微控制器在边缘人工智能中的重要性越来越大
就在几年前,人们还认为机器学习(ML)甚至深度学习(DL)只能在高端硬件上执行,在边缘侧需要通过网关、边缘服务器或数据中心执行训练和推理,这在当时是一个主流观念,因为在云和边缘之间研究如何分配计算资源还处于早期阶段。但由于工业界和学术界的深入研究和开发努力,这种情况已经发生了巨大的变化。
如今,最新的微控制器(其中一些带有嵌入式ML加速器)可以将ML带到边缘设备中,性能也很强大,已经可以达到数TOPS了。
这些设备不仅可以执行ML,而且还可以以低成本、低功耗、仅在绝对必要时才连接到云端的特性。简言之,集成了ML加速器的微控制器代表了下一步,将计算应用到麦克风、摄像头和监控环境条件的传感器上,这些传感器产生的数据将在模块中就实现数据处理,从而给物联网带来额外好处。
边缘有多远?
虽然边缘被广泛认为是物联网网络中最远的点,但它通常被认为是高级网关或边缘服务器。这并不是边缘真正结束的地方,它将在用户侧附近的传感器端结束。把尽可能多的分析能力放在用户端是合乎逻辑的,微控制器最适合这项任务。
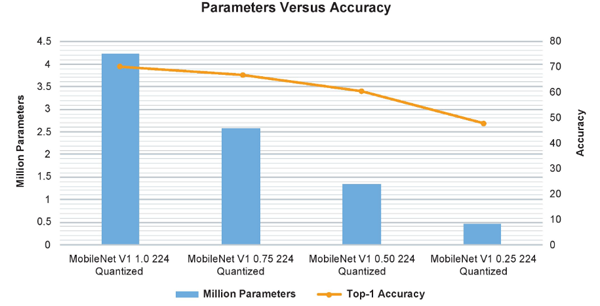
MobileNet V1模型的变宽乘法器示例显示了对参数数量、计算和精度的巨大影响。仅将宽度乘数从1.0更改为0.75,只会最小程度地影响TOP-1精度,但会显著影响参数和计算的数量(Image:NXP)
单板计算机也可以用于边缘处理,因为单板计算机具有卓越的性能,并且在集群中可以与小型超级计算机相媲美。但它们仍然太大,成本太高,无法部署到大规模应用程序所需的成百上千个单元中。此外,它们还需要一个外部直流电源,在某些情况下可能超出可用的范围,而MCU只消耗毫瓦级功率,可以由纽扣电池甚至几块太阳能电池供电。
因此,对于在边缘执行ML的微控制器已经成为一个非常热门的话题,这一点也不奇怪。它甚至还有一个名字——TinyML。TinyML的目标是允许在资源受限的小型低功耗设备(尤其是微控制器)上执行推断和最终训练,而不是在更大的平台或云中。这就需要减小神经网络模型的规模,以适应这些设备的相对适度的处理、存储和带宽资源,但是也不会显著降低功能和准确性。
这些资源优化方案允许设备摄取足够的传感器数据以满足其应用,同时可以微调精度并减少资源需求。因此,虽然数据可能仍被发送到云(或者可能先发送到边缘网关,然后再发送到云),但是由于已经进行了大量的分析,因此数据量将少得多。
TinyML的一个常见例子是基于摄像头的目标检测系统,虽然能够捕捉高分辨率图像,但存储空间有限,需要降低图像分辨率。但是,如果相机包含设备上的分析,则只捕获感兴趣的对象而不是整个场景,并且由于相关图像较少,因此可以保留其较高的分辨率。这种功能以往只能在更大、更强大的设备上执行,但微TinyML技术允许它在微控制器上实现。
小而有力
尽管TinyML是一个相对较新的范例,但它已经在以最小的精度损失进行推断(即使是相对较小的微控制器)和训练(在更强大的微控制器上)方面产生了令人惊讶的结果。最近的例子包括语音和面部识别、语音命令和自然语言处理,甚至并行运行几种复杂的视觉算法。
实际上,这意味着一个成本不到2美元的微控制器,配备500MHz的Arm Cortex-M7内核,内存从28kb到128kb,可以提供使传感器真正智能化所需的性能。
即使在这样的价格和性能水平上,这些微控制器也有多种安全功能,包括AES-128,支持多种外部存储器、以太网、USB和SPI,并且包括或支持各种类型的传感器,以及蓝牙、Wi-Fi、SPDIF和I2C音频接口。再多花一点钱,这个设备通常会有一个1GHz的Arm Cortex-M7、400MHz的Cortex-M4、2MB的RAM和图形加速。3.3伏直流电源的功耗通常不超过几毫安。
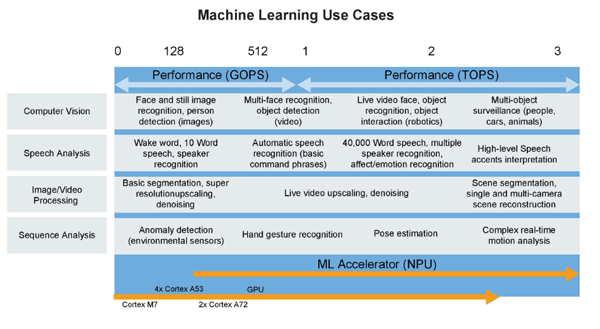
机器学习用例(图片:NXP)
关于TOPS的几句絮叨
消费者喜欢使用单一的指标来定义性能,开发者也总是这样做,营销部门也很喜欢。这是因为规范使设备之间的区别变得简单,或者看起来似乎如此。一个典型的例子是CPU,多年来它是由时钟频率来定义性能的。幸运的是,如今无论是开发者还是消费者,情况已不再如此。仅仅用一个指标来评价一个CPU就相当于用发动机的红线来评价汽车的性能。这并非毫无意义,但与发动机的功率或汽车的性能没有多大关系,因为许多其他因素共同决定了这些特性。
不幸的是,对于神经网络加速器,包括那些在高性能微处理器或微控制器中的加速器来说,情况也越来越严重,因为这是一个很容易记住的数字,因为它是每秒数十亿或万亿次的运算。但在实践中,GOPS和TOPS本身是相对无意义的度量,它们代表的只是在实验室中进行的度量(无疑是最好的度量),而不是表示实际的操作环境。例如,TOPS不考虑内存带宽的限制、所需的CPU开销、前后处理以及其他因素。当考虑到所有这些和其他因素时,例如实际操作中,特定板卡使用时的性能,系统级性能可能是数据表中最高值的50%或60%。
所有这些数字告诉你的是硬件中计算元素的数量乘以它们的时钟速度,而不是当它需要工作时它有多少可用的资源。如果数据总是立即可用,功耗不是问题,内存限制不存在,并且算法无缝地映射到硬件上,它们将更有意义。但现实世界没有这样理想的环境。
尤其是到了微控制器的ML加速器时,该指标的价值甚至更低。这些微型设备的值通常为1到3个TOPS,但仍然可以提供许多ML应用程序所需的推理功能。这些设备还依赖于专门为低功耗ML应用设计的Arm Cortex处理器。随着对整型和浮点运算的支持以及微控制器中的许多其他特性的支持,TOPS或任何其他单一的度量标准都无法单独或在系统中充分定义性能。
结论
随着物联网领域向尽可能多地在边缘执行处理越来越近,直接在传感器上或与传感器相连的微控制器上执行推断的愿望正在出现。也就是说,微控制器中应用处理器和神经网络加速器的发展速度很快,而且越来越熟练的解决方案不断出现。趋势是在不显著增加功耗或体积的情况下,将更多以人工智能为中心的功能(如神经网络处理)与微控制器中的应用处理器结合起来。
如今,模型可以在更强大的CPU或GPU上训练,然后使用TensorFlow-Lite等推理引擎在微控制器上实现,以减小模型的大小,满足微控制器的资源需求。缩放可以很容易地执行,以适应更大的ML要求。很快,在这些设备上不仅可以进行推断,还可以进行训练,这将有效地使微控制器成为更大、更昂贵的计算解决方案的竞争对手。
本文作者:NXP人工智能和机器学习技术主管Markus Levy
