
- 如何为图像分类问题构建CNN
原文链接:
https://www.kdnuggets.com/2022/05/image-classification-convolutional-neural-networks-cnns.html
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。

