SSD直接连接到GPU,英伟达终于出手了
英伟达、IBM 和大学合作者开发了一种架构,他们称该架构将为 GPU 加速的应用程序(例如分析和机器学习训练)提供对大量数据存储的快速细粒度访问。
这种技术被称为大加速器内存(Big accelerator Memory),又名 BaM,这是一个有趣的尝试,旨在减少 Nvidia 图形处理器和类似硬件加速器在访问存储时对通用芯片的依赖,这可以提高容量和性能。
我们知道,现代图形处理单元不仅仅用于图形;它们还用于各种重型工作负载,例如分析、人工智能、机器学习和高性能计算 (HPC)。为了高效地处理大型数据集,GPU 要么需要大量昂贵的本地专用内存(例如 HBM2、GDDR6 等),要么需要高效地访问固态存储。现代计算 GPU 已经搭载 80GB–128GB 的 HBM2E 内存,下一代计算 GPU 将扩展本地内存容量。但数据集大小也在迅速增加,因此优化 GPU 和存储之间的互操作性很重要。
换而言之,我们必须改进 GPU 和 SSD 之间的互操作性有几个关键原因:首先,NVMe 调用和数据传输给 CPU 带来了很大的负载,从整体性能和效率的角度来看,这是低效的。其次,CPU-GPU 同步开销和/或 I/O 流量放大显着限制了具有大量数据集的应用程序所需的有效存储带宽。
“BaM 的目标是扩展 GPU 内存容量并提高有效的存储访问带宽,同时为 GPU 线程提供高级抽象,以便轻松按需、细粒度地访问扩展内存层次结构中的海量数据结构”,该团队在其撰写的论文中说。
BaM 是 Nvidia 将传统的以 CPU 为中心的任务转移到 GPU 内核的一步。BaM 不依赖于虚拟地址转换、基于页面错误的按需加载数据以及其他以 CPU 为中心的传统机制来处理大量信息,而是提供了允许 Nvidia GPU 获取的软件和硬件架构直接从内存和存储中获取数据并对其进行处理,而无需 CPU 内核对其进行编排。
BaM 有两个主要部分:GPU 内存的软件管理缓存;以及用于 GPU 线程的软件库,通过直接与驱动器对话,直接从 NVMe SSD 请求数据。在存储和 GPU 之间移动信息的工作由 GPU 内核上的线程处理,使用 RDMA、PCIe 接口和允许 SSD 在需要时直接读取和写入 GPU 内存的自定义 Linux 内核驱动程序。如果请求的数据不在软件管理的缓存中,驱动器的命令将由 GPU 线程排队。
这意味着在 GPU 上运行以执行密集型工作负载的算法可以快速获取所需的信息,并且——至关重要的是——以针对其数据访问模式进行优化的方式。
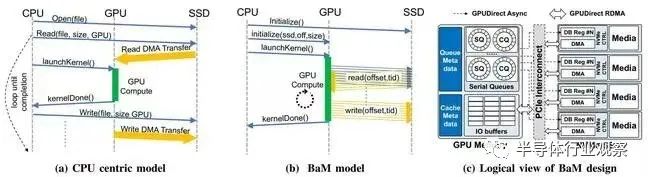
论文中的图表比较了传统的以 CPU 为中心的存储访问方法 (a) 与 GPU 主导的 BaM 方法 (b) 以及所述 GPU 将如何物理连接到存储设备 (c)。
研究人员使用现成的 GPU 和 NVMe SSD 测试了一个由 Linux 驱动的原型 BaM 系统,以证明它是当今让主机处理器指挥一切的方法的可行替代方案。我们被告知,可以并行化存储访问,消除同步障碍,更有效地使用 I/O 带宽来提高应用程序性能。
“以 CPU 为中心的策略会导致过多的 CPU-GPU 同步开销和/或 I/O 流量放大,从而减少具有细粒度数据相关访问模式(如图形和数据分析、推荐系统和图形)的新兴应用程序的有效存储带宽神经网络,”研究人员在论文中说。
借助软件缓存,BaM 不依赖于虚拟内存地址转换,因此不会遭受诸如 TLB 未命中之类的序列化事件的影响,”包括 Nvidia 首席科学家、曾领导斯坦福大学计算机科学系的 Bill Dally 在内的作者指出。
“BaM 在 GPU 内存中提供了一个高并发 NVMe 提交/完成队列的用户级库,使按需访问未从软件缓存中丢失的 GPU 线程能够以高吞吐量方式进行存储访问,”他们继续说道。“这种用户级方法对每次存储访问产生的软件开销很小,并且支持高度的线程级并行性。”
该团队计划将他们的硬件和软件优化的细节开源给其他人来构建这样的系统。我们想起了 AMD 的 Radeon Solid State Graphics (SSG) 卡,它将闪存放置在 GPU 旁边。
