巨龙信息大数据集成技术 海量数据集成架构实践
产品介绍

? ? ? ?巨龙信息(厦门市巨龙信息科技有限公司)研发的大数据集成系统是一款基于分布式并行计算架构开发的ETL数据集成系统。具备高吞吐、高可用、高扩展特性,可以为海量数据的超大规模数据仓库建设提供抽取、整合、清洗、入库等集成业务。
产品特征
■高吞吐处理能力:采用多线程处理算法,高效的内存利用率;任务运行过程无需本地磁盘IO操作,提升整体单位时间的大批量处理能力;支持TB/h级的大数据集成业务性能。
■高扩展、高可靠:并行架构提升单机处理能力的线性扩展;新增执行引擎的快速部署和自动识别,分布式架构提升多机处理能力的线性扩展;执行引擎宕机的自动识别和任务转移,保证任务的顺利执行。
■可视化流程配置:通过简单的图形拖拽配置数据集成流程,简单易用的专业化配置。
■集成业务全流程监控:可对处理过程的每个步骤,每个子流程处理进行实时监控,简单快速发现处理过程遇到的漏数据,错处理等问题。
■统一的元数据模型:基于统一公共仓库元模型,可与公司产品线其他产品无缝对接,简化整体解决方案的实施运维。
■大数据技术支持:支持主流的关系型数据库,NOSQL数据库,全文库处理等主流大数据产品的抽取入库,以及异构库之间的抽取入库。
■低廉的硬件成本:使用x86架构的PCServer,无需昂贵的unix服务器。
技术亮点
高性能
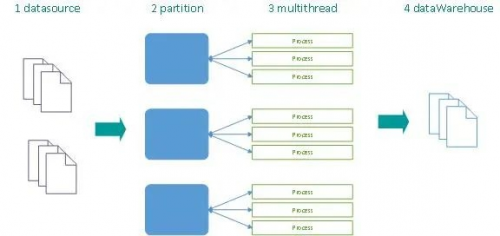
■任务的水平切分
一个分布式ETL任务会根据分区自动被分片到多台ETL-执行引擎中,每个执行引擎的执行容器使用多线程并发的对数据进行加工处理后加载到数据仓库中。当源头库单表数据量巨大时,可极大提升整体的数据集成效率和性能
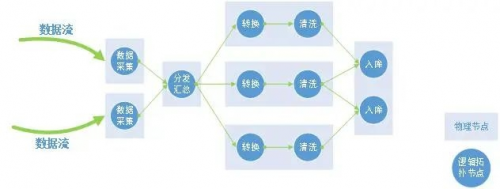
■任务拓扑切分
一个任务的各个步骤,可根据现场物理设备的实际配置,合理地安排到不同的物理设备上,保证硬件资源满足步骤的执行
高扩展
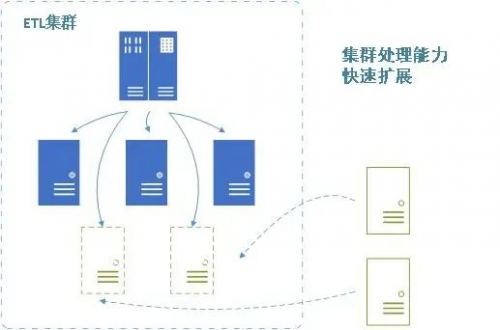
■集群处理能力的线性扩展
??集群处理能力的快速扩充
??集群自动识别和热部署新增执行引擎
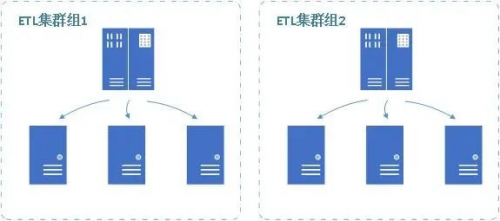
■多集群组
??根据业务划分集群组,使关注点分离
??集群组有利于异常干扰的隔离
■单任务并行计算
??任务步骤的独立线程数可配置
??IO的合理平衡
??内存空间的合理利用,减少内存垃圾回收率

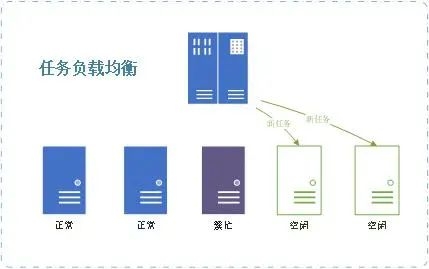
■任务的分布式调度
??带权重的负载均衡算法,可根据设备处理能力安排并发任务数
??控制中心对集群环境的自动负载均衡
高可用
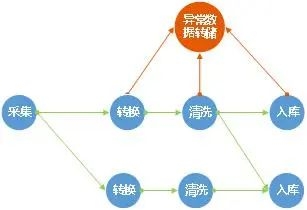
■异常数据分流
??可选的异常数据分流机制,保证不影响正常流程的情况下异常数据分流
??保证每个步骤出现的异常数据转储到指定地点,不丢失
■控制中心HA
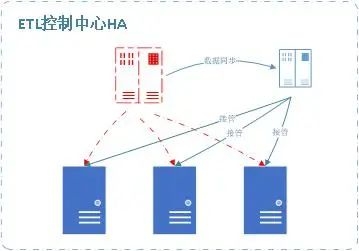
■任务的异常处理
??自动感知执行引擎异常,将异常设备的任务转发到正常设备上重新执行
??任务在一台设备上执行过程出现错误,自动重新在另外一台设备重新执行

