从苹果M1 Ultra看Chiplet封装
苹果在本月初发布了最新一代的M1 Ultra芯片,采用了独特的 UltraFusion 芯片架构。借助桥接工艺,这款Ultra芯片拥有 1,140 亿个晶体管,数量达到了M1的 7 倍之多。虽然芯片还是采用与上一代M1 max一样的5nm工艺节点,但在新架构加持下,两颗 Max 之间的互连频宽可达 2.5TB/s。这种架构的好处是运行在目前M1芯片上的软件无需修改相关的指令就可以直接运行,省去了应用端更新软件或开发新应用层命令的需求。同时,增加一个芯片后,对内存处理的带宽也直接翻倍,收获的性能提升非常显著,特别是针对GPU处理能力方面,是极具爆发力的。
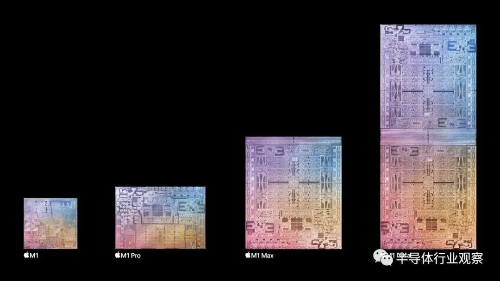
苹果M1芯片进化
(Source:Apple)
近日,评测机构也对比了几款主流芯片与M1 Ultra的性能。在单核处理能力上,Ultra并不比Max优秀。但在多核多线程的性能上,性能翻倍,可以说是秒杀上一代芯片。但相关的功耗并无披露,在之后的评测中可以继续关心相关性能。
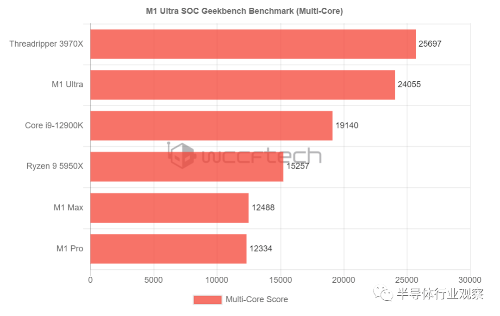
M1 Ultra多核多线程处理能力对比
(Source:WCCFtech)
从目前透露的信息,并不能确定M1 Ultra来源于哪种桥接工艺(估计随后的Teardown即可见分晓),因为目前包括TSMC和Intel都有埋入硅桥的类似量产工艺。但由于使用的是2个同样的芯片,从芯片设计角度来说并不能算严格意义的Chiplet,更多是一个Multi-die package的设计。作者观点,考虑到台积电为Apple主力代工的关系,采用台积电埋入硅桥的可能性较大。从台积电宣传介绍了解到LSI在去年Q1还在做验证,而M1 Max在去年10月左右推出,M1 Ultra今年3月推出,在开发时间上虽然很紧凑但也并非不可匹配。M1 Max在推出的时候也预留了桥接的I/O,加快了M1 Ultra的开发周期。由此可见Ultra早已在1年前或更早时间就已经在苹果的计划中。

台积电的局部硅桥(local silicon interconnect)
(Source: 台积电)
台积电的硅桥技术分为硅通孔桥和硅上RDL桥。所谓硅通孔桥就是在埋入的硅桥中有TSV,信号穿过硅通孔,通过TSV进行桥接。而RDL桥就是在硅上进行RDL制备,而为了确保可靠性和工艺兼容,目前主要的绝缘层材料大多采用ABF或低热膨胀EMC。

台积电局部硅桥(local silicon interconnect)
(Source: TSMC)
台积电局部硅桥基于晶圆级硅工艺,比如金属化和钝化层形成等仍然是采用IC制造机台,因此其RDL精度非常高,可以轻松实现2微米线宽。这与Intel的Embedded Multi-Tile Interconnect Bridge(EMIB)工艺完全不同,因为EMIB是使用板级基板工艺机台,虽说硅桥本身可以做到2微米线宽,但埋入的后期工艺配合上有些挑战,本文后面会介绍。

台积电高密度RDL
(Source: TSMC)
台积电的InFO/CoW我们接收的信息比较多了,很多文章有介绍过,这里不进行详述。接下来我们重点看看Intel的EMIB技术。
早在2011年的一个封装国际会议上【1】, Intel的工程师就提出了用硅桥连接2个硅处理器的概念。而当时的版本还未提及埋入这一概念,只是展示了桥接后较好的电性能。对如何封装,如何大规模生产,以及如何保证封装体的可靠性等都是未知数。

硅桥连接【1】
但很快,Intel在次年(2012)的一份专利中将目前版本的雏形进行了描述【2】。而这份专利直到2015年授权之后才被公开。所以,我们其实能看到的最早对EMIB的详细描述是Intel在2016年ECTC发表的论文【3】。在这篇论文中,Intel展示了EMIB的结构,工艺,样品性能等。通过这一技术,EMIB可以实现与CoWoS类似的I/O数量和带宽。然而,开发结合封装基板技术与芯片制备技术的混合芯片封装体充满挑战,即使强大如Intel也花费了不少时间,至今才达到了能量产的程度。接下来我们结合Intel发表的一些公开的论文,试图管中窥豹。
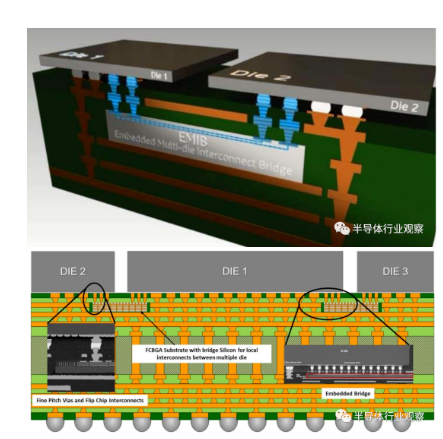
EMIB内部结构示意图【3】
相对于其他2.5D/3D封装技术,EMIB的主要技术优势有以下几点【4】:
? ? ? ?1.利用先进有机基板工艺实现局部高密度布线。区别于需要更大尺寸硅中介层和高密度硅通孔(TSV)的其他2.5D多芯片封装技术,能针对I/O需求实现局部高密度布线。
2.无光罩尺寸限制。由于要保证曝光显影的精准度和数值孔径,光刻工艺的光罩尺寸范围通常有其限制,例如M1 Max的芯片最大可用尺寸在19.05mmx22.06mm(约420mm?),已经是台积电硅桥CoWoS工艺的一半。EMIB则无需限制芯片尺寸,可以通过局部硅桥实现相对自由的芯片尺寸搭配(InFO-LSI也是干这个事)
3.相对硅TSV而言,EMIB的制造工艺更简单,成本也相对更低(如果良率相等的情况)。同时,减少更多硅的浪费,只在需要互联的地方放置硅桥。
然而主要的挑战在板级工艺。因此EMIB缺点主要集中在工艺实现【4】:
1.引入了更复杂的有机基板制备工艺,在精准度控制上远高于目前的有机基板布线。由此需要针对这一系统进行特殊材料和工艺的开发。
2.跟普通的倒装芯片类似,由于有机基板的热膨胀系数(CTE)与硅桥芯片的CTE存在失配,使得表面贴装的芯片引脚,芯片背面和填充热界面材料之间产生较大的应力。
EMIB工艺由于搭配了硅和有机基板工艺,所以在技术上体现了目前先进封装的一个主流趋势 - 融合,特别是前段硅制程与后端封装制程的融合。从硅桥部分来看,通常,硅桥的尺寸在2-8毫米左右,而芯片厚度在75微米以下,从而保证跟基板工艺所匹配,同时实现较高精准度的布线和对准工艺。目前Intel针对的是4层布线结构的开发,能满足大多数I/O需要。虽然,目前硅桥上的金属布线的线间距可以稳定实现2微米,进一步进行细微化也是非常可行的,因为金属布线的结构都是在目前成熟的硅后端工艺中进行制造。然而,随着布线宽度的减小,线电阻会急剧增加,线间的电容也会改变,这给信号的完整性(integrity)增加了挑战。因此,在进行硅桥走线设计时,需要非常详细的架构设计和模拟工作来保证最终的产品性能。另外,介电层的材料介电常数和高频损耗对布线也有影响。因此,硅桥的设计工作是非常挑战的,它完全不同于目前的硅芯片设计师们的日常设计理念,而需要懂材料,懂封装,懂制程和懂信号完整性的资深工程师(们)来共同实现。
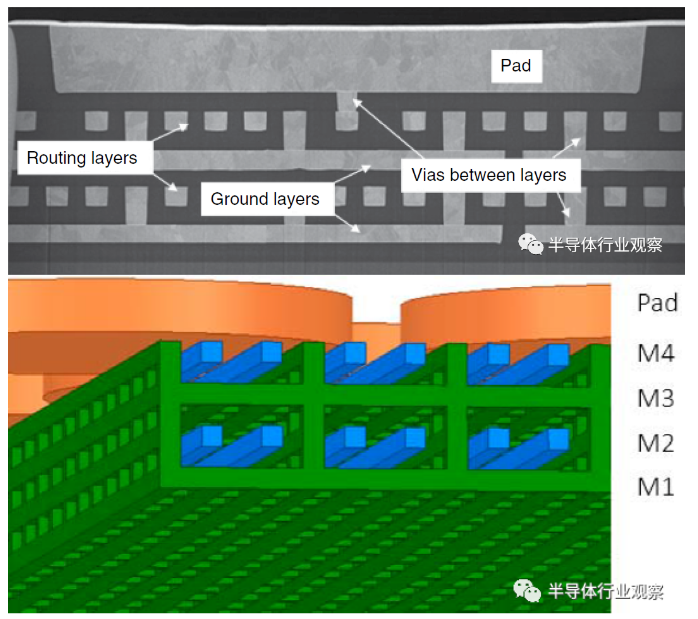
硅桥内部结构示意图【4,5】
从硅桥的集成部分来看大概的工艺流程涉及到几个关键步骤:基板的压合,铜制程,激光以及芯片贴装的埋入工艺。针对特殊工艺,Intel开发了自家的埋入封装(embedded)制程。其实在当时埋入封装已经不是什么新东西,日本的厂家在早年曾做过针对电阻电容的埋入封装。但由于那时还是PCB工艺,用的是CO2激光,非常粗糙;镀铜工艺也相对落后,根本没法做2微米的线宽,自然也不会有人想到用基板工艺去做芯片的高密度连接。Intel在10年前能想到用硅桥技术结合埋入封装确实是一个大胆之举。在加成法(Additive)镀铜工艺和Coreless基板工艺成熟后,EMIB的实现也就水到渠成了。
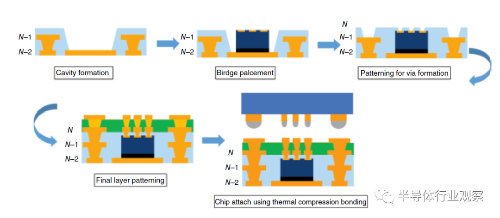
EMIB工艺示意图【4】
埋入的过程由于采用有机基板工艺,对公差的控制提出了更高的要求,例如芯片的厚度,芯片的切割,芯片的贴装,和薄片的转移等都是及其挑战的,需要独有机器进行配合。另外,整体的基板制备是扇出型的大板(FOPLP)封装形式(500mm X 500mm),对板级的工艺一致性要求非常高。然而,在达到相对成熟的工艺良率后,产出的成本是相对较低的。同时,大板封装有其先天优势,适合制造非常大的集成芯片,这与目前的小芯片(Chiplet)技术上的需求是吻合的。与普通FOPLP不同的是,EMIB并不需要将芯片从临时的载板上取下,当芯片被贴上之后就是永久固定的,减小了芯片在后续工序中位移的风险。

埋入在有机基板中的硅桥【6】
硅桥的芯片虽然只有2-8mm,但是小于75微米的薄片会由于内部的Cu布线结构产生芯片翘曲。另外,芯片贴装膜(DAF)的存在也会直接导致切割后的芯片产生翘曲。因此,如何控制贴装之后的芯片不产生孔洞及分层,乃至芯片破裂又是一个挑战所在。针对这一要求,Intel开发了针对这一工序的DAF材料,并通过优化基板铜层的表面,贴装材料固化工艺和有机材料的叠层工艺,实现了可接受的过程。

无分层的芯片贴装截面【6】
在除了以上跟芯片贴装相关的精准控制要求之外,在进行大面积高数量激光钻孔的对准上也极其挑战。硅桥表面的铜引脚尺寸在50微米左右(或更小),而间距(pitch)可能在70微米(或更小)。因此对激光钻孔机器本身的对准要求极高。如激光开口无法与硅桥上的铜引脚对应(部分对应也不行),在之后的阻抗匹配和信赖性的表现上就有可能会出现问题。当然,除了激光通孔,也可以使用掩膜版光刻的形式去形成对位孔,采用物理刻蚀的方式去形成通孔,而Intel采用何种工艺估计会根据孔的密度来进行选择。
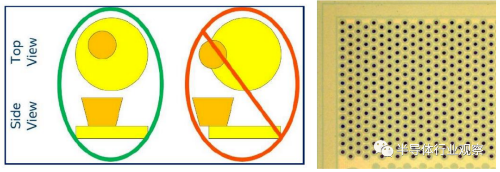
埋入的硅桥需要精准的激光钻孔对位【6】
在实现上下通孔后,要实现互联的工序就是进行化学及电化学铜沉积,这在基板工艺中是成熟工艺。但通孔的尺寸实在是很小,对填铜工艺是有挑战的,当液体无法进行充分的离子交换,填铜的速度在整个500mmx500mm的大板中沉积的速度不一样时就会导致不同的填充厚度。同时水平和垂直电镀线的药水和工艺能力也存在较大差异,相信Intel在开发过程中在这一工序上没少尝试。

硅桥上填充的铜通孔【6】
Intel自家的技术自然也在自家的产品上积极运用。针对超级计算机和人工智能应用,Intel在2019年公布了基于Xe架构的芯片系统-真的是一个芯片系统,非常多芯片。该系统被命名为Ponte Vecchio,是用于高性能计算的下一代加速器。它结合47个Magical Tiles,主要由Compute Tiles、Base Tiles、Rambo Cache tile和Xe Link Tiles组成,每个Tiles都使用不同的制程制造。关于该芯片的命名,来源于意大利佛罗伦萨最古老的桥韦基奥桥(Ponte Vecchio),桥最初是以建筑师的名字命名的,类似我们中国贵州的风雨廊桥。而Intel以此桥为名字,想必是为了体现该系统的经典和复杂,因为在现实中这座桥和周围的建筑是一个拜占庭式的庞然大物,桥的两边是当地的特色建筑,它们通过这座桥以巧妙的方式相互连接,形成这么一个古老而又有特殊建筑风格的大师级作品。

意大利Ponte Vecchio桥
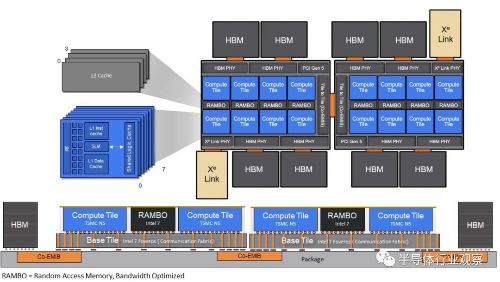

Intel芯片架构及Ponte Vecchio集成
(Source: Intel)
在Ponte Vecchio芯片中,不仅有EMIB,还有FOVEROS,可谓是当今3D集成度顶尖的芯片案例。美国能源部超级计算机Aurora将以Ponte Vecchio为核心的,每个Ponte Vecchio系统每秒能够进行超过45万亿次32位浮点运算。四个这样的系统与两个Sapphire Rapids CPU一起构成一个完整的计算系统。超过54000个Ponte Vecchios和18000个SapphireRapids组合在一起,形成Aurora。
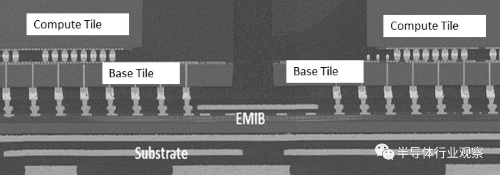
Ponte Vecchio高性能加速器GPU
及其EMIB结构【7】
当芯片节点来到5nm,仅仅通过硅工艺来延续摩尔定律似乎已经捉襟见肘。台积电和Intel用先进封装结合硅工艺给半导体行业带来了新的范式,通过先进封装系统集成给摩尔定律的延续,提供了一种新的方向。

